Recommended
PDF
SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...
PDF
20180115_東大医学部機能生物学セミナー_深層学習の最前線とこれから_岡野原大輔
PDF
Jubatusにおける大規模分散オンライン機械学習
PPTX
PDF
Learning to forget continual prediction with lstm
PPTX
PDF
20171201 dll#05 名古屋_pfn_hiroshi_maruyama
PDF
PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
PDF
【参考文献追加】20180115_東大医学部機能生物学セミナー_深層学習の最前線とこれから_岡野原大輔
PDF
PPTX
PDF
20180305_ppl2018_演繹から帰納へ~新しいシステム開発パラダイム~
PDF
PPTX
「機械学習とは?」から始める Deep learning実践入門
PDF
Deep learning を用いた画像から説明文の自動生成に関する研究の紹介
PPTX
ICML2018読み会: Overview of NLP / Adversarial Attacks
PDF
PDF
PDF
日本ソフトウェア科学会第36回大会発表資料「帰納的プログラミングの初等教育の試み」西澤勇輝
PPTX
Semi supervised, weakly-supervised, unsupervised, and active learning
PDF
Convolutional Neural Netwoks で自然言語処理をする
PDF
PDF
Introduction to Deep Compression
PDF
Adversarial Networks の画像生成に迫る @WBAFLカジュアルトーク#3
PDF
PDF
LCCC2010:Learning on Cores, Clusters and Cloudsの解説
PDF
PPTX
PDF
More Related Content
PDF
SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...
PDF
20180115_東大医学部機能生物学セミナー_深層学習の最前線とこれから_岡野原大輔
PDF
Jubatusにおける大規模分散オンライン機械学習
PPTX
PDF
Learning to forget continual prediction with lstm
PPTX
PDF
20171201 dll#05 名古屋_pfn_hiroshi_maruyama
PDF
What's hot
PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
PDF
【参考文献追加】20180115_東大医学部機能生物学セミナー_深層学習の最前線とこれから_岡野原大輔
PDF
PPTX
PDF
20180305_ppl2018_演繹から帰納へ~新しいシステム開発パラダイム~
PDF
PPTX
「機械学習とは?」から始める Deep learning実践入門
PDF
Deep learning を用いた画像から説明文の自動生成に関する研究の紹介
PPTX
ICML2018読み会: Overview of NLP / Adversarial Attacks
PDF
PDF
PDF
日本ソフトウェア科学会第36回大会発表資料「帰納的プログラミングの初等教育の試み」西澤勇輝
PPTX
Semi supervised, weakly-supervised, unsupervised, and active learning
PDF
Convolutional Neural Netwoks で自然言語処理をする
PDF
PDF
Introduction to Deep Compression
PDF
Adversarial Networks の画像生成に迫る @WBAFLカジュアルトーク#3
PDF
PDF
LCCC2010:Learning on Cores, Clusters and Cloudsの解説
PDF
Similar to 20171015 mosa machine learning
PPTX
PDF
PPTX
PDF
PDF
アドテクと機械学習システムの開発@SMN・サンカク・CodeIQワークショップ
PPTX
Machine Learning Fundamentals IEEE
PPTX
Jupyter NotebookとChainerで楽々Deep Learning
PPTX
PDF
PPTX
PDF
機械学習工学と機械学習応用システムの開発@SmartSEセミナー(2021/3/30)
PPTX
1028 TECH & BRIDGE MEETING
PDF
PDF
Azure Machine Learning� getting started
PDF
Hands on-ml section1-1st-half-20210317
PPTX
PPTX
PDF
PDF
深層学習(ディープラーニング)入門勉強会資料(浅川)
PPTX
20171015 mosa machine learning 1. 2. 3. アジェンダ
機械学習とは?(Machine Learning)
Apple Core MLについて
WWDC 2017 で紹介された “Introducing Core ML”の解説
2017/9/12 iPhone 8, 8 Plus, X Apple Event
機械学習で必要な知識概要
現在の機械学習の概要
線形回帰:マンションの価格予想
分類問題:ロジステック回帰
ニューラル・ネットワーク(Neural Network)、深層学習(Deep Learning) 手書き数
字認識
ゲームAI
シンギュラリティは起こるか?
