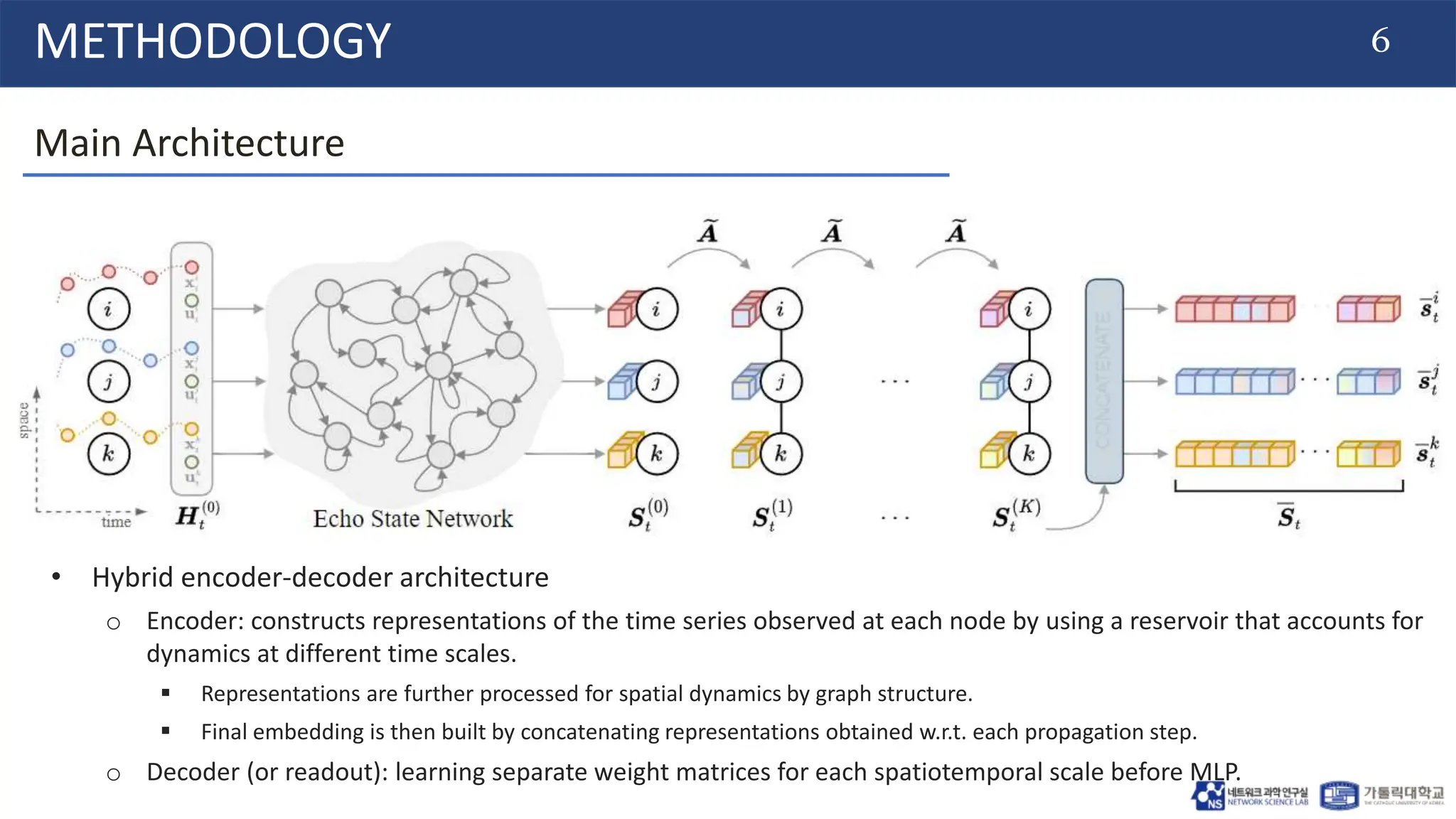
The document introduces a scalable graph predictor (SGP) framework designed for spatiotemporal time series forecasting using graph neural networks (GNNs). It addresses the challenges of computational efficiency and spatial dependencies while predicting future observations from historical data across various datasets. The proposed architecture allows for effective real-time predictions with reduced memory usage and aims to enhance processing capabilities for larger sensor networks.









