Download to read offline










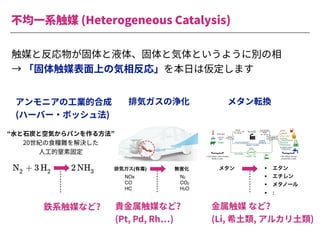




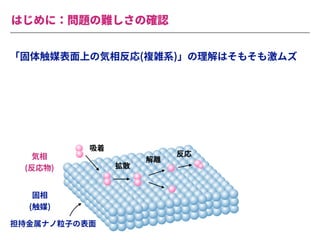
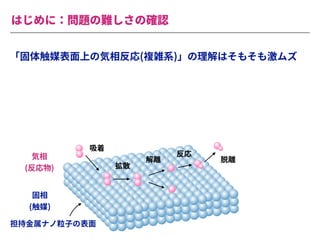
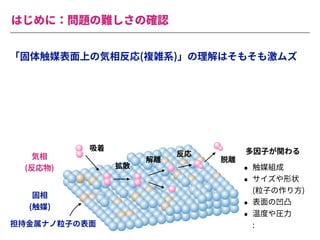
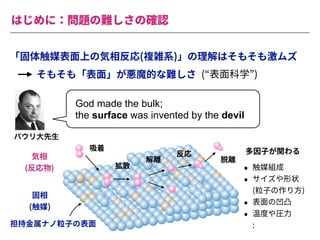
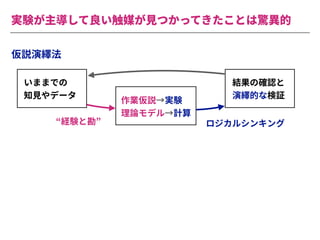
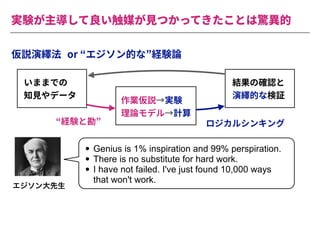