3
4. 5. AIの適用例
5
経済指標の予測
天気予報
交通インフラの予測
ゲームAI
RPGゲームAI
オペレーションサポート、コー
ルセンター
美少女AIとおしゃべり
クイズ番組優勝
医療 癌の発見
大学入試 人工知能が東大入試
に挑むプロジェクトが進行中
自動車 自動運転
ロボット ソフトバンクのペッ
パー
お掃除ロボット
検索エンジン 機械学習によっ
て検索エンジンを最適化
リコメンドシステム
機械翻訳
マーケティングデータ解析
1000分の1秒のアドテクノロ
ジー
投資信託(ロボアドバイザ)
高速高頻度取引トレード
白黒→カラー化
線画着色サービス
音声認識
手書き認識
自然言語処理
パーソナルデジタルアシスタン
ト(Amazon Echo, Siri)
戦争:戦闘機バトルでも人間を
打ち負かす
放送局
不動産投資
毎日のファッションを決める
ARを使った洋服選択
交通
自動執筆
社員の幸福感高めるアドバイス
人工知能搭載ドローン
人間の行動解析
教育(セサミストリート
+Watson)
英語のコーチング
家電製品への応用
クレジットカードの不正使用検
知
倉庫集配センターのロボット、
AI活用
パン屋やラーメン屋でも導入事
例
人材マッチング
人材採用への活用
完全自動決算サマリー
犯罪予知
プロ野球チケットの価格変動
サービス
最高のビールを選んでくれるAI
飛行機の完全自動操縦
………
6. 7. 8. 9. ニューラルネットワークの歴史
1943 現在のニューラルネットの基本単位であるMcCulloch-Pittsモデル
1958 パーセプトロンと誤り訂正学習則により第1次黄金期に
1969 Minsky らのパーセプトロンの限界の指摘で第1次氷河期に
1980 現在のCNNの源流である福島のネオコグニトロン
1986 バックプロパゲーション (BP) という多層NNの学習手法で第2次黄金期
1989 ネオコグニトロンとBPを組み合わせた現在のCNNをLeCunらが開発
1989 Waibelによる時系列データを扱う時間遅れNNの提案
1990 現在のRNNの源流であるElmanネットワークの提案
1995 ALVINN:ニューラルネットによる公道走行実験の成功
1995 Vapnikらによるサポートベクトルマシンの開発でNNは第2次氷河期
1997 現在のRNNの主流であるLSTM法の提案 2006 現在は使われなくなったが事前学
習による多層NNの学習の提案.深層学習 の始まりとされる
2012 ILSVRCで劇的な結果を収めたことで注目を集め第3次黄金期に突入
2014 過学習に対処するための手法 DropOut の提案
データマイニング・機械学習分野の概要 P18 神嶌敏弘
http://www.kamishima.net/archive/mldm-overview.pdf
9
10. 11. 12. 13. 14. 15. 1:50 適用例
Entity Recognition
固有名詞(人名、地名など)や日付、時間表現など
を抽出する技術
Sentiment Analysis
自然言語処理の一部でpositive/negativeを判断する
Emotion Detection
喜怒哀楽を予想する
Speaker Identification
複数の話手の認識(カクテルパーティー効果)
Music Tagging
音楽のタグ付け(ロック、クラッシック、、、)
15
16. 17. 18. 19. 6:00 チャレンジへの回答
チャレンジ
正確性
パフォーマンス
エネルギー効果
アップルが提供した解決策
ML Framework
(アプリケーション開発者は)ユーザーエクス
ペリエンスにフォーカスし実装すればよい
リアルなアプローチ
19
20. 7:21 ML Frameworks
Vision
コンピュータのビジョン
Natural language processing
自然言語処理とそれを司る機能
Core ML
機械学習や深層学習のモデルをサポー
トするフレームワーク
Accelerate and BNNS(Basic Neural
Network Subroutines)
BNNSはニューラルネットワークを処理
するためのいろいろなサブルーチン
WWDC 2016のNeural Networks and
AccelerateでOSSとして紹介されている。
CPUベース
Metal Performance Shaders
ARKitなどどともに動作するGPU関係の
フレームワーク
WWDC 2016のNeural Networks and
Accelerateでも紹介されている。畳み
込み演算機能が行える。GPUベース
OpenCLとほぼ同じ
20
21. 7:52 Vision Frameworks
Object Detection Tracking(動画中のオ
ブジェクトの探索と追跡)
Face Detection(顔の認識)
Image Analysis Classifying Image with
Vision and Core ML: Core MLを使った画
像のクラス分類
Barcode Detection:バーコード位置の探
索
Image Alignment Analysis:画像の位置合
わせ:?移動、回転ができるよう
Text Detection: 文字の探索
Horizon Detection: 回転角度の探索
21
22. 8:21 Natural Language Recognition
自然言語処理
Language Identification 言語の種
別の認識(英語、スペイン語…)
Name Entity Recognition:テキスト
の中から場所の名前や仲間の名前
トークンの範囲(日本語では?)
タッギング
String & TextのNSLinguistic Tagger
に実装が追加されている
22
23. 9:00 Core ML
Multiple kinds Inputの管理(イメー
ジ、テキスト、ディクショナリ、
生の番号)
イメージのキャプションからテキ
ストを出力
Modelの読み込みや制御、入出力
の制御
23
24. 9:00 Accelerate and MPS
機械学習のCPUアクセレータ、
GPUでの実行
数学的な関数
高速、ハイパフォーマンス
カスタムMLモデル。実はiOS10か
らモデルがなくても機械学習はで
きていた
24
25. 10:58 Run on Device
iPhoneの中で完結する
ユーザーのプライバシー
データのコスト
サーバーのコスト
24 x 7使用可能(ネットワークの接続なしでも動作)
25
26. 10:58 Real Time Image Recognition
画像をリアルタイムでキャプ
チャーして物体の判断をしている
これはすごい
人間の目には何が映っていないか
わからない冷蔵庫のConfidence(確
信度)が26%なのに、右側のバナナ
は10.3%
26
27. 17:14 Core ML
Core MLはフレームワークだけで
やAPIの集合ではなく、できるだ
けアプリケーションを簡単にした
ものである。
実現しようとしているユーザーエ
クスペリエンスにフォーカスでき
る
27
28. 14:30 Core ML Overview (Simple, Performant,
Compatible)
Simple
すべてのModelで共通のAPI
Xcodeでインテグレーションして
いるのですべてのアプリで使える
Performant
既にたくさんのエンジンをだして
ているので、チューニングされて
いる
アクセレータ、Metalの組込
Compatible
機械学習のエコシステムをサポー
トしている
Modelは新しいパブリックな
フォーマットで記述している
ポピュラーなライブラリをCore
MLに変換できる
28
29. 15:37 Core ML Model
Modelの入力、出力をCore MLによ
り共通化することできる
Sentiment Analysisの場合は入力が
英語で出力がポジティブかネガ
ティブを示す絵文字(That was
totally awsome Leo!→😃)
29
30. 16:14 Core ML Model
順伝搬ニューラルネットワーク
畳み込みニューラルネットワーク
再帰的ニューラルネットワーク
木構造アセンブル
サポート・ベクター・マシーン
一般的な線形モデル
30
31. 32. 17:24 Where do models come from?
