Downloaded 10 times












![Let’s extend Article by creating a one-to-many-relationship to Comment
The array of comments is non-nullable, so we can always expect an array.
And with Comment! we require that
every item of the array (if any) has to be a non-nullable valid Comment object.
type Article {
id: ID!
title: String!
url: String!
comments: [Comment!]!
}](https://image.slidesharecdn.com/ferret-graphql-talk-2-200529155108/85/Let-s-start-GraphQL-structure-behavior-and-architecture-14-320.jpg)




![Let’s define our first Query allArticles that returns list of Articles
type Query {
allArticles: [Article!]!
}
The result will be an array containing zero or more instances of Article
Note, that query definition does not limit which fields to return
and client can receive whatever it is actually needed.](https://image.slidesharecdn.com/ferret-graphql-talk-2-200529155108/85/Let-s-start-GraphQL-structure-behavior-and-architecture-19-320.jpg)

![Queries can have arguments
type Query {
allArticles(N: Int): [Article!]!
}
We indicate that N is an optional parameter by omitting ! after its type’s name.
… and then client can query for 2 articles with
query {
allArticles(N: 2) {
id
title
}
}](https://image.slidesharecdn.com/ferret-graphql-talk-2-200529155108/85/Let-s-start-GraphQL-structure-behavior-and-architecture-21-320.jpg)





![{
"__type": {
"name": "Article",
"fields": [
{
"name": "id",
"type": {
"kind": "NON_NULL",
"ofType": { "name": "ID", "kind": "SCALAR" }
}
},
{
"name": "title",
"type": {
"kind": "NON_NULL",
"ofType": { "name": "String", "kind": "SCALAR" }
}
},
...
]
}
}
… and the response contains the specification of the type:](https://image.slidesharecdn.com/ferret-graphql-talk-2-200529155108/85/Let-s-start-GraphQL-structure-behavior-and-architecture-27-320.jpg)


















![class Article(graphene.ObjectType):
id = graphene.ID(required=True)
title = graphene.String(required=True)
url = graphene.String(required=True)
comments = graphene.NonNull(graphene.List(graphene.NonNull(Comment)))
Let’s convert our schema into Python with graphene
type Article {
id: ID!
title: String!
url: String!
comments: [Comment!]!
}](https://image.slidesharecdn.com/ferret-graphql-talk-2-200529155108/85/Let-s-start-GraphQL-structure-behavior-and-architecture-47-320.jpg)
![class Comment(graphene.ObjectType):
id = graphene.ID(required=True)
text = graphene.String(required=True)
createdAt = graphene.DateTime(required=True)
moderationStatus = graphene.Enum(
"Status", [("APPROVED", "approved"), ("REJECTED", "rejected"), ("PENDING", "pending")]
)
moderationNote = graphene.String(required=False)
article = graphene.NonNull(graphene.Field(Article))
Let’s convert our schema into Python with graphene
type Comment {
id: ID!
text: String!
createdAt: DateTime!
moderationStatus: Status!
moderatorNote: String
article: Article!
}
enum Status {
APPROVED
REJECTED
PENDING
}](https://image.slidesharecdn.com/ferret-graphql-talk-2-200529155108/85/Let-s-start-GraphQL-structure-behavior-and-architecture-48-320.jpg)
![class Query(graphene.ObjectType):
allArticles = graphene.NonNull(graphene.List(Article), N=graphene.Int())
… and the query
type Query {
allArticles(N: Int): [Article!]!
}
At the end, everything is wrapped in a Schema:
schema = graphene.Schema(query=Query)](https://image.slidesharecdn.com/ferret-graphql-talk-2-200529155108/85/Let-s-start-GraphQL-structure-behavior-and-architecture-49-320.jpg)
![Fetching Data
Only one endpoint has to be exposed.
from django.conf.urls import url
from graphene_django.views import GraphQLView
from myapp.schema import schema
urlpatterns = [
url(r'^graphql$', GraphQLView.as_view(graphiql=True, schema=schema)),
]
Parameter graphiql=True will enable built-in GraphiQL plugin
For instance, using Django we can simply register
our /graphql endpoint with Graphene-Django:](https://image.slidesharecdn.com/ferret-graphql-talk-2-200529155108/85/Let-s-start-GraphQL-structure-behavior-and-architecture-50-320.jpg)

![… and the query
class Query(graphene.ObjectType):
allArticles = graphene.NonNull(graphene.List(Article, N=graphene.Int()))
def resolve_allArticles(self, info, N):
articles = DjangoArticle.objects.all()
if N is not None:
articles = articles[:N]
return articles
In graphene, resolvers are named as resolve_ following be the field’s name](https://image.slidesharecdn.com/ferret-graphql-talk-2-200529155108/85/Let-s-start-GraphQL-structure-behavior-and-architecture-52-320.jpg)
![With Graphene-Django it is even easier:
from graphene_django import DjangoObjectType
class Article(DjangoObjectType):
class Meta:
model = DjangoArticle
class Query(graphene.ObjectType):
allArticles = graphene.NonNull(graphene.List(Article), N=graphene.Int())
def resolve_allArticles(self, info, N=None):
articles = DjangoArticle.objects.all()
if N is not None:
articles = articles[:N]
return articles
We do not need to write resolvers for each field in the model.](https://image.slidesharecdn.com/ferret-graphql-talk-2-200529155108/85/Let-s-start-GraphQL-structure-behavior-and-architecture-53-320.jpg)