![11
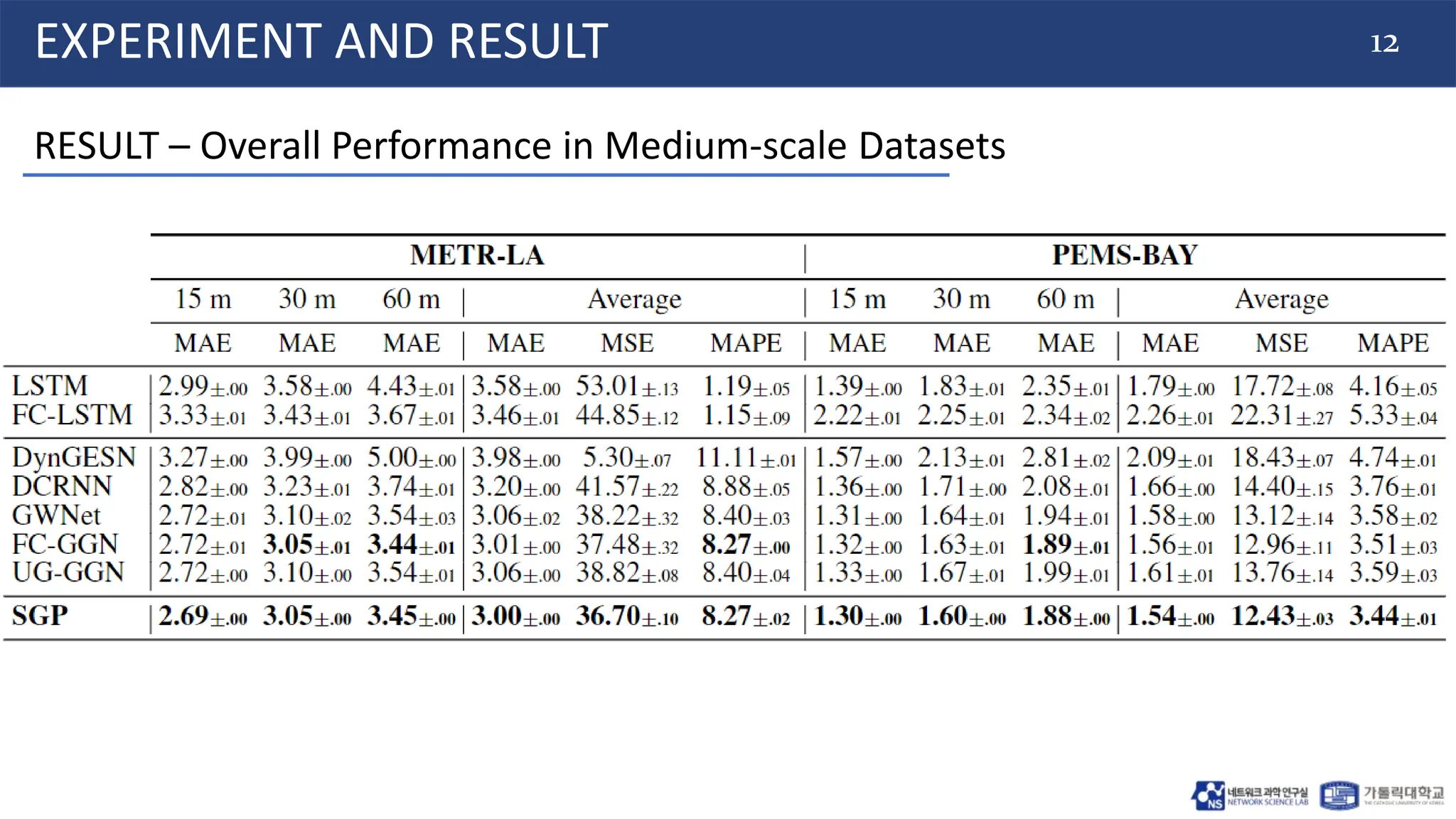
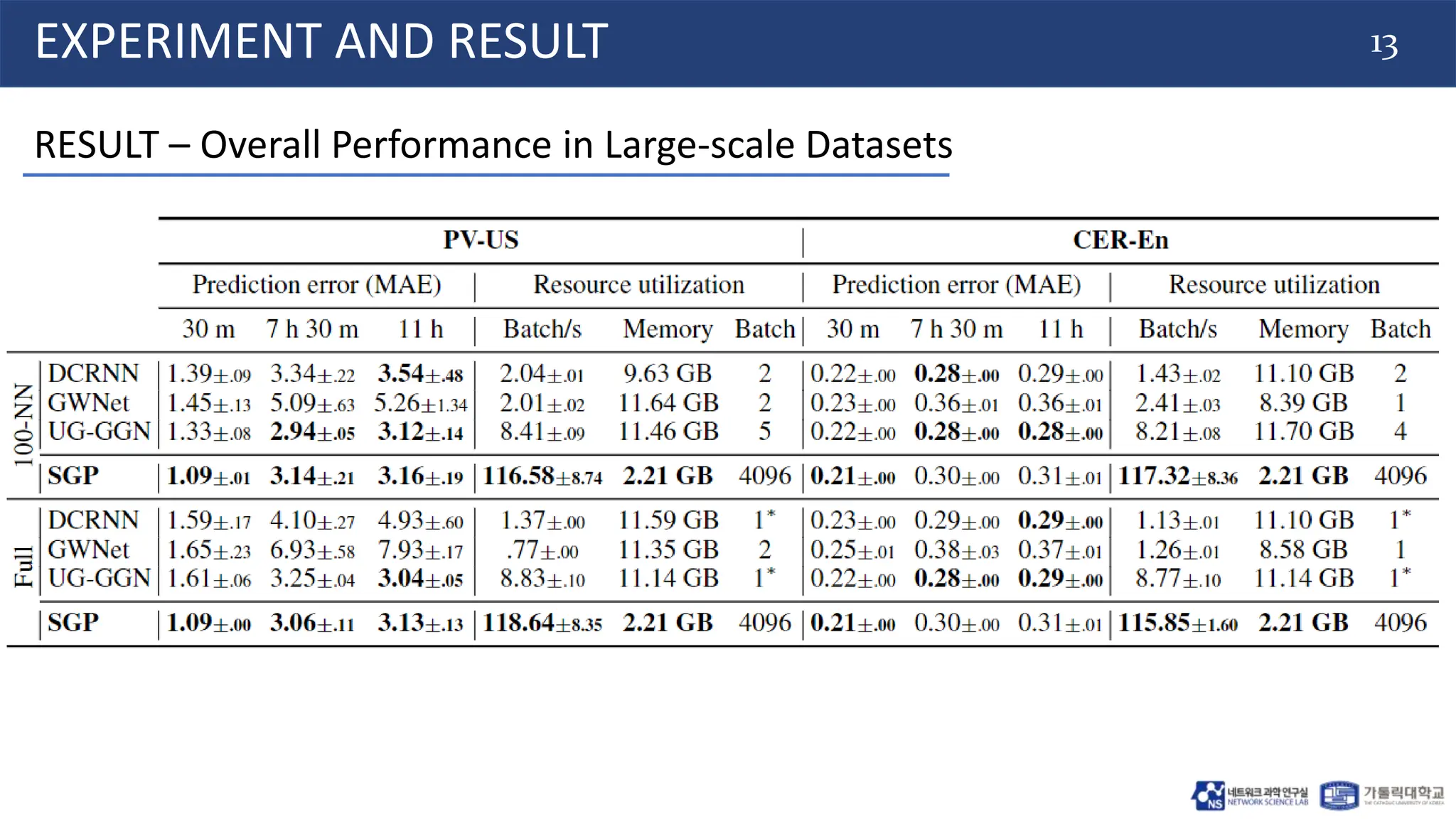
EXPERIMENT AND RESULT
EXPERIMENT SETTINGs
• Dataset:
o Medium scale: METR-LA, PEMS-BAY (traffic dataset).
o Large scale: PV-US, CER-En (Energy production dataset).