Sample Modelsは、https://developer.apple.com/machine-learning
Explore (探せ!)
32
33. AppleのHPにあるサンプルモデル(9/18現在)
MobileNet
https://github.com/tensorflow/models/blob/master/slim/nets/mobilenet_v1.md
軽量なRNN。木、動物、食べ物、乗り物、人など1000種類のカテゴリのセットから画像に存在するオブジェクトを
検出する
SqueezeNet
https://github.com/DeepScale/SqueezeNet/blob/master/SqueezeNet_v1.1/squeezenet_v1.1.caffemodel
木、動物、食べ物、乗り物、人など1000種類のカテゴリのセットから画像に存在するオブジェクトを検出する。わ
ずか5 MBのフットプリント全体で、SqueezeNetはAlexNetと同等の精度を持つが、パラメータは50分の1。
Places205-GoogLeNet
https://github.com/BVLC/caffe/wiki/Model-Zoo
空港ターミナル、寝室、森林、海岸など205のカテゴリから画像のシーンを検出する
ResNet50
https://github.com/fchollet/keras
木、動物、食べ物、乗り物、人など1000種類のカテゴリのセットから画像に存在するオブジェクトを検出する
Inception v3
https://github.com/fchollet/deep-learning-models
木、動物、食べ物、乗り物、人など1000種類のカテゴリのセットから画像に存在するオブジェクトを検出する。
VGG16
http://www.robots.ox.ac.uk/~vgg/research/very_deep/
木、動物、食べ物、乗り物、人など1000種類のカテゴリのセットから画像に存在するオブジェクトを検出する
33
34. 17:24 データを追加したい、スクラッチから作
りたい
Core MLはラストワンマイル
Kerasは、TensorFlow(Google)またはCNTK(Microsoft)、Theano(Theano Development Team)上で実行可能な高水準のニューラルネッ
トワークライブラリ。Pythonのみ。デフォルトでは、TensorFlowを計算ライブラリにしている。
Caffeの深層学習のフレームワーク。(Barkley Artificial Intelligence Research) GoogleがTensorFlowを出す前はCoffeeが優勢だった
が今はTensorFlowが優勢かな?
scikit-lean: PythonでMachine Learningを行うフレームワーク。スポンサー→
XGBoostは、次のページでは木構造だけだが、そのほかの機械学習もサポートしている。Supports multiple languages C++, Python, R,
Java, Scala, Julia
turiは、機械学習用のモデルを作成し学習するツール(Pythonがメインだが、C++でプラグインが作れる)
LIBSVMは、サポートベクターマシーンをサポートするライブラリ、国立台湾大学(2016/12/22 V3.22が最終リリース)ほとんど言語か
らアクセス可能。swiftは発見できず)
34
35. Core ML Toolsが変換できるモデル
Model type Supported models Supported
framework
Neural networks Feedforward,
convolutional, recurrent
Caffe v1
Keras 1.2.2+
Tree ensembles Random forests, boosted
trees, decision trees
scikit-learn 0.18
XGBoost 0.6
Support vector
machines
Scalar regression,
multiclass classification
scikit-learn 0.18
LIBSVM 3.22
Generalized linear
models
Linear regression, logistic
regression
scikit-learn 0.18
Feature engineering Sparse vectorization,
dense vectorization,
categorical processing
scikit-learn 0.18
Pipeline models Sequentially chained
models
scikit-learn 0.18
Converting Trained Models to Core ML
https://developer.apple.com/documentation/coreml/converting_trained_models_to_core_ml
35
36. 17:24 Core MLモデルへの変換
フレームワークが作ったデータを変換するのがCore ML Tools
Pythonで書かれたツールで、Open Source
ここで書かれたフレームワーク以外にもたくさんのフレームワークが存在する
Theano Python Library http://deeplearning.net/software/theano/
Chainer (Preferred Network) https://chainer.org/
H20.ai https://www.h2o.ai/
こんなにあった! Deep Learning Frameworkまとめ by AZUMAX(https://bita.jp/dml/dl_matome)
36
37. 20:12 Model as Code
Modelができさえすれば、XcodeがModelからコードを作成する
Model自体もBundleとしてiPhoneに送られる
37
38. 39. 40. 41. 42. 43. Core ML のすごいところ
A10, A11 を使ってiOSで高速に動作する
Forward PropagationでもCPU/GPUのリソースが必要
モデルさえあれば、機械学習のことをあまり知らなくてもアプリケー
ションが書ける
実はVisionについては、iOS10でも同じことができたが、かなり簡単に実
装できるようになった
Metal Performance
Shaders
Accelerate
(BNNS)
Your App
(MPSCNN or BNNSを実装)
Metal Performance
Shaders
Accelerate
(BNNS)
Core ML
Vision
Your App
Core ML vs MPSCNN vs BNNS Shuichi Tsutusumi
https://speakerdeck.com/shu223/core-ml-vs-mpscnn-vs-bnns-number-fincwwdc
iOS 11
Modelがあればほとんどコードを
書かなくてよい
iOS 10
Modelがあっても
Your Appのコードが面倒
43
44. iOSで機械学習を実装する場合
標準のAPIでサポート
されている ?
