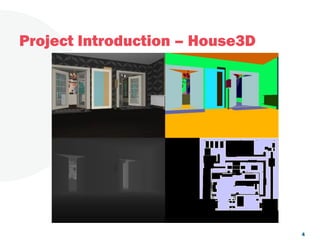
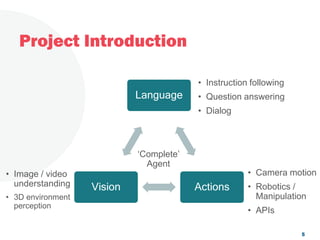
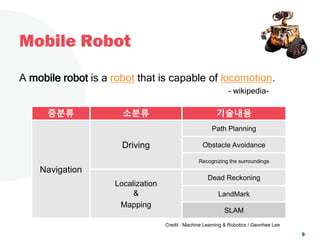
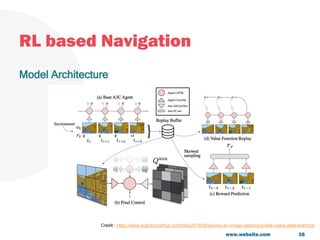
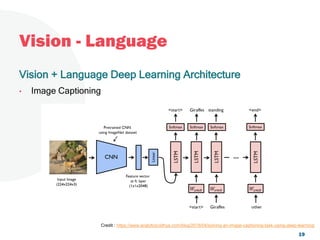
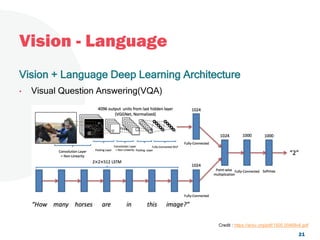
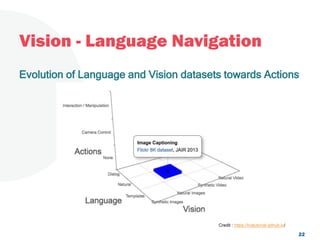
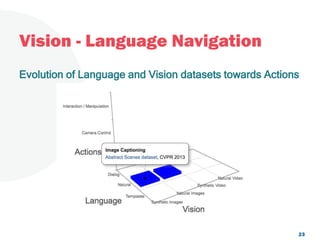
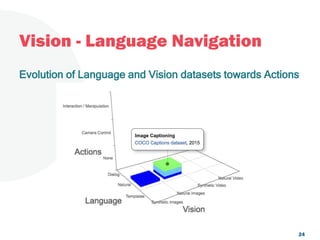
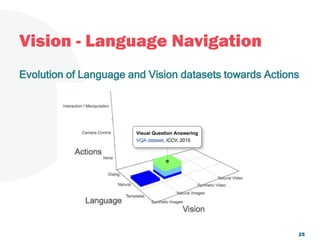
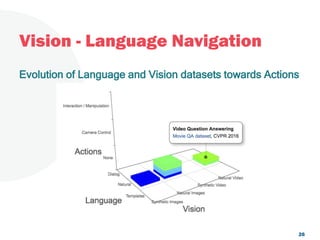
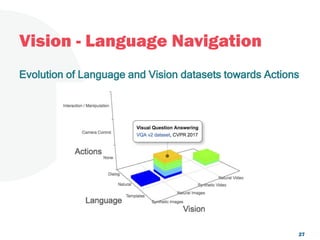
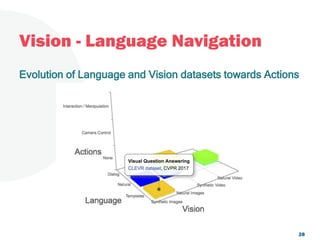
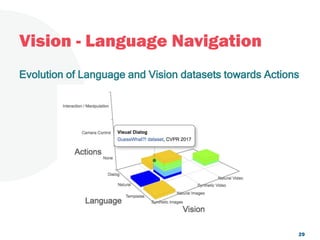
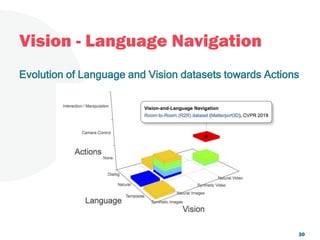
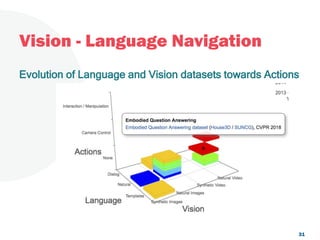
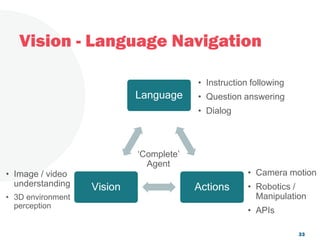
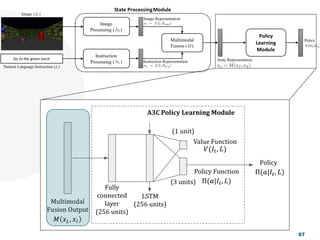
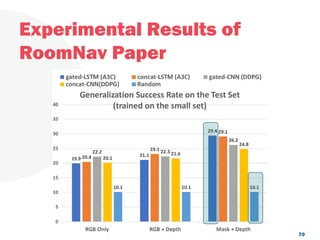
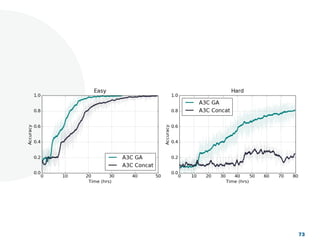
The document discusses a project focused on 3D environment navigation using reinforcement learning for mobile robots, specifically targeting tasks such as moving to specified locations within a house. It highlights various methodologies, models, and datasets relevant to vision-language navigation and presents motivation for developing a target-driven visual navigation system. Additionally, it outlines the use of specific datasets for training models in indoor navigation and the challenges faced in adapting learned behaviors to different environments.






























