

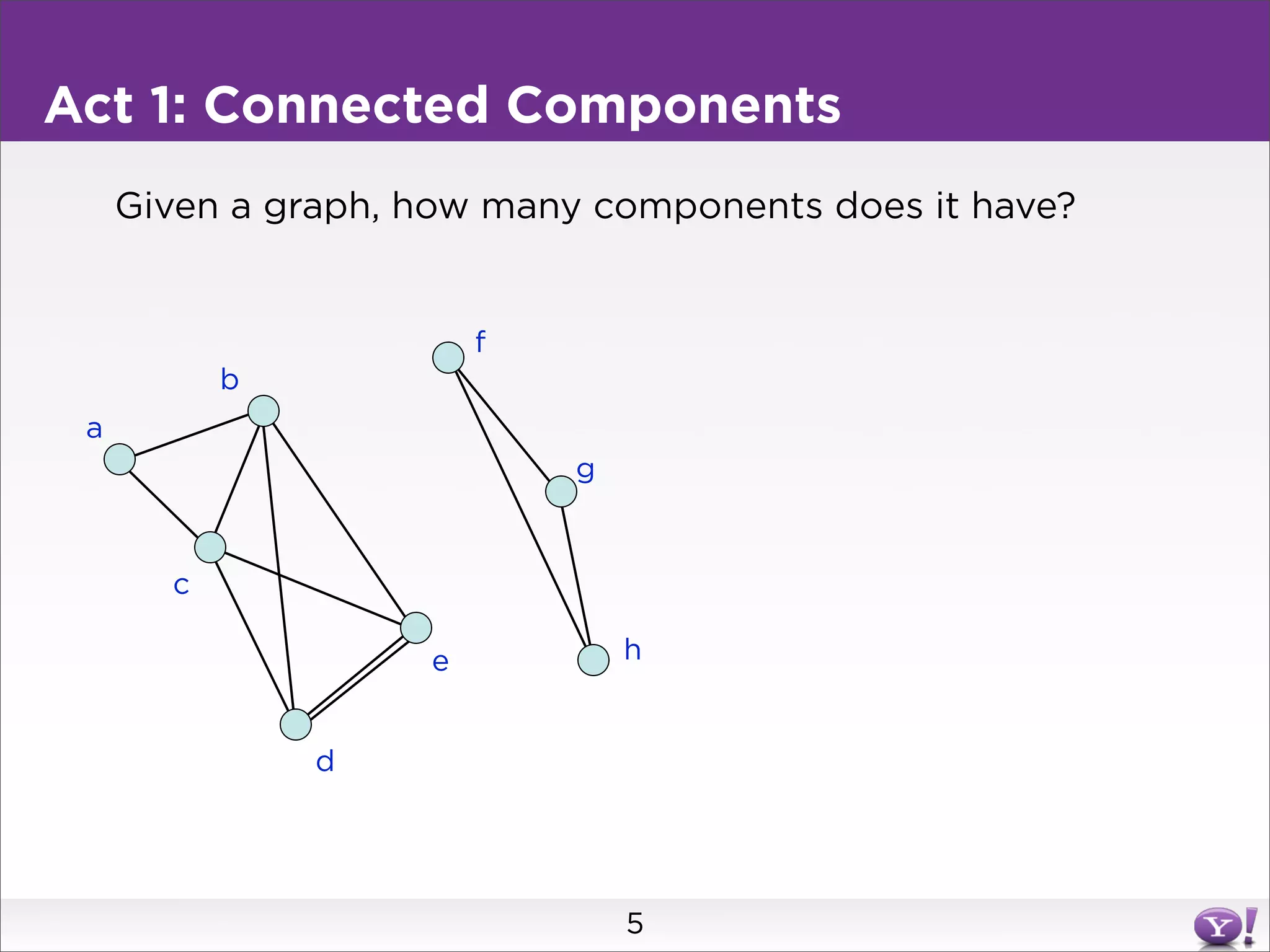
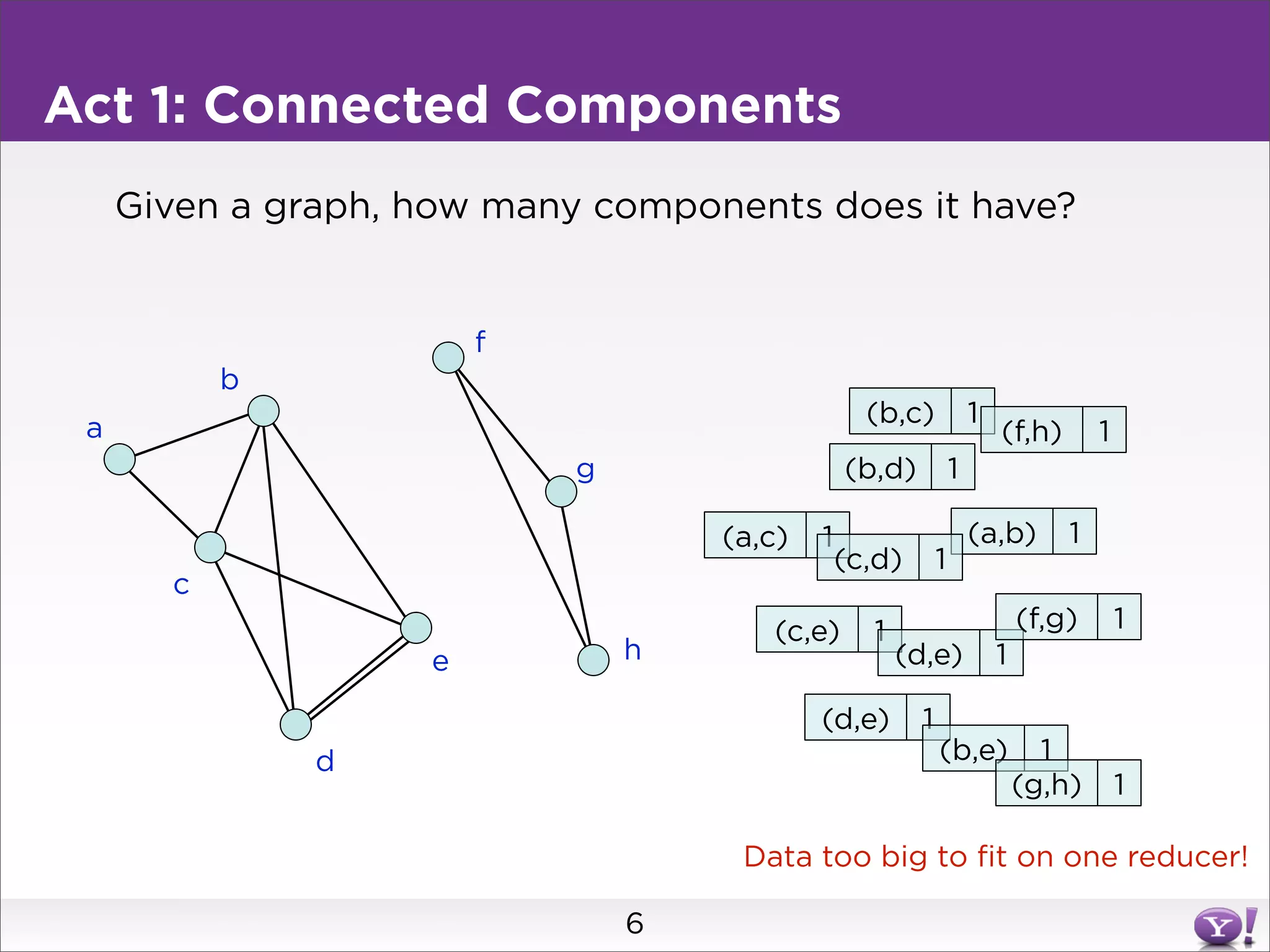
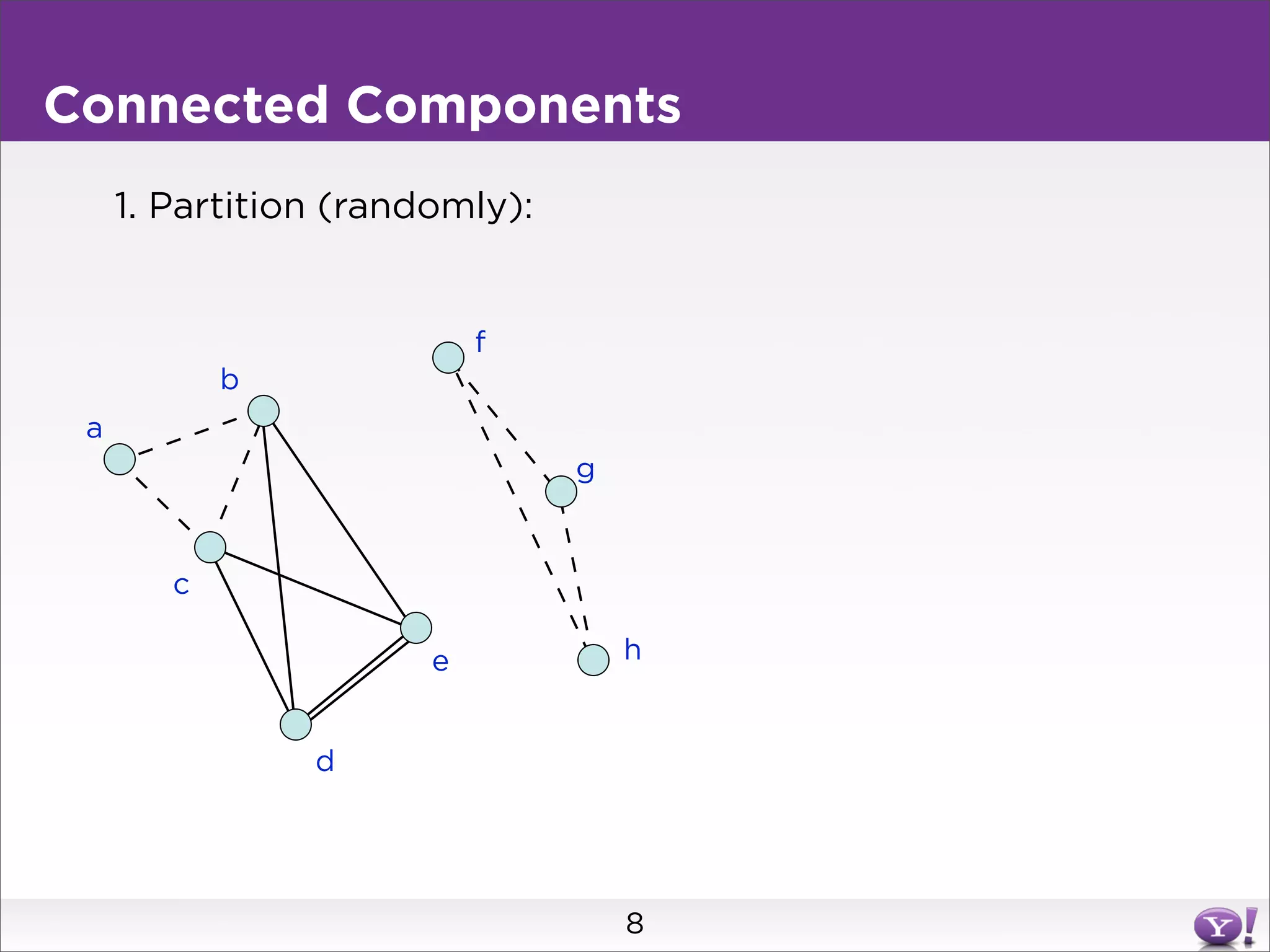
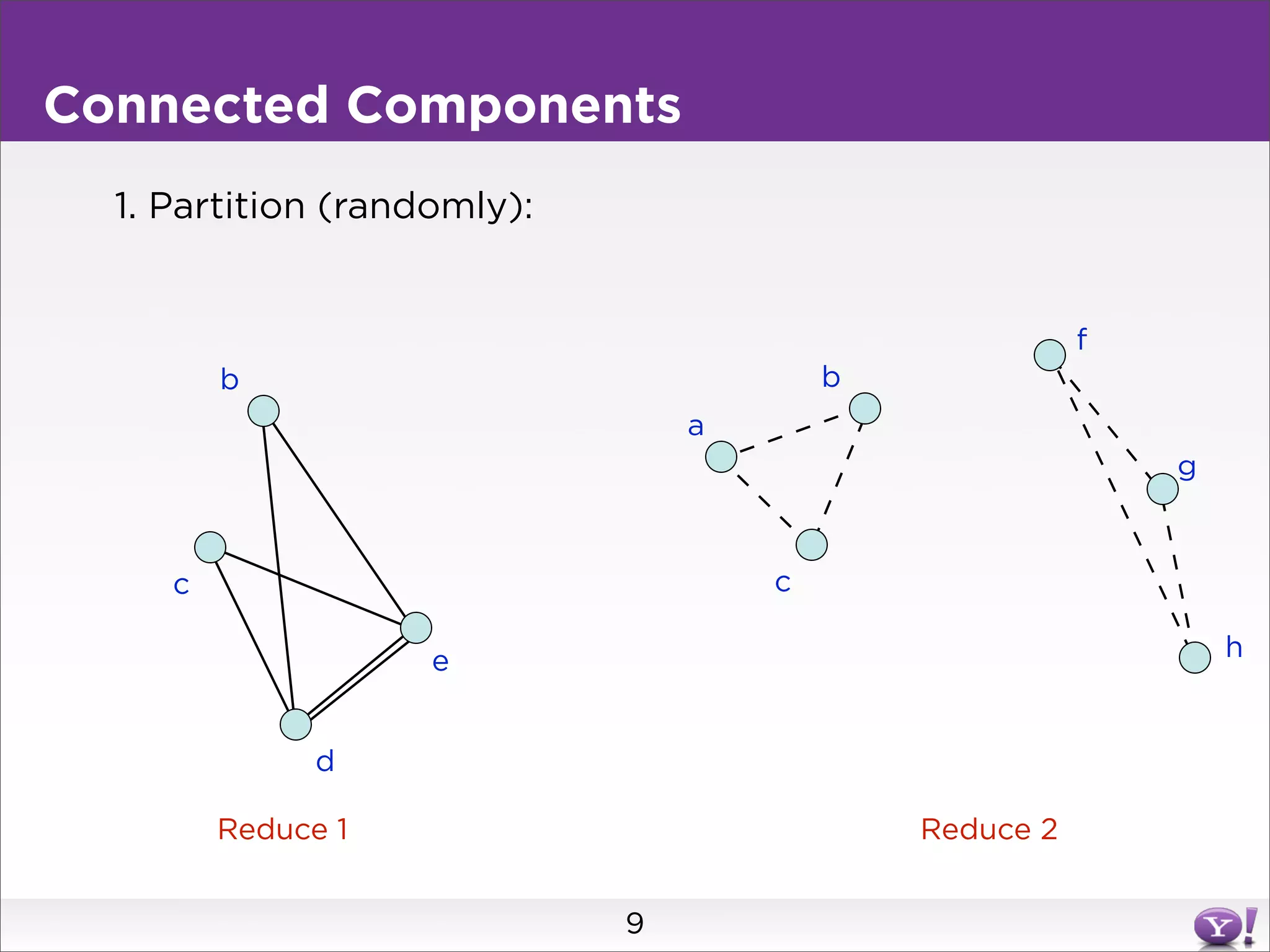