標準のAPIを使う
SiriKit
(Voice Recognition)
ARKit
(Face Tracking)
LocalAuthentication
(Face ID, Touch ID)
Metal 2, Metal 2
Bionic
(Graphics)
AVFoundataion
(Barcode Reader)
他で使えるものがあ
る?
他のものを使う
Google
(Search)
Amazon
(Recommend)
Core ML
Modelが存在する?
Core ML
OSSなどで使用できる
もの`がある ?
Core MLのModelに変
換できるFramework ?
Core ML ToolsでCore
ML Modelに変換
OSSのCore ML Toolsを
修正する
必要なデータが学習さ
れていない
Frameworkで
Core ML Modelを作る
Frameworkで
Core ML Modelを作る
Core MLを使わない
44
45. 46. AppleのAI研究
Apple、個人情報保護を念頭に置きながら人工知能分野強化
を計画か 2015/9/8 (https://iphone-mania.jp/news-83248/)
自社の個人情報保護方針が足かせに
しかし、Appleは皮肉にも自社の個人情報保護が足かせとなり、この分野におい
て遅れをとっているとされています。通常、企業はユーザーの利用データをク
ラウド上に蓄積し分析することで、ユーザーニーズを予測する技術の実現を目
指すのですが、Appleはクラウド上にユーザーデータを蓄積していないとされて
います。
AIの世界で注目されている「ディープラーニング(深層学習)」には膨大なデー
タ量が必要であるにも関わらず、Appleにはそれがないのです。
こうした状況から、同分野の専門家たちはAppleでの仕事を敬遠していると伝え
られていますが、一方で一部の研究者たちはAppleのこうした姿勢に惹かれるか
もしれないとしており、今後の動きに注目されます。個人情報の保護に関して
は、国内でも様々な議論があり、仮にAppleがこうした技術の開発に成功すれば、
先行して個人情報を大量に集めている企業群は批判の的にさらされる可能性が
あります。
Apple、初の人工知能研究論文で権威ある賞を受賞 2017/8/28
(https://iphone-mania.jp/news-179471/)
AppleのAI研究は、より効率の良い機械学習のための新しい手法を示すもので、
コンピュータにより生成された合成画像を、人工知能アルゴリズムの一種であ
る敵対的生成ネットワーク(Generative adversarial networks、通称: GANs)を
用いることにより、本物の画像と見分けがつかないものへと変換できるとのこ
とです。 46
47. 48. 機械学習で知っているほうがよい
知識
ことば
これがわからないとちょっと話がわからないかもしれません。高レベルのTensorflowとかChainerを使う場合も
必要
数学
線形代数
とりあえず、行列の(内)積だけでわかればよいです
ゆとり世代以外の方は高校生で2行2列 x 2行2列の積は習っています
2行2列以上は理系の大学一年生の線形代数でならっています。
微分
通常の微分および偏微分が分かればいうことなしです
高校生のときの数IIBを思い出していただければありがたいのですがわからなくてもなんとかなります
偏微分については、理系の大学の1年生のときの微分積分学でならっています。文系の方もいると思うので、
後でちょっとだけ説明します。
統計学
高校の数IIIでならっていると思いますが、私も思い出せません。ということでつかわないのではないかと?正
規分布とか二項分布とかいうやつです。
プログラム言語
Pythonが一番便利ですが、C++でもJAVAでもよいです
SWIFTはわかりませんがObjective-C経由で使えると思います
48
49. 機械学習のことば
Scholar (スカラー)
一つの実数、例えば、1.0 とか0.0とか𝜋とか𝑒
𝑒はネイピア数(= 2.71828182846)と呼ばれ、 𝑒 𝑥
を𝑥で微分しても
𝑒 𝑥
となる。(𝑒 𝑥
)′
= 𝑒 𝑥
または、
𝑑
𝑑𝑥
𝑒 𝑥
= 𝑒 𝑥
と記述
Vector (ベクトル、ベクター)
スカラが集まった一次元の数字の集まり、横に並べることが多い
[1.0, 2.0, 3.0], [0, 0, 0, 0, 0] などなど
Matrix (行列、マトリックス)