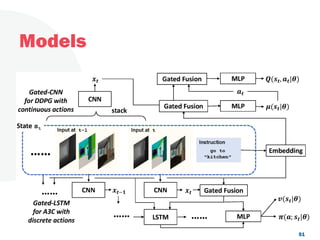
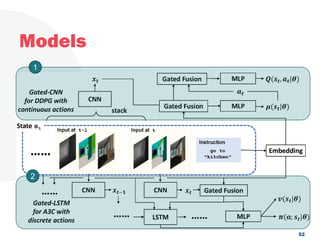
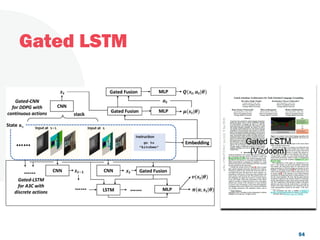
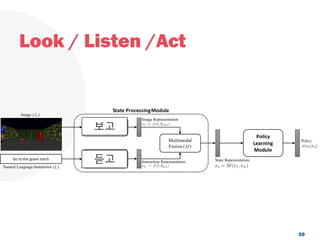
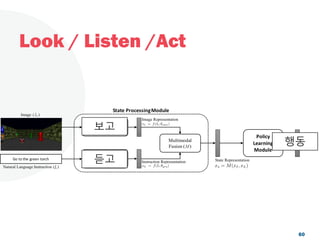
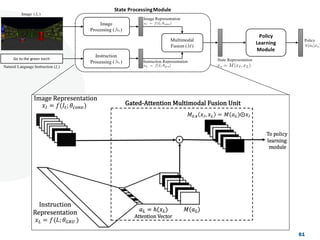
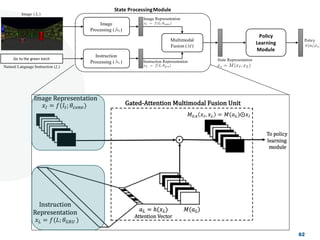
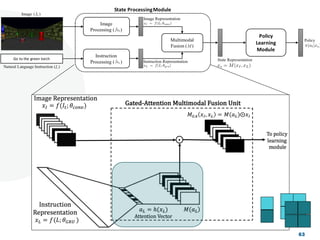
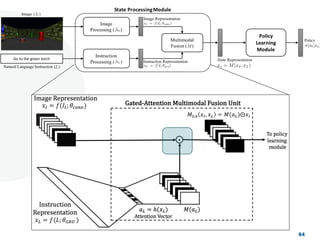
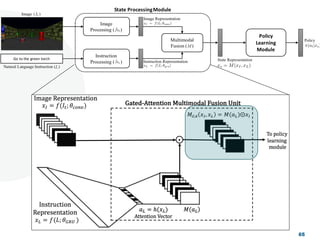
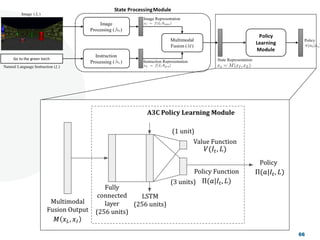














![Look, Listen and Act [Navigation via Reinforcement Learning]](https://cdn.slidesharecdn.com/ss_thumbnails/homenavi-181119150300-thumbnail.jpg?width=640&height=640&fit=bounds)


















