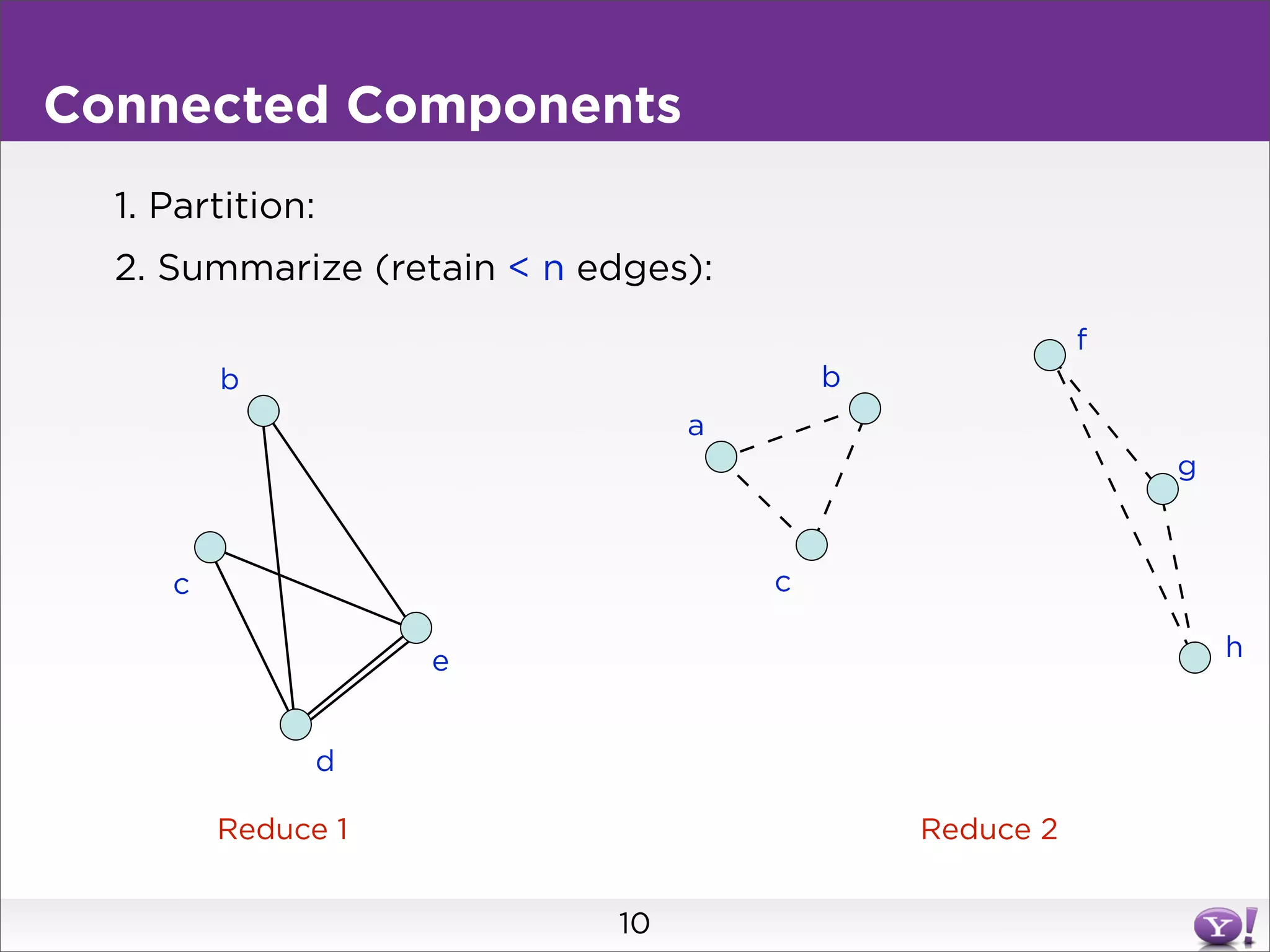
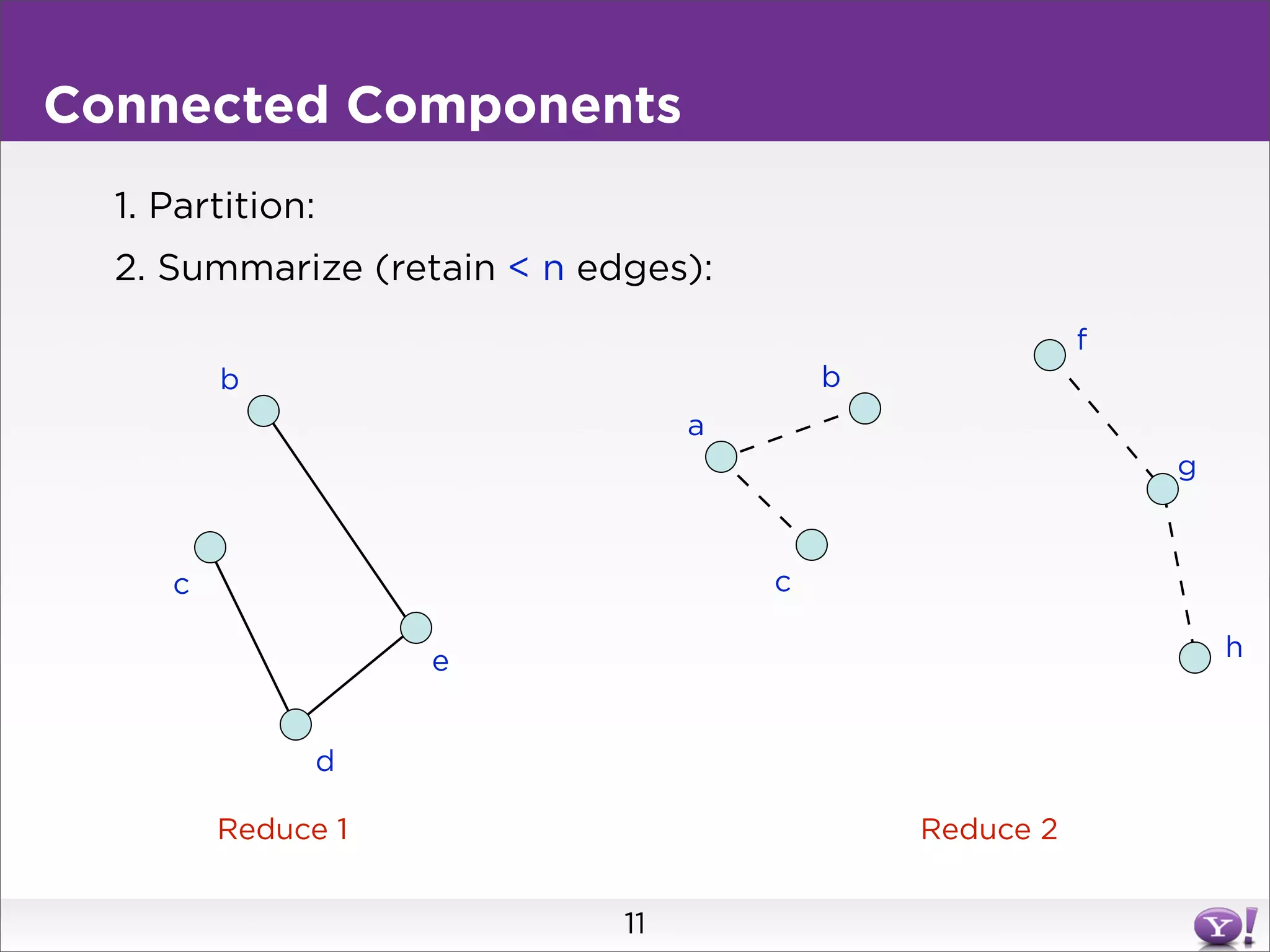
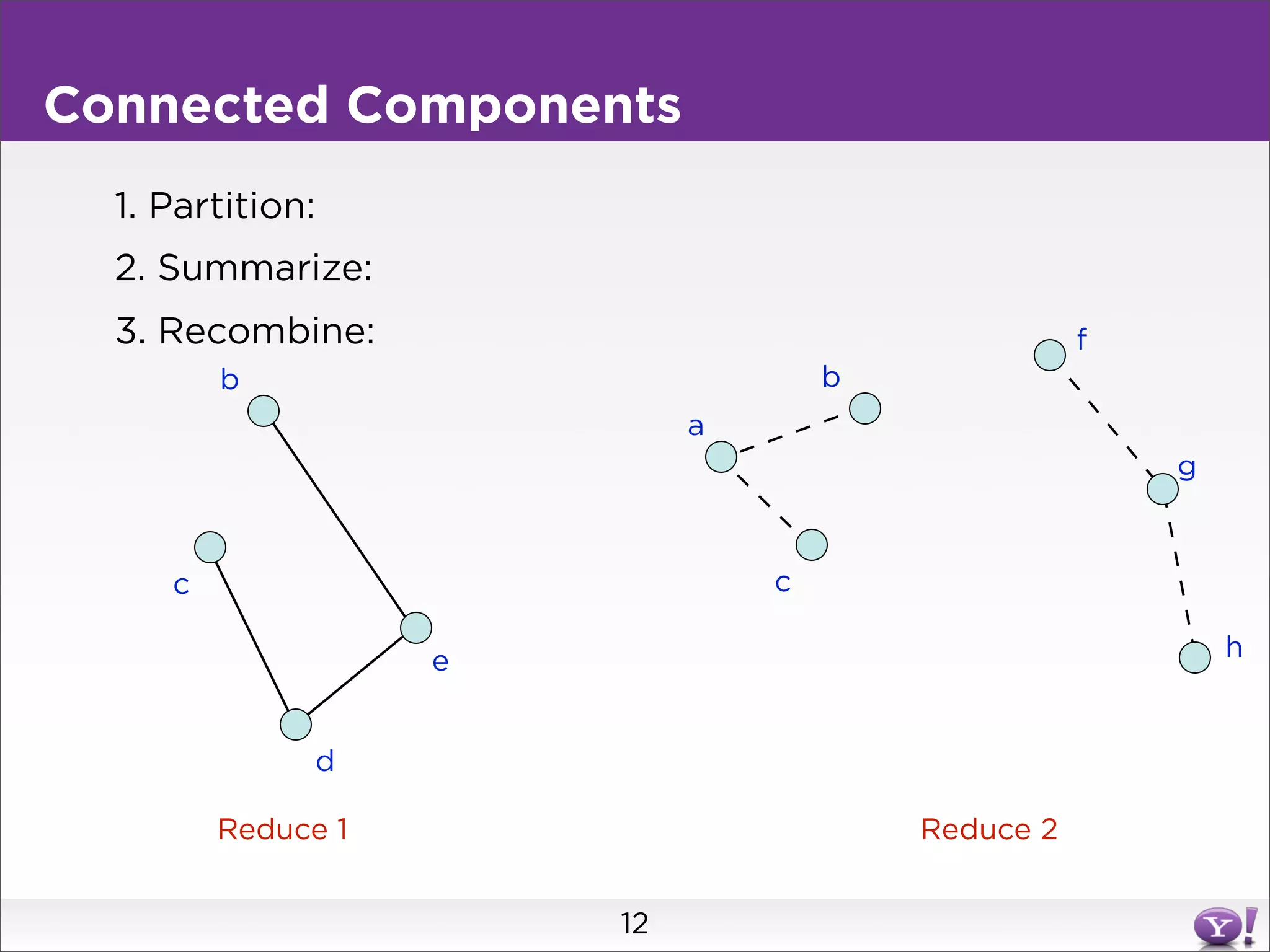
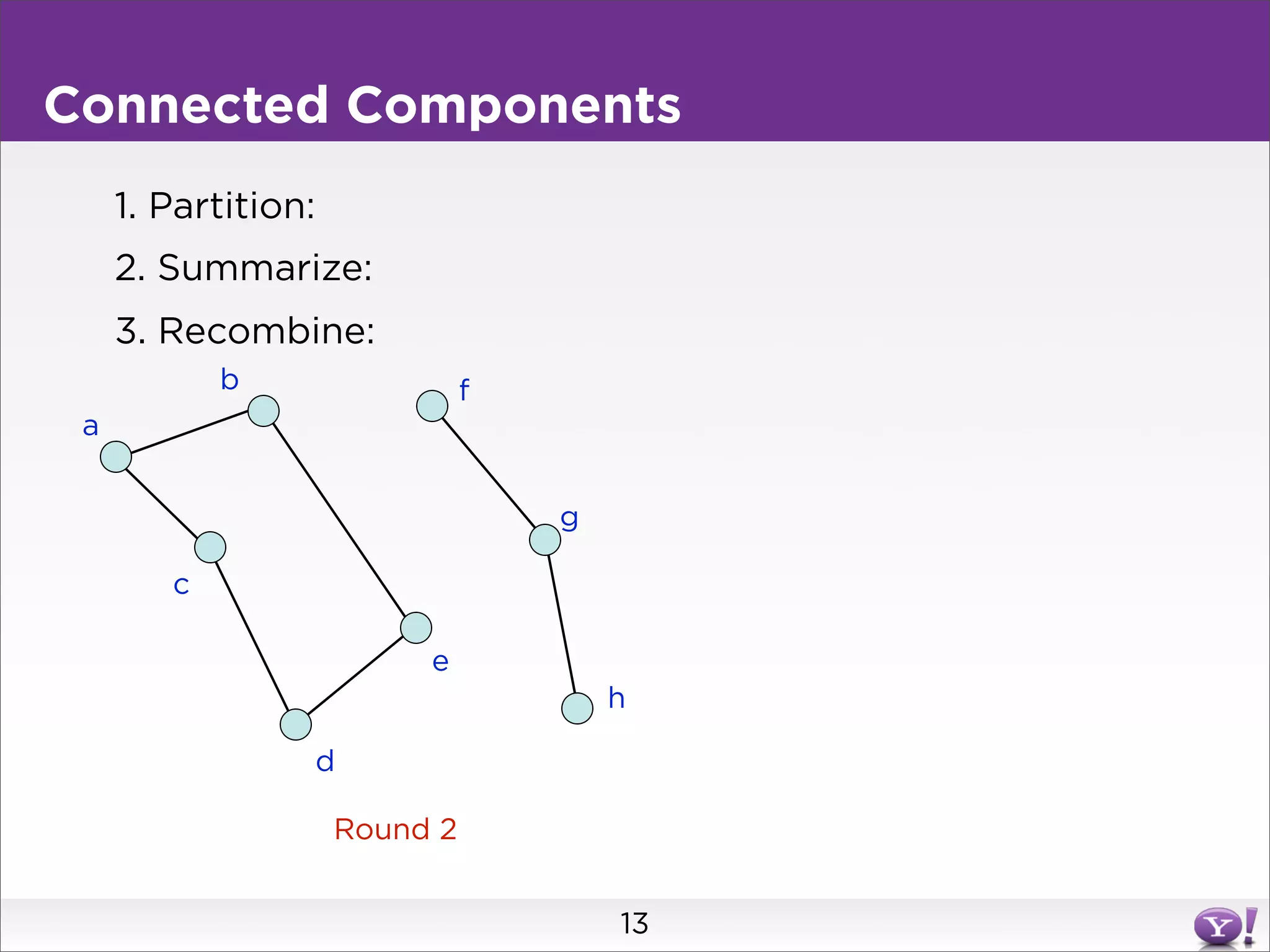
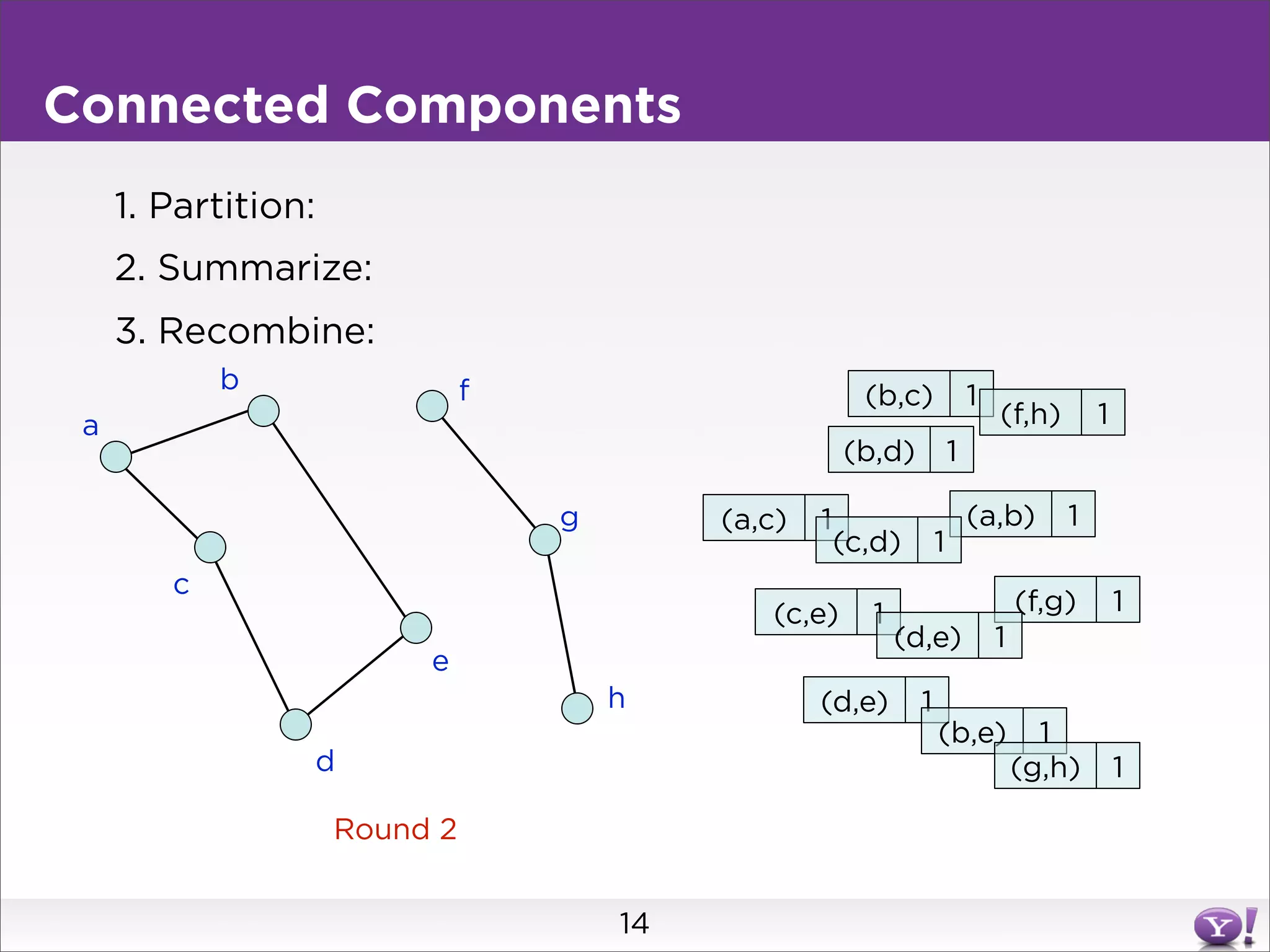