2次元のスカラを並べたもの
1 2 3
4 5 6
は2行3列で2×3の行列とよ
ぶ
スカラは1×1の行列、ベクトルは1×N(またはN×1 )の行列
Tensor(テンソル、テンサー)
上記の概念をひっくるめたもの、上記の総称
階数0がスカラー、階数1がベクター、階数2が行列
49
50. 機械学習の数学(行列)
行列の(内)積
𝑎 =
𝑎11 𝑎12 𝑎13
𝑎21 𝑎22 𝑎23
, 𝑏 =
𝑏11 𝑏12
𝑏21 𝑏22
𝑏31 𝑏32
の場合、
c=𝑎・𝑏 =
𝑎11 𝑏11 + 𝑎12 𝑏21 +𝑎13 𝑏31 𝑎11 𝑏12 + 𝑎12 𝑏22 +𝑎13 𝑏32
𝑎21 𝑏11 + 𝑎22 𝑏21 +𝑎23 𝑏31 𝑎21 𝑏12 + 𝑎22 𝑏22 +𝑎23 𝑏32
𝑚× 𝑛の行列と𝑛× 𝑘の行列の積は𝑚 × 𝑘の行列となる(前の行列の列数と
後ろの行列の行数が同じでないものは積は計算できない)
すなわち、Cで記述すると、
for (i=0; i<M; ++i) {
for ( j=0; j<K; ++j) {
c[i][j] = 0;
for ( l=0; l<N; ++l) {
c[i][j] += a[i][l]*b[l][j];
}
}
}
転置行列
M×Nの行列の転置行列は、N×Mの行列。行と列を反対にしたも
の
50
51. 52. 53. 54. 教師ありの線形勾配降下法概要
データを集める。本当はデータがあるから機械学習をする
モデルの検討
特徴の選択、特徴量の決定
評価関数(または仮定関数、目的関数)の決定
モデルから誤差関数(または損失関数とかエラー関数ともいう)を決定する。
コスト関数は予測したデータと実際のデータとの差分で、これを小さくすることが
機械学習の目的です。実際のデータと予測した値の差分が大きいと大きくなり、小
さいと小さくなるような関数のことを誤差関数といいます
誤差関数を最小化する
ステップ1(データの選択)
訓練データの全体または一部を選択する。次の例(マンションの販売価格の例)
ではデータが少ないので、全部のデータを使う)
ステップ2(誤差の計算)
各特徴量をパラメータ化しそれからコスト関数を求める。(この時に予想した値
と実際の教師データを使う)
ステップ3(勾配の計算)
コスト関数から勾配を求める。特徴量のパラメータを勾配方向に微少量だけずら
す
ステップ1からステップ3を繰り返す
54
55. 実例:線形勾配降下法
マンションの販売価格の予想
いろいろな特徴から販売価格を見積もる、予想する
特徴
マンションの広さ(単位平方メートル𝑚2
、坪数でもいいです
が): 𝑥1とする
部屋の種別、ワンルーム、1DK, 1LDK, 2DK, 3DK….
東京駅からの近さ(m分) ∶ 𝑥2とする
最寄り駅からマンションまでの距離、または時間𝑥3
マンションの階数(1階から30階など)𝑥4
建物の築年数𝑥5
……
これらを使用して、販売価格𝑦万円を予想する
既に色々な販売データが蓄積されているとする。これを𝑡
(教師データとする)
55
56. 特徴の数を1つとしてみる
マンションの広さ(単位平方メートル𝑚2)から販売価格を見積もる
1.5 1.8 2.0 2.1 2.2 2.5 3.0 3.4 3.9 4.0
20 20 24 38 21 30 45 35 33 40
広さ(10𝑚2
)
価格(百万円)
4.4 4.9 6.0 7.0 7.8 8.2 8.5 8.9 9.0 9.1
44 47 40 55 50 70 80 65 53 70
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 10 20 30 40 50 60 70 80 90 100
価格(万円)
広さ(平方メートル)
評価関数は、 𝑦(𝑖)
= 𝑎𝑥(𝑖)
または 𝑦(𝑖)
= 𝑎𝑥(𝑖)
+ 𝑏
誤差関数は、
1
𝑚 0
𝑚−1
𝑦(𝑖)
− 𝑡(𝑖) 2
この問題は、誤差関数(
1
𝑚 0
𝑚−1
𝑦(𝑖)
− 𝑡(𝑖) 2
)を最小にする𝑎と𝑏を見つける
広さ(10𝑚2
)
価格(千万円)
56
57. 線形回帰の勾配降下法(𝑦 = 𝑎𝑥) -1-
まずは、𝑦 = 𝑎𝑥の式を評価関数、
すなわち原点をとおる通る一次直
線に近似できると考えてみます。
グラフ描画
評価関数 𝑦(𝑖)
= 𝑎 × 𝑥(𝑖)
= θ × 𝑥(𝑖)
a のままでもよいのですが、後々のこ
とを考え、 θとしておきます
誤差関数(コスト関数)
𝐶𝑜𝑠𝑡(𝜃) =
1
2𝑚 𝑖=0
𝑚−1
(𝑦(𝑖)