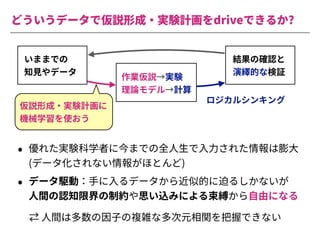



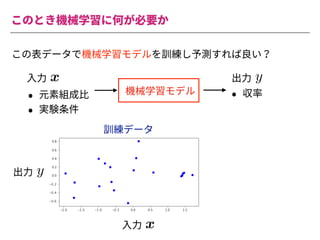
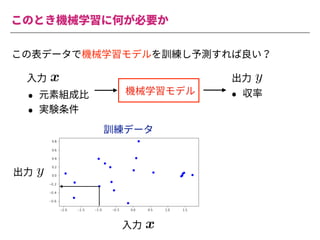
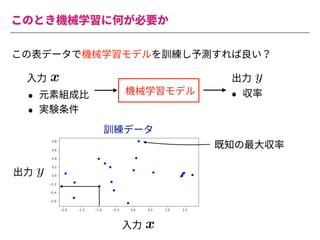
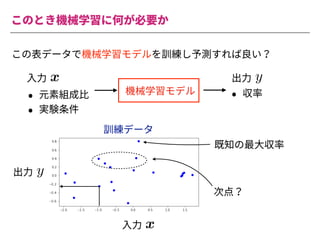
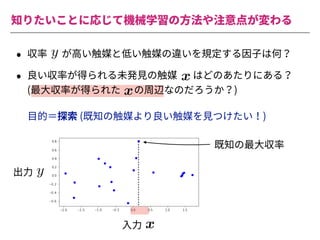
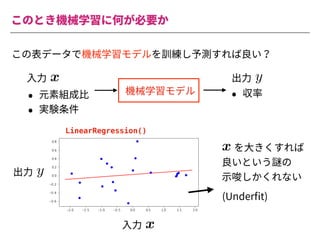
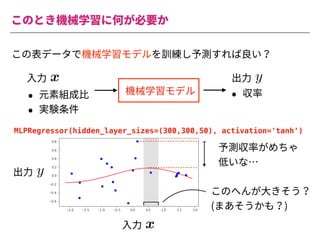
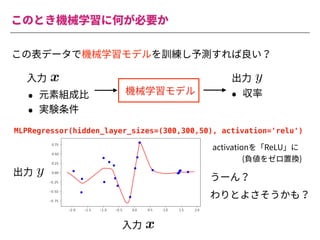
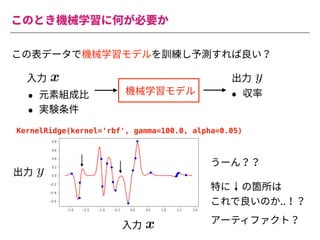
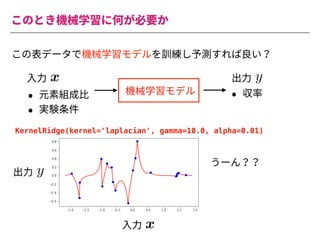
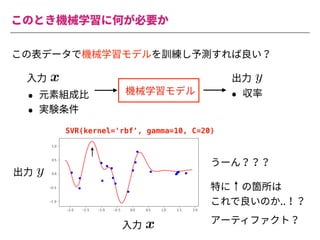
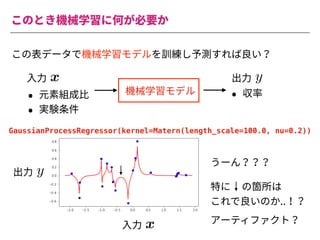
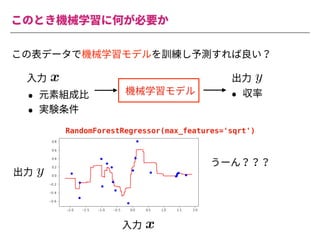
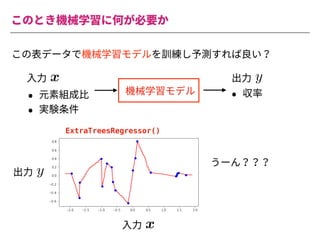
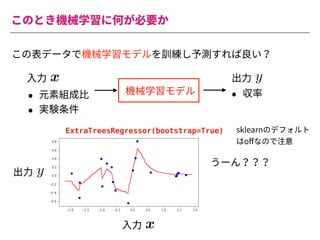
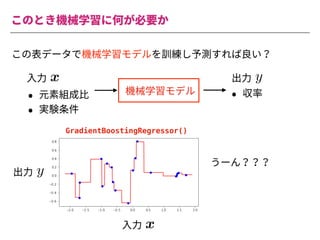
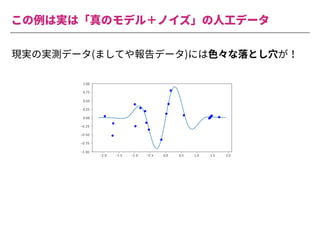
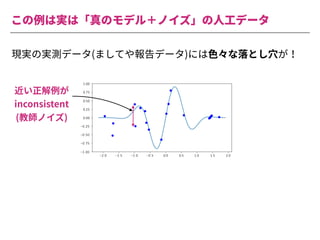
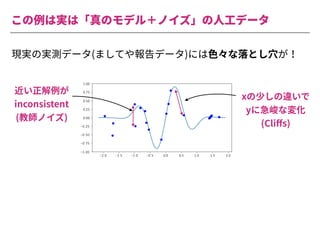
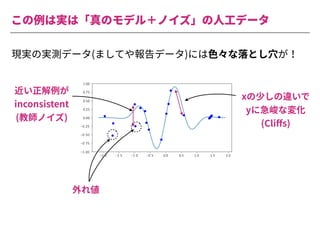
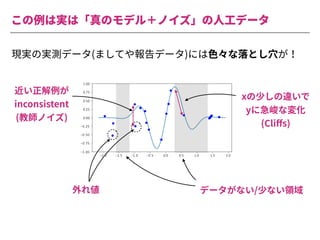
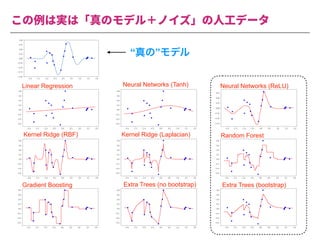