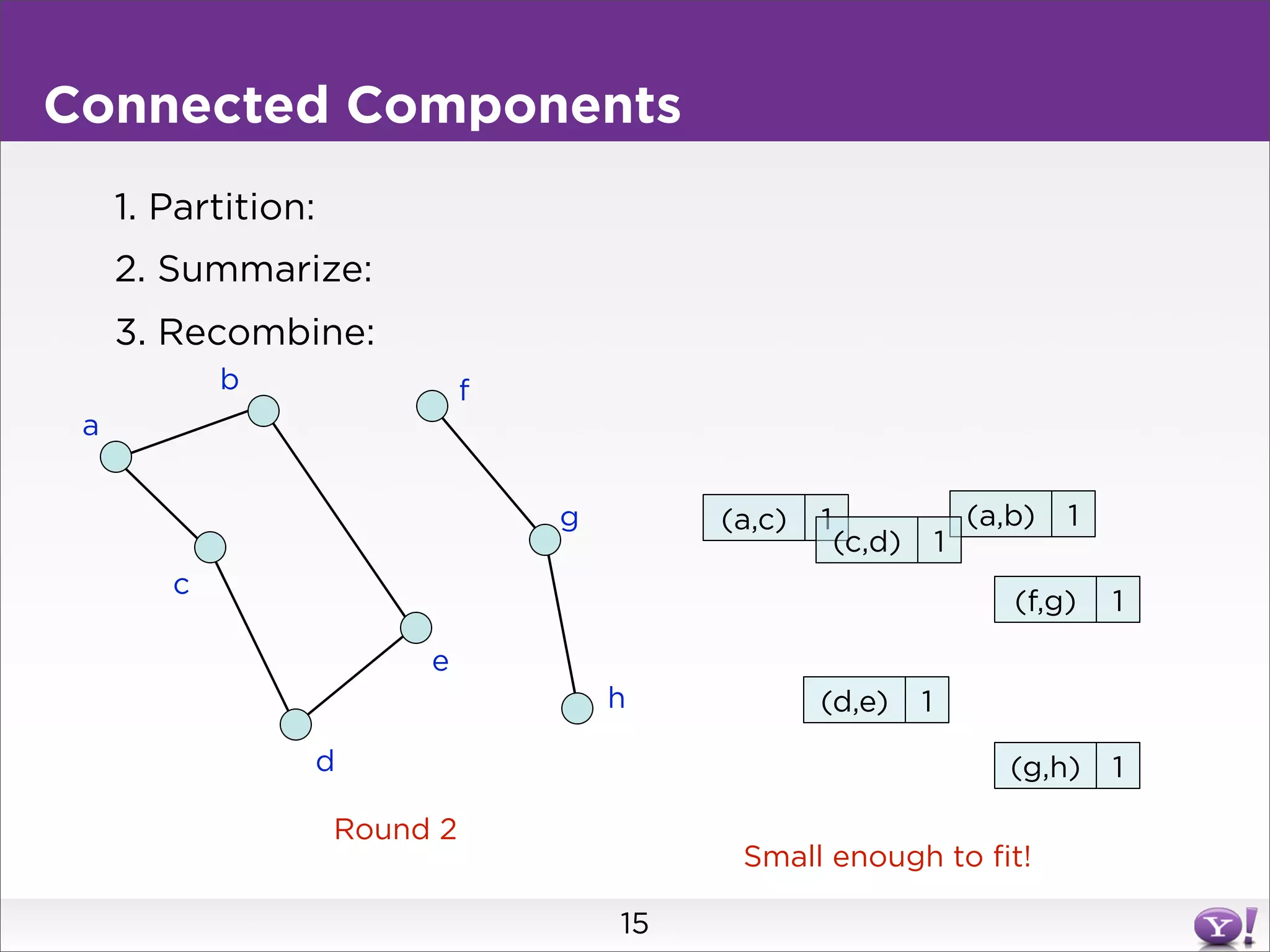




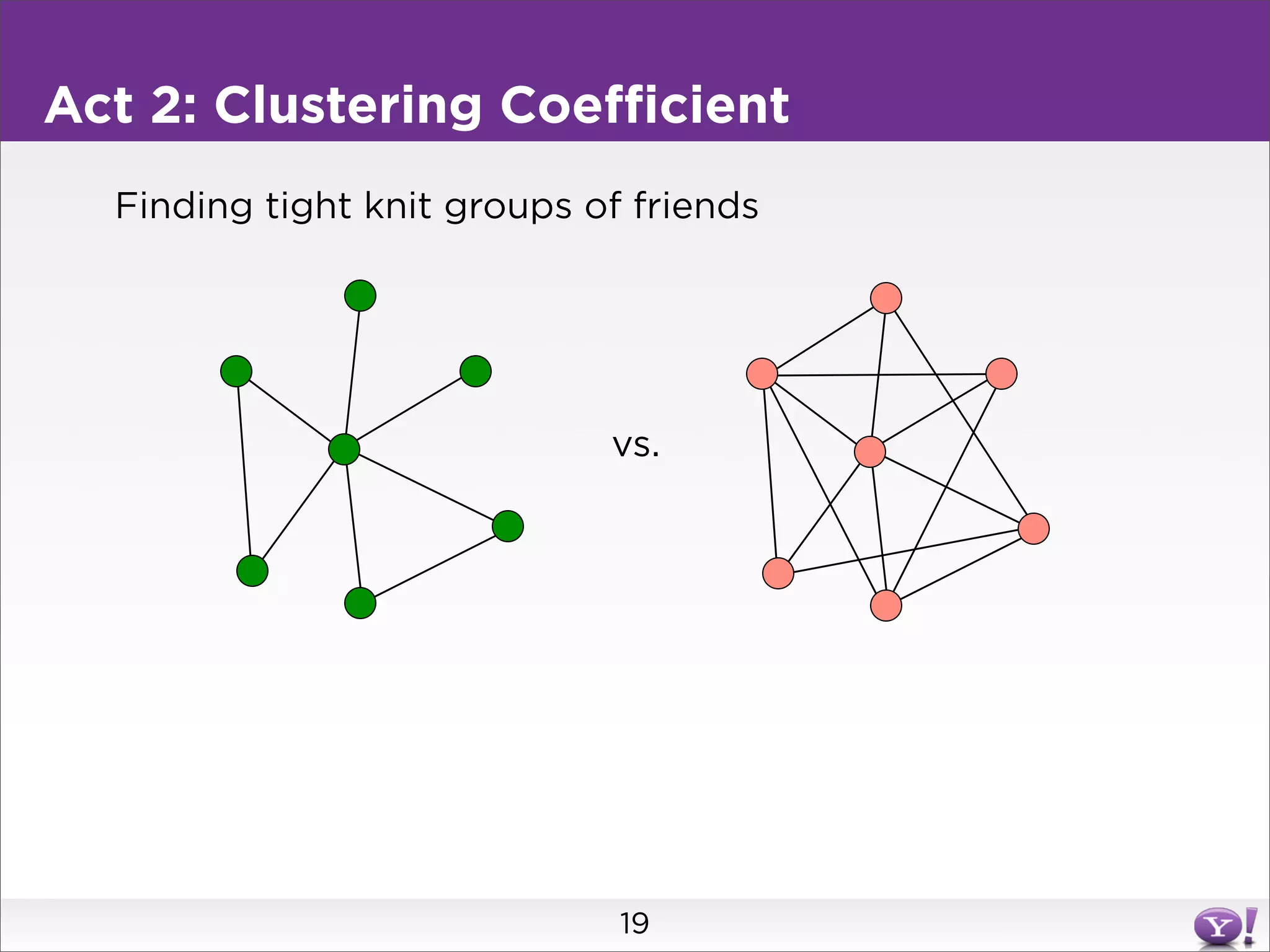
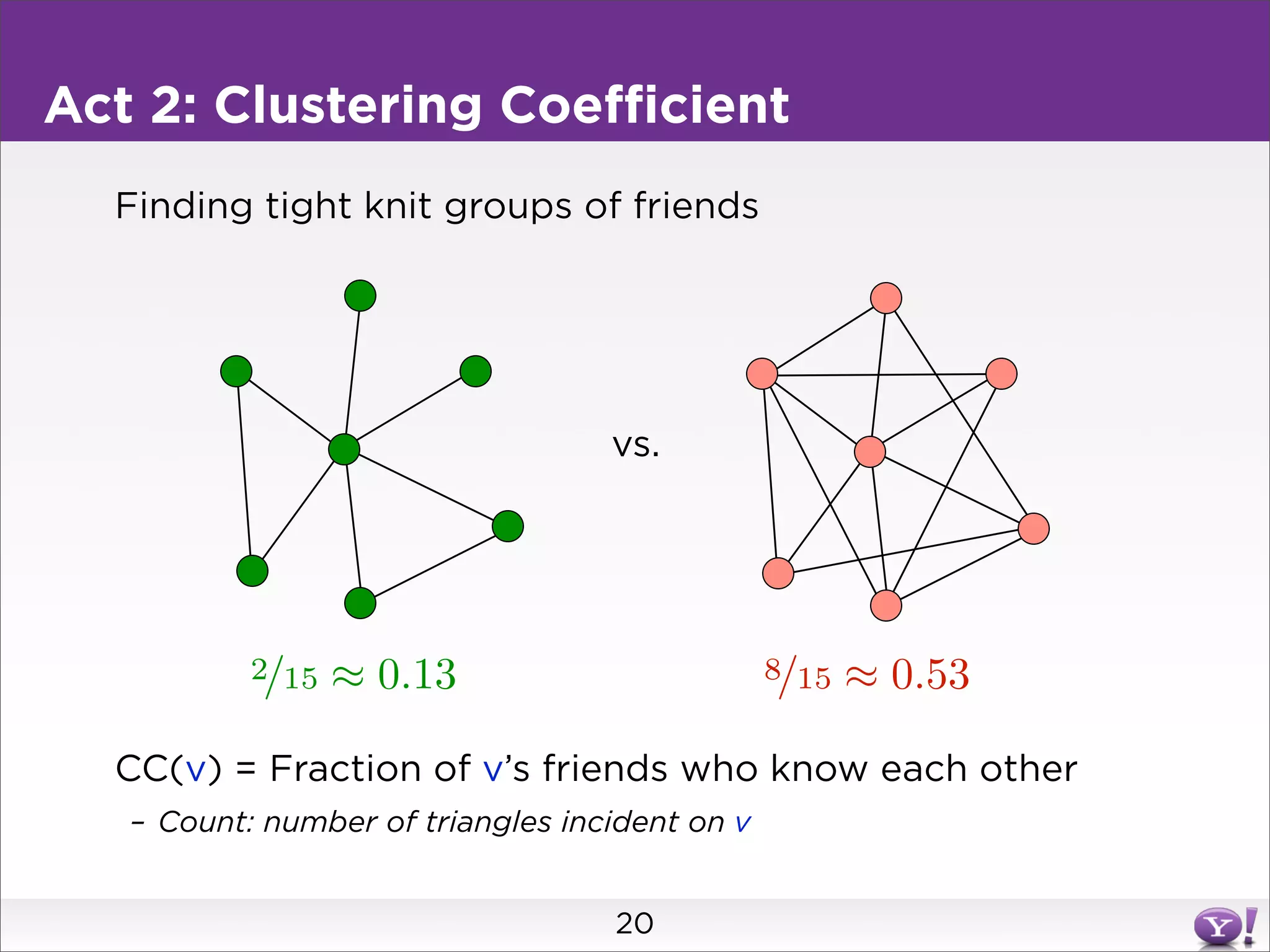
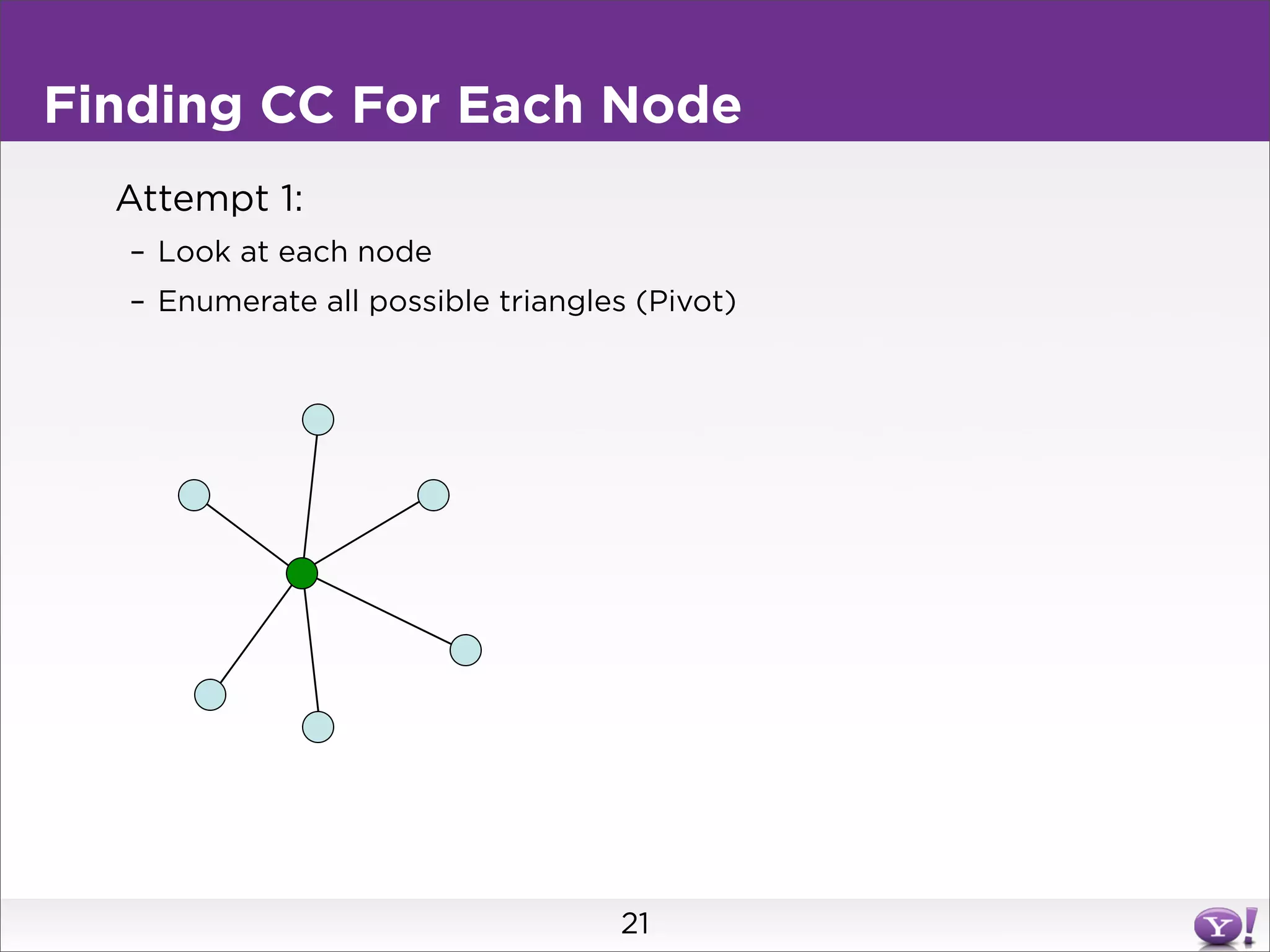