−𝑡 𝑖
)2
単なる1/2は後で計算がちょっと楽に
なるためつけています。
この誤差関数を最小にするのが目
的
アルゴリズムは以下のようになる
1. 誤差関数(コスト)を計算する
2. パラメータの値すなわち上記で
はθの値をちょっとだけ変更し、
誤差関数が小さくなるようにす
る
3. 再度コスト関数を計算する
4. 1. 2~3を、決められた回数ひた
すら繰り返す
5. ここで、θの値をちょっとだけ変
更するというところに"微分"をつ
かいます。 57
58. 線形回帰の勾配降下法(𝑦 = 𝑎𝑥) -2-
誤差関数を微分
𝑓 𝑥 =
1
2𝑚
𝑖=0
𝑚−1
(𝑦(𝑖)
−𝑡 𝑖
)2
𝑑𝑓
𝑑θ
=
𝑑
𝑑θ
1
2𝑚
𝑖=0
𝑚−1
(𝑦 𝑖
−𝑡 𝑖
)2
ここで、𝑦 𝑖
= θ 𝑥(𝑖)
𝑑𝑓
𝑑θ
=
𝑑
𝑑θ
1
2𝑚
𝑖=0
𝑚−1
(θ 𝑥(𝑖)
− 𝑡 𝑖
)2
𝑘 = θ 𝑥(𝑖)
− 𝑡 𝑖
とおくと
𝑑𝑓
𝑑θ
=
𝑑
𝑑θ
1
2𝑚
𝑖=0
𝑚−1
𝑘2
𝑑𝑓
𝑑k
𝑘2
= 2𝑘,
𝑑𝑘
𝑑θ
=
𝑑
𝑑θ
(θ 𝑥(𝑖)
− 𝑡 𝑖
) = 𝑡 𝑖
なので
𝑑𝑓
𝑑θ
=
1
2𝑚
𝑖=0
𝑚−1
2𝑘𝑥(𝑖)
=
1
2𝑚
𝑖=0
𝑚−1
2(θ 𝑥(𝑖)
− 𝑡 𝑖
)𝑥(𝑖)
1
𝑚
𝑖=0
𝑚−1
(θ 𝑥(𝑖)
− 𝑡 𝑖
)𝑥(𝑖)
新しい(ちょっと変更した) θ は
θ:=θ − α
1
𝑚
𝑖=0
𝑚−1
(θ 𝑥(𝑖)
− 𝑡 𝑖
)𝑥(𝑖)
ここで、 α は学習率と呼ばれているもので、θをちょっと変更
する場合の係数になります。
58
θ の初期値を0、学習率を0.0001にしてこれを1000回繰り返す
と、
誤差54.1747009534
θ= 7.53424973 が得られる
結果をプロットしてみると
誤差関数の値も、以下のように収束していることがわかる。
またθと誤差の関係も少なくなっている。
59. 線形回帰の勾配降下法(𝑦 = 𝑎 + 𝑏𝑥)
評価関数は、
𝑦(𝑖)
= 𝑎 + 𝑏 × 𝑥(𝑖)
θ0 + θ1 + 𝑥(𝑖)
= 𝑥 × θ 𝑇
誤差関数(コスト関数)
𝐶𝑜𝑠𝑡(𝜃0, 𝜃1) =
1
2𝑚 𝑖=0
𝑚−1
(𝑦(𝑖)
−𝑡 𝑖
)2
この誤差関数を最小にするのが目的
同様に、降下勾配法により計算する
θ: =θ − α
1
𝑚
𝑖=0
𝑚−1
( 𝑦(𝑖)
− 𝑡 𝑖
)𝑥(𝑖)
θ: =θ − α
1
𝑚
𝑖=0
𝑚−1
(θ0 + θ1 𝑥(𝑖)
− 𝑡 𝑖
)𝑥(𝑖)
θ: =θ − α
1
𝑚
𝑖=0
𝑚−1
( 𝑥(𝑖)
θ 𝑇
− 𝑡 𝑖
)𝑥(𝑖)
前の𝑦 = 𝑎𝑥との違いは、 θが二つθ0、θ1でてくること
そのため正確に書くと、
θ0: =θ0− α
1
𝑚
𝑖=0
𝑚−1
( 𝑥(𝑖)
θ 𝑇
− 𝑡 𝑖
)𝑥(𝑖)
θ1: =θ1− α
1
𝑚
𝑖=0
𝑚−1
( 𝑥(𝑖)
θ 𝑇
− 𝑡 𝑖
)𝑥(𝑖) 59
θ0、θ1の初期値を0、学習率を0.0001にしてこれを1000回
繰り返すと、
誤差48.4287667689
θ0 =1.49231351、 θ1 =7.34188732 が得られる
結果をプロットしてみると
誤差関数の値も、以下のように収束していることがわか
る。またθと誤差の関係も少なくなっている。
60. 特徴の数を2にしてみる
マンションの広さ(単位平方メートル𝑚2)から販売価格を見積もる
評価関数は、 𝑦(𝑖)
= 𝜃0 + 𝜃1 𝑥1
(𝑖)
+ 𝜃2 𝑥2
(𝑖)
𝑥1
(𝑖)
が広さ、 𝑥2
(𝑖)
が東京駅からの距離
誤差関数は、
1
𝑚 0
𝑚−1
𝑦(𝑖)− 𝑡(𝑖) 2
この問題は、誤差関数(
1
𝑛 0
𝑛−1
𝑦𝑖 − 𝑡𝑖
2)を最小にする𝜃0, 𝜃1, 𝜃2 を見つ
ける
1.5 1.8 2.0 2.1 2.2 2.5 3.0 3.4 3.9 4.0
30 20 25 15 40 30 35 50 45 40
20 20 24 38 21 30 45 35 33 40
広さ(10𝑚2
)
価格(百万円)
4.4 4.9 6.0 7.0 7.8 8.2 8.5 8.9 9.0 9.1
40 35 70 55 80 40 60 40 80 70
44 47 40 55 50 70 80 65 53 70
広さ(10𝑚2
)
価格(千万円)
東京駅から
の時間(分)
東京駅から
の時間(分)
60
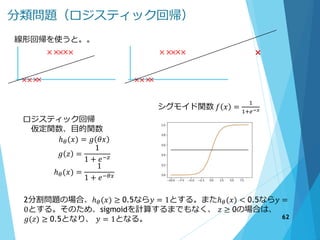
61. 62. 63. 分類問題(ロジスティック回帰:2変数の場合)
