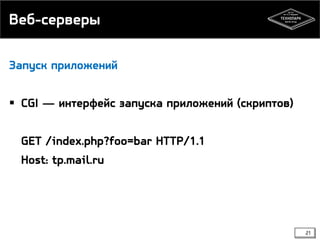
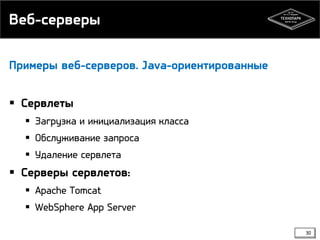
Документ обсуждает компоненты веб-систем и схемы их взаимодействия, включая клиент-сервер и peer-to-peer. Он охватывает ключевые аспекты, такие как преимущества и недостатки каждой схемы взаимодействия, основные компоненты веб-систем, включая веб-серверы и базы данных, а также функции систем управления базами данных (СУБД). Также рассматриваются принципы асинхронной работы и репликации данных.