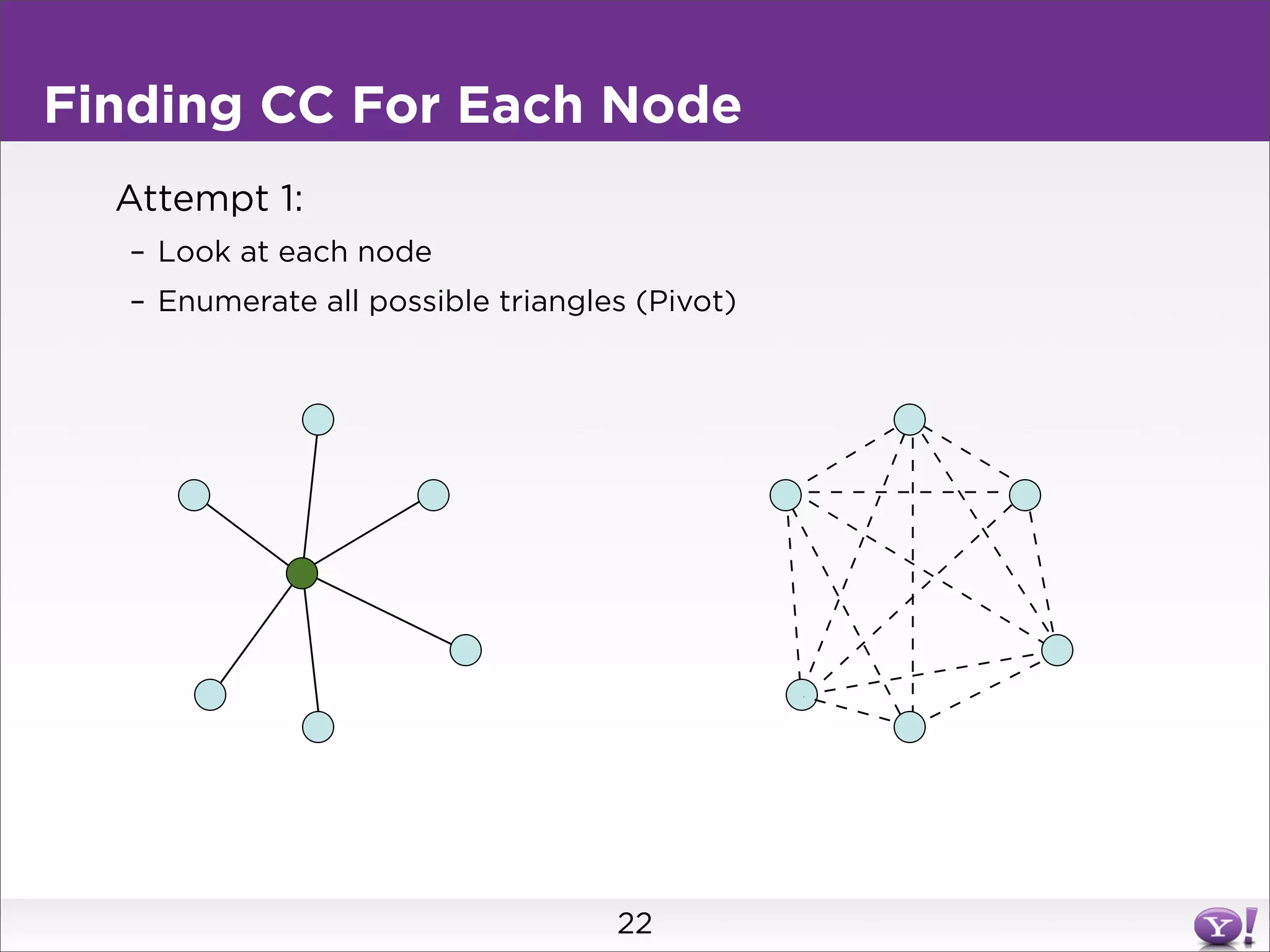
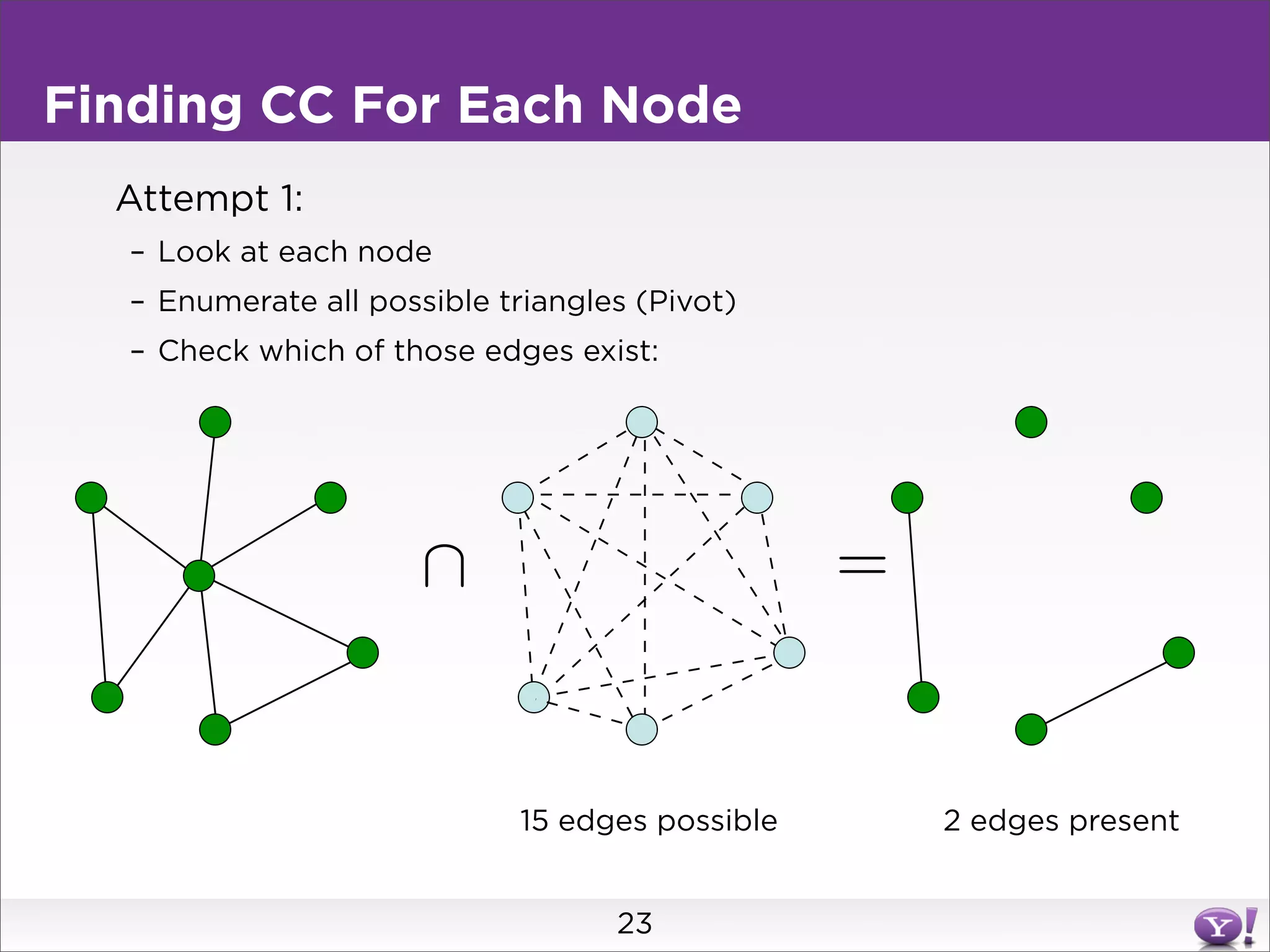





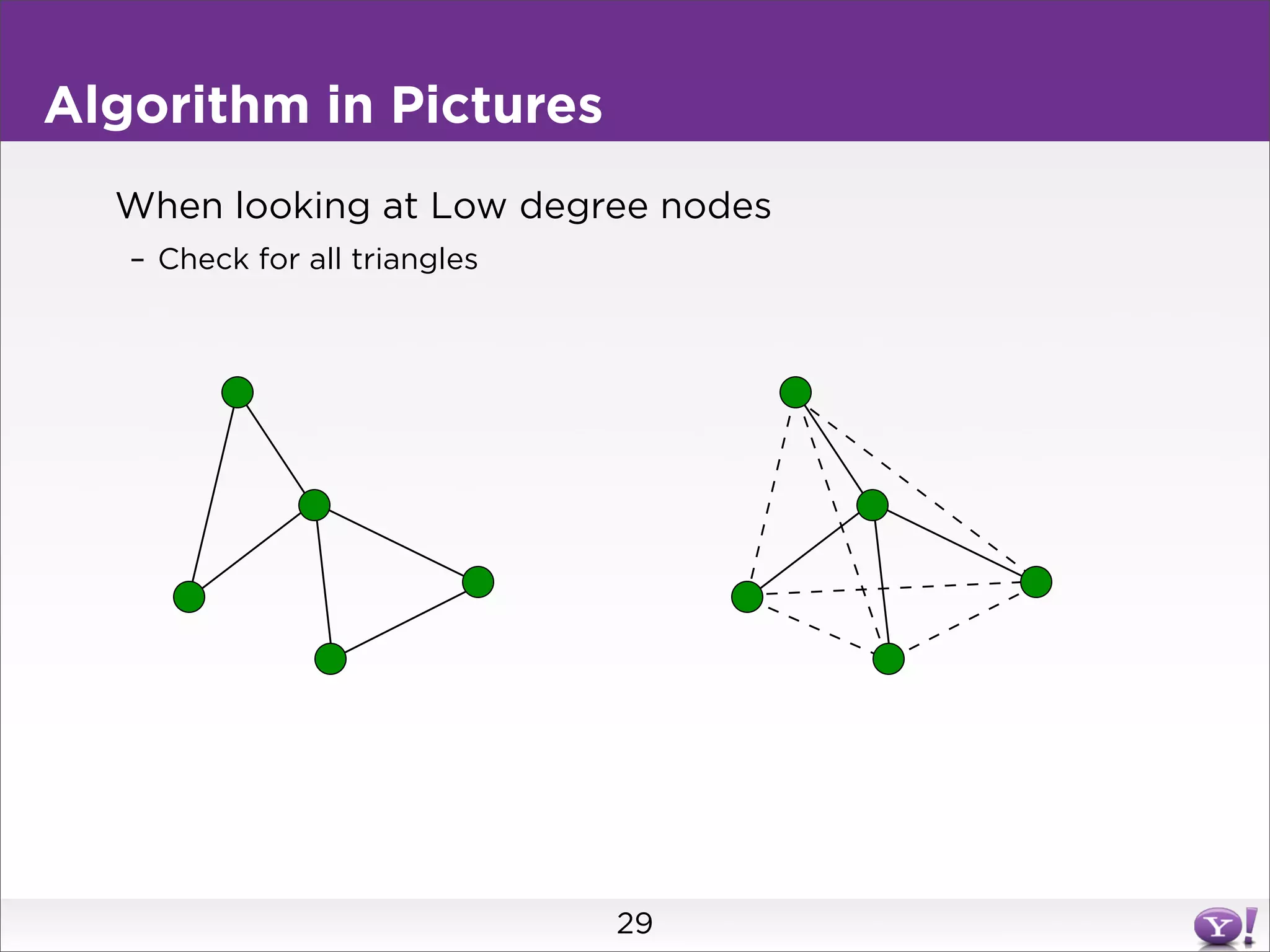
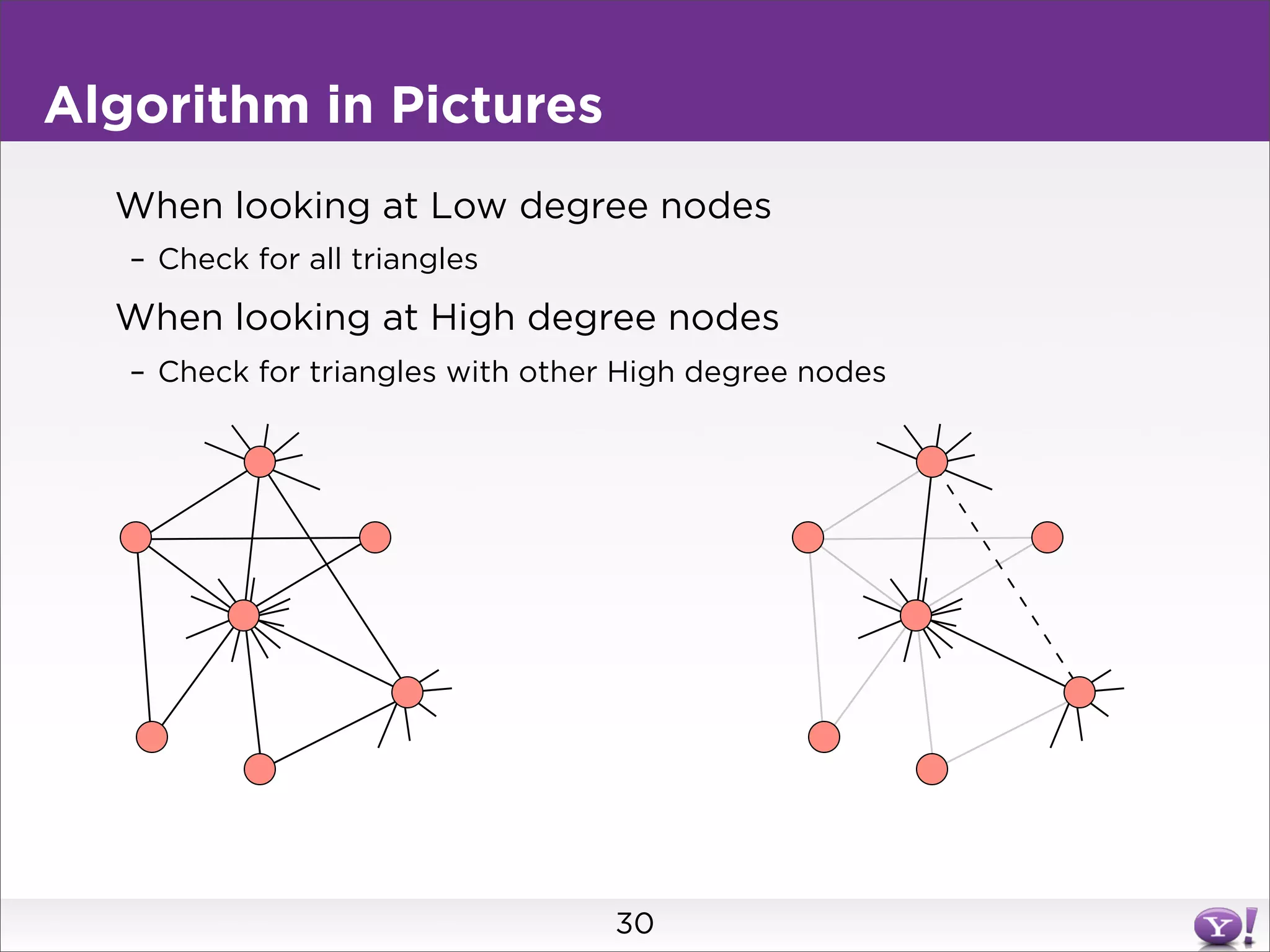





This document summarizes two graph algorithms for analyzing large graphs: connected components and clustering coefficient. For connected components, it describes a two step approach: 1) partition the graph and summarize connectivity on each partition, reducing data size, and 2) recombine the summaries to find the overall connected components. This approach works for other problems like finding minimum spanning trees by summarizing each partition. For clustering coefficient, it describes the challenge of enumerating all possible triangles for each node, which generates quadratic intermediate data. A different approach is needed to scale to very high degree nodes with millions of connections.













































