ロジスティック回帰
評価関数、目的関数
ℎ 𝜃 = 𝑔 𝜃0 + 𝜃1 𝑥1 + 𝜃2 𝑥2
𝑔 𝑧 =
1
1 + 𝑒−𝑧
ℎ 𝜃 =
1
1 + 𝑒− 𝜃0+𝜃1 𝑥1+𝜃2 𝑥2
ここで最適な、 𝜃0, 𝜃1, 𝜃2を探す
実はこの解は、[-3 1 1]となるが、前ページによると、−3 + 𝑥1 + 𝑥2 ≥ 0と
なれば、ℎθ (𝑥) = 𝑔(𝑧) ≥ 0.5となり、 y = 1。変形すると、 𝑥1 + 𝑥2 ≥ 3を
満たしていればy = 1になる。
ロジスティック回帰・誤差関数
Cost(ℎ 𝜃 𝑥 , 𝑡) =
− log ℎ 𝜃 𝑖𝑓 𝑡 = 1
− log 1 − ℎ 𝜃 𝑖𝑓 𝑡 = 0
これもCost関数を微分して、学習率を掛け
たものを新しいθにすれば、降下勾配法が使
えます。
𝑡 = 1 の時
−log(ℎ 𝜃)
𝑡 = 0 の時
−log(1 − ℎ 𝜃)
63
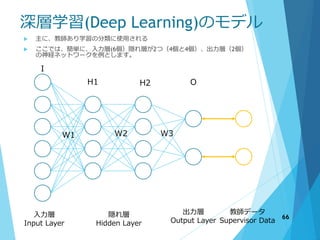
64. 65. 66. 67. 68. 深層学習の手順
入力層 隠れ層 出力層
教師
データ
I
H1 H2 O
W3
2行4列
の行列
B
B
W1
4行7列
の行列
W2
4行5列
の行列
1.初期化
① ウェイトW1, W2, W3を適当な値
で初期化
2.順伝搬 Forward Propagation
① 入力層から隠れ層のノードの値
を計算する。
② 隠れ層が複数ある場合は、左か
ら順に計算し次の層に伝える
③ 出力層まで行う
3. 予想した値と教師データの値を使い、誤差関数(またはコスト関
数)を使用してコストまたは誤差を求める
4. 逆伝搬 Backward Propagation
① 誤差から出力層に入っているウェイトを修正する
② 右から順に隠れ層のウェイトを修正する
③ 入力層から計算したウェイトまで修正する
5. 2.から4.をひたすら繰り返す
68
69. 順伝搬(隠れ層の計算)
入力層 隠れ層 出力層
教師
データ
I
H1 H2 O
W3
2行4列
の行列
B
B
W1
4行7列
の行列
W2
4行5列
の行列
1. 前の層の値をAとすると Z=AWを計算
する
① H1の場合は、Z=I・W1
② H2の場合は、Z=(H1の出力)・W2
2. Zを計算の後、Zに対して、活性化関
数と呼ばれるものを計算する
① 出力=活性化関数(Z)
b
0.7
0.9
1.3
0.4
0.5
0.3
1.2
0.6
0.5
0.4
0.3 0.2
0.7
𝑥 = [0.7 1.2 0.3 0.5 0.4 1.3 ]
[1.0 0.7 1.2 0.3 0.5 0.4 1.3 ]
w1 = [ 0.2
0.3
0.4
0.5
0.6
0.7
0.9 ]
𝑧 = 𝑥・𝑤1
=1.0 × 0.2+0.7 × 0.3 + 1.2 × 0.4 + 0.3 × 0.5
+0.5 × 0.6+0.4 × 0.7 + 1.3 × 0.9 69
70. 順伝搬(隠れ層の計算)
入力層 隠れ層 出力層
教師
データ
I
H1 H2 O
W3
2行4列
の行列
B
B
W1
4行7列
の行列
W2
4行5列
の行列
1. 前の層の値をAとすると Z=AWを計算
する
① H1の場合は、Z=I・W1
② H2の場合は、Z=(H1の出力)・W2
2. Zを計算の後、Zに対して、活性化関
数と呼ばれるものを計算する
① 出力=活性化関数(Z)
3. 活性化関数(Active Function)の種類
① Sigmoid
② ReLU
③ Arc Tangent
ReLU Arc Tangent
70
71. 順伝搬(出力層の計算)
入力層 隠れ層 出力層
教師
データ
I
H1 H2 O
W3
2行4列
の行列
B
B
W1
4行7列
の行列
W2
4行5列
の行列
1. 前の隠れ層の値をAとすると Z=AWを
計算する
① Oの場合は、 Z=(H2の出力)・W3
2. 活性化関数は隠れ層と異なり、
Softmaxと呼ばれる関数を使います
3. Softmaxの計算
ℎ 𝑧 =
𝑒(𝑘)
𝑖=0
𝑛−1
𝑒(𝑖)
ここで、nは出力層の数、例では2。
kは出力層のノードでk =0またはk =1 。
これは何をやってるかというと、 𝑒(𝑥)
は必ず正になりま
す。
それの総和で割っていることにより、出力層の総和は1と
なります。なぜ総和が1がよいかというと、次の誤差関数
の計算と相性がよいためです
𝑒(𝑥)
71
72. 順伝搬(誤差の計算)
入力層 隠れ層 出力層
教師
データ
I