• Baselines:
o Deep Learning: LSTM, and FC-LSTM.
o Graph methods: DCRNN[1], Graph WaveNet(GWNet)[2], GatedGN (GGN)[3], and DynGESN[4].
[1] Li, Y., Yu, R., Shahabi, C., & Liu, Y. (2017). Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. arXiv preprint arXiv:1707.01926..
[2] Wu, Z., Pan, S., Long, G., Jiang, J., & Zhang, C. (2019). Graph wavenet for deep spatial-temporal graph modeling. arXiv preprint arXiv:1906.00121.
[3] Gao, J., & Ribeiro, B. (2022, June). On the equivalence between temporal and static equivariant graph representations. In International Conference on Machine Learning (pp. 7052-7076). PMLR.
[4] Micheli, A., & Tortorella, D. (2022). Discrete-time dynamic graph echo state networks. Neurocomputing, 496, 85-95.
• Measurement:
o MAE, MSE, MAPE.](https://image.slidesharecdn.com/20240628labseminarhuyscalablestgnn-240628124039-93589631/75/20240628_LabSeminar_Huy-ScalableSTGNN-pptx-11-2048.jpg)

![[20240628_LabSeminar_Huy]ScalableSTGNN.pptx](https://image.slidesharecdn.com/20240628labseminarhuyscalablestgnn-240628124039-93589631/75/20240628_LabSeminar_Huy-ScalableSTGNN-pptx-15-2048.jpg)
![[20240628_LabSeminar_Huy]ScalableSTGNN.pptx](https://image.slidesharecdn.com/20240628labseminarhuyscalablestgnn-240628124039-93589631/75/20240628_LabSeminar_Huy-ScalableSTGNN-pptx-16-2048.jpg)
![[20240325_LabSeminar_Huy]Spatial-Temporal Fusion Graph Neural Networks for Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/20240325labseminarhuystfgnn-240409103218-8b4b7f23-thumbnail.jpg?width=640&height=640&fit=bounds)
![[20240617_LabSeminar_Huy]Long-term Spatio-Temporal Forecasting via Dynamic Mu...](https://cdn.slidesharecdn.com/ss_thumbnails/20240617labseminarhuylstf-240624082154-84b13b22-thumbnail.jpg?width=640&height=640&fit=bounds)
![[20240805_LabSeminar_Huy]GPT-ST: Generative Pre-Training of Spatio-Temporal G...](https://cdn.slidesharecdn.com/ss_thumbnails/20240805labseminarhuygpt-st-240806102941-cd305d0d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[20240520_LabSeminar_Huy]DSTAGNN: Dynamic Spatial-Temporal Aware Graph Neural...](https://cdn.slidesharecdn.com/ss_thumbnails/20240520labseminarhuydstagnn-240520123156-67d80b3a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[20240527_LabSeminar_Huy]Meta-Graph.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/20240527labseminarhuymeta-graph-240603120740-05a0fa30-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Seminar] hyunwook 0624](https://cdn.slidesharecdn.com/ss_thumbnails/seminarhyunwook0624-200725001151-thumbnail.jpg?width=640&height=640&fit=bounds)
![[20240422_LabSeminar_Huy]Taming_Effect.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/20240422labseminarhuytamingeffect-240423153149-d879b2ce-thumbnail.jpg?width=640&height=640&fit=bounds)
![[20240819_LabSeminar_Huy]Learning Decomposed Spatial Relations for Multi-Vari...](https://cdn.slidesharecdn.com/ss_thumbnails/20240819labseminarhuymvts-240820050208-fa1632cb-thumbnail.jpg?width=640&height=640&fit=bounds)
![[20240703_LabSeminar_Huy]MakeGNNGreatAgain.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/20240703labseminarhuymakegnngreatagain-240704111952-a7569149-thumbnail.jpg?width=640&height=640&fit=bounds)
![[20240624_LabSeminar_Huy]Towards Dynamic Spatial-Temporal Graph Learning: A D...](https://cdn.slidesharecdn.com/ss_thumbnails/20240624labseminarhuytowardst-240624082308-89113683-thumbnail.jpg?width=640&height=640&fit=bounds)

![[20240408_LabSeminar_Huy]PivotalSTGNN.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/20240408labseminarhuypivotalstgnn-240408123002-61e9cc31-thumbnail.jpg?width=640&height=640&fit=bounds)