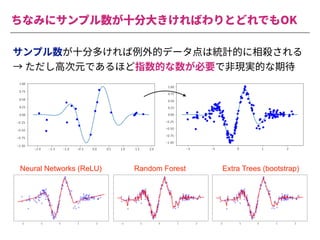
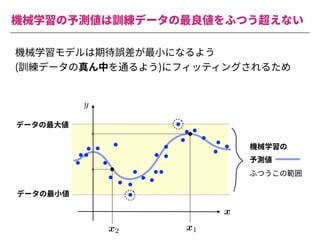
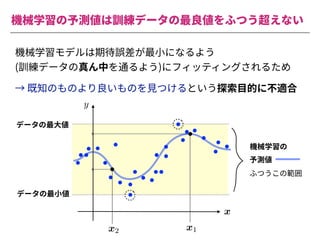
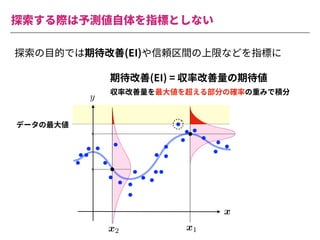

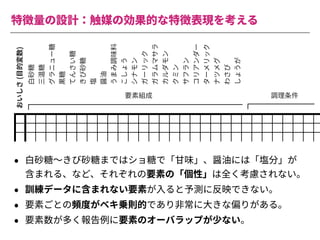
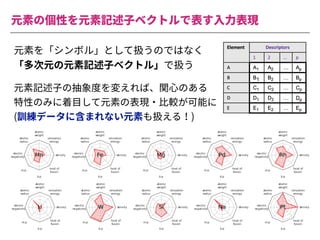
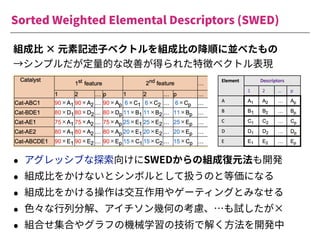
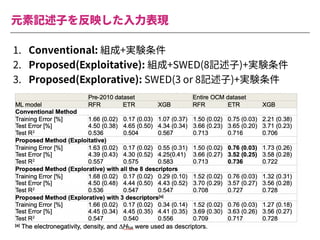


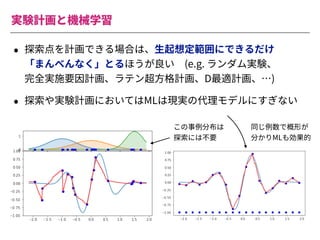




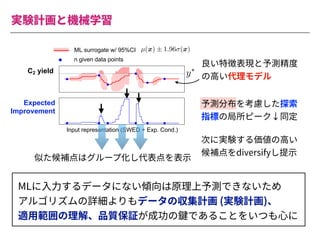
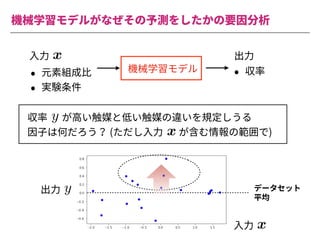
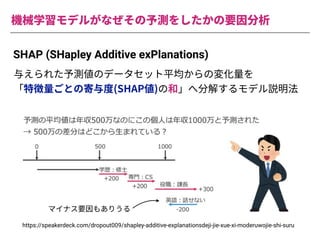
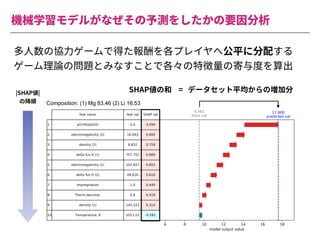

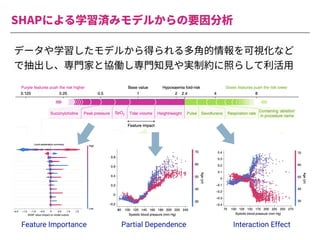


The document summarizes a presentation by Itakawa Ichigaku on using machine learning and optimal experimental design for heterogeneous catalysis research. Itakawa introduces himself and his background working in machine learning and its applications in natural science fields. He emphasizes that applying machine learning to natural sciences requires close collaboration with domain experts and understanding ML's capabilities and limitations. The presentation aims to help audiences understand these points and properly position ML's role in exploratory research through examples from his past work.

















![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)







































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)
















