Download to read offline



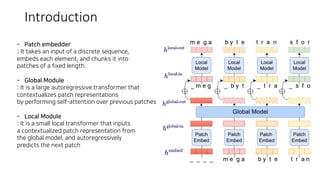













This document describes MEGABYTE, a model for predicting million-byte sequences using multiscale transformers. MEGABYTE uses a patch embedder to chunk input sequences into fixed-length patches, a global transformer to contextualize patches, and a local transformer to autoregressively predict the next patch. The local transformer is needed to increase parameters for fixed compute and reuse established transformer components. MEGABYTE achieves state-of-the-art performance on language modeling tasks and can process sequences over 1 million tokens efficiently by splitting computation between global and local transformers.














