![[20240415_LabSeminar_Huy]Deciphering Spatio-Temporal Graph Forecasting: A Cau...](https://cdn.slidesharecdn.com/ss_thumbnails/20240415labseminarhuydecipher-240416043604-ff3fafd1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[20240429_LabSeminar_Huy]Spatio-Temporal Graph Neural Point Process for Traff...](https://cdn.slidesharecdn.com/ss_thumbnails/20240429labseminarhuynpp-240429122642-30caa8b7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[20240722_LabSeminar_Huy]WaveForM: Graph Enhanced Wavelet Learning for Long S...](https://cdn.slidesharecdn.com/ss_thumbnails/20240722labseminarhuywaveform-240723105123-dac2b760-thumbnail.jpg?width=640&height=640&fit=bounds)

![[20240513_LabSeminar_Huy]GraphFewShort_Transfer.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/20240513labseminarhuygraphfewshorttransfer-240513115300-6433ea00-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Yonsei AI Workshop 2022] Graph Neural Controlled Differential Equations for ...](https://cdn.slidesharecdn.com/ss_thumbnails/dhcx9l1rc2acdkwbnqyx-aaai22-workshop-221019003243-979010ab-thumbnail.jpg?width=640&height=640&fit=bounds)




![251124_Thanh_LabSeminar[Hyper-YOLO].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251124thanhlabseminarhyper-yolo-251124113258-535062b4-thumbnail.jpg?width=640&height=640&fit=bounds)
![251124_Thuy_Labseminar[Vision GNN: An Image is Worth Graph of Nodes].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251124thuylabseminar-251124113257-025487fe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NS][Lab_Seminar_251201]High-Precision Mixed Feature Fusion Network Using Hyp...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar251201mlf-snet-251206120538-22fa2497-thumbnail.jpg?width=640&height=640&fit=bounds)

![[NS][Lab_Seminar_251110]ControlMLLM.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar251110controlmllm-251110090012-39bbf00d-thumbnail.jpg?width=640&height=640&fit=bounds)
![251103_SH_LabSeminar[Expressiveness of Graph Neural Networks].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251103shlabseminarppgn-251103113317-1094e696-thumbnail.jpg?width=640&height=640&fit=bounds)
![251103_Thanh_LabSeminar[One Last Attention for Your Vision-Language Model].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251103thanhlabseminarrada-251103113308-f66fee0b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NS][Lab_Seminar_251027]From Pixels to Graphs: Open-Vocabulary Scene Graph Ge...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar251027pgsg-251027105020-631aebf6-thumbnail.jpg?width=640&height=640&fit=bounds)

![251124_HW_LabSeminar[Multimodal-SCM].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251124hwlabseminarmultimodal-scm-251124113300-6fad72e4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NS][Lab_Seminar_251020]HyperGLM: HyperGraph for Video Scene Graph Generation...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar251020hyperglm-251020095526-46c0e264-thumbnail.jpg?width=640&height=640&fit=bounds)
![251110_HW_LabSeminar[WHAT TO ALIGN IN MULTIMODAL CONTRASTIVE LEARNING?].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251110hwlabseminarcomm-251110103747-14b1b798-thumbnail.jpg?width=640&height=640&fit=bounds)
![251103_Thuy_Labseminar[Grounded Language-Image Pre-training].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251103thuylabseminar-251103113311-941d56eb-thumbnail.jpg?width=640&height=640&fit=bounds)




![251027_Thuy_Labseminar[Scaling Language-Image Pre-training via Masking].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251027thuylabseminar-251027105015-a1b9f3e8-thumbnail.jpg?width=640&height=640&fit=bounds)




