![Input types
Read more about how to use Input types in mutations:
http://docs.graphene-python.org/en/latest/types/mutations/
class ModerationInput(graphene.InputObjectType):
moderationStatus = graphene.Enum(
"Status", [("APPROVED", "approved"), ("REJECTED", "rejected"), ("PENDING", "pending")]
)
moderationNote = graphene.String(required=False)
class ModerateComment(graphene.Mutation):
class Arguments:
decision = ModerationInput(required=True)
...](https://image.slidesharecdn.com/ferret-graphql-talk-2-200529155108/85/Let-s-start-GraphQL-structure-behavior-and-architecture-59-320.jpg)






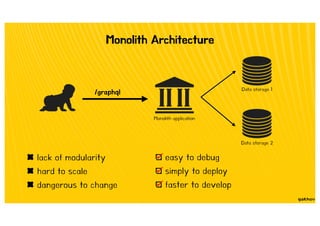
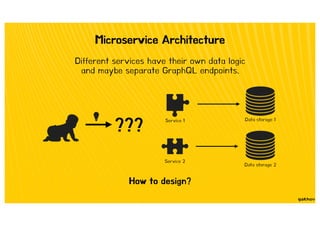
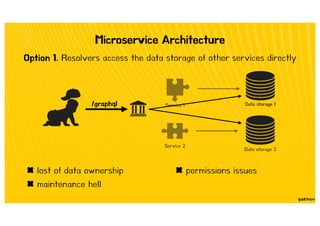
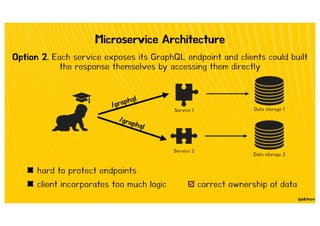
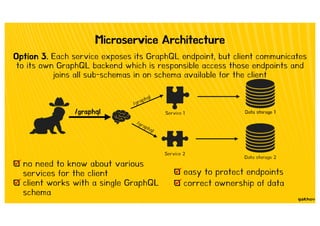





![Type Extension
It is possible to extend types from other services
Comments service assigns users to each comment,
but the User service does not need to know about Comments:
type User @key(fields: "id") {
id: ID!
username: String!
}
As an example, consider a User service that has defined User type:
type User @key(fields: "id") {
id: ID! @external
comments: [Comment!]
}
type Comment @key(fields: "id") {
user: User!
...
}](https://image.slidesharecdn.com/ferret-graphql-talk-2-200529155108/85/Let-s-start-GraphQL-structure-behavior-and-architecture-76-320.jpg)
![Apollo Gateway
const { ApolloGateway } = require("@apollo/gateway");
const gateway = new ApolloGateway({
serviceList: [
{ name: "articles", url: "https://articles.example.com/graphql" },
{ name: "users", url: "https://users.example.com/graphql" },
{ name: "comments", url: "https://comments.example.com/graphql" }
]
});
Within gateway we register all federated services.
Such a gateway composes the complete graph and, once requested,
executes the federated queries.](https://image.slidesharecdn.com/ferret-graphql-talk-2-200529155108/85/Let-s-start-GraphQL-structure-behavior-and-architecture-77-320.jpg)




![import graphene
from graphene_federation import build_schema, key
from myapp.models import User as DjangoUser
@key(fields="id"):
class User(graphene.ObjectType):
id = graphene.ID(required=True)
username = graphene.String(required=True)
def __resolve_reference(self, info, **kwargs):
return DjangoUser.objects.get(id=self.id)
}
schema = build_schema(types=[User])
Let’s develop the previous example and design a User service in Python](https://image.slidesharecdn.com/ferret-graphql-talk-2-200529155108/85/Let-s-start-GraphQL-structure-behavior-and-architecture-82-320.jpg)





![Fault tolerance notes
{
"data": {
"allArticles": [
{
"id": "1",
"title": "My article",
"comments": [
{
"id": "1",
"text": "Nice article",
}
}
]
}
{
"data": {
"allArticles": [
{
"id": "1",
"title": "My article",
"comments": null
}
]
}
service Comment is up service Comment is down](https://image.slidesharecdn.com/ferret-graphql-talk-2-200529155108/85/Let-s-start-GraphQL-structure-behavior-and-architecture-88-320.jpg)



The document provides a comprehensive overview of GraphQL, including its structure, behavior, and architectural considerations. It details key concepts such as schemas, queries, mutations, subscriptions, and resolvers, illustrating how they enable efficient data retrieval and manipulation. The document also compares GraphQL to REST and discusses implementation with Python's Graphene library, including managing data from different sources and building a federated architecture.

















































