H1 H2 O
W3
2行4列
の行列
B
B
W1
4行7列
の行列
W2
4行5列
の行列
1. 教師データと予想した値からコスト
または誤差を計算します
2. 誤差関数(コスト関数)は、通常ク
ロスエントロピー(Cross Entropy)とい
うものを使います
3. Cross Entropyの計算
𝐸 = −
𝑖=0
𝑛
𝑡(𝑖)
log(𝑦 𝑖
)
ここで、nは出力層の数、例では2。
𝑡(𝑖)はi番目の教師データ
𝑦(𝑖)
は出力層が予想した値
前のページの計算から、 𝑦(𝑖)
は必ず1以下なので、
− log(𝑦 𝑖
)は必ず正の値になります。
ここでは、教師データ𝑡(𝑖)の与え方によってこのコスト値
がどうなるか、後のMNISTの例でみてみます。
−log(𝑥)
72
73. 逆伝搬
入力層 隠れ層 出力層
教師
データ
I
H1 H2 O
W3
2行4列
の行列
B
B
W1
4行7列
の行列
W2
4行5列
の行列
1. 右から左へコスト・誤差を伝搬させ
て、W3, W2, W1の各ウェイトを少し
だけ変更していきます。
2. 隠れ層は、偏微分を使います
1. Cross EntropyとSoftmaxの層の
数値微分ですが、一つのデータだけ
ではなく、バッチで処理を行い右下
の式をコスト計算にするとかなり計
算量が減らせます
2. 隠れ層の編微分
𝐸 =
𝑗=0
𝑚−1
𝑖=0
𝑛
𝑡𝑗
(𝑖)
log(𝑦𝑗
(𝑖)
)
𝐸 =
𝑗=0
𝑚−1
𝑖=0
𝑛
𝑡𝑗
(𝑖)
log(𝑦𝑗
(𝑖)
)
• ReLU
𝜕𝐿
𝜕𝑦
=
1 𝑥 ≥ 0 この場合は、後ろの層の値をそのまま前へ
0 (𝑥 < 0) 前の層には0を渡す
• Sigmoid
𝜕𝐿
𝜕𝑦
= 𝑦 1 − 𝑦 前の層で計算された値𝑦 1 − 𝑦 倍する
このyは順伝搬のときに計算した値を使う
・Arc Tangent
𝜕𝐿
𝜕𝑦
=
1
1 + 𝑦2
73
74. 75. 76. 入力データと予想データ、教師データ
入力データ
764=28x28の1バイトのデータを入力データに
教師データ
MNIST上は、1データにつき1バイトになっているが、教師デー
タは、10個の配列(ベクトル)として扱う。該当する箇所を1
にそれ以外を0にする。これをワン・ホットラベルという。す
なわち、教師データが0の場合は、t[0]=1でそれ以外は0とする。
2の場合は、t[2]=1 でそれ以外の配列は0とする。
予想した、yの値が一番大きなものを正解とします
復習のため、先ほどの、Cross Entropyの計算の部分
𝐸 = −
𝑖=0
𝑛
𝑡(𝑖)log(𝑦 𝑖 )
教師データが0で予想が当たっている場合
t y -log(y) 誤差
1
0
0
0
0
・
・
0.95
0.05
0
0
0
・
・
0.0223
1.3
1.3
∞
∞
・
・
0.0223
0
0
0
0
・
・
教師データが0で予想がはずれている場合
t y -log(y) 誤差
1
0
0
0
0
・
・
0. 05
0
0.05
0.9
0
・
・
1.3
∞
1.3
0.0458
∞
・
・
1.3
0
0
0
0
・
・
76
−log(𝑥)
77. 78. 逆伝搬法以降のアルゴリズムの進化
速く収束するようなとりくみ
畳み込みニューラルネットワーク(CNN: Convolution Neural
Network) Alex Net
バッチ・ノーマライゼーション(Batch Normalization)
ドロップコネクト DropConnect
スキップ構造
http://rodrigob.github.io/are_we_there_yet
/build/classification_datasets_results.html#
4d4e495354
MNISTを使った手書き文字の認識率
Regularization of Neural Networks using
DropConnect 2013
http://cs.nyu.edu/~wanli/dropc/
99.79% (2017/08/02現在)
78
79. 80. 81. 82. 83. 84. ボードゲーム一覧
84
ゲーム 盤
ゲーム中に現
れる局面の数
AIがトッププロに勝った年 特徴
三目並べ 3 x 3 9!=362,880
対称性を考慮
すると、
27,143
木構造が書けるため、しら
みつぶし探索可能。
チェス 8 x 8 10120 1997
Deep Blue vs Garry
Kasparov
ロジックがわかりやすい
将棋 9 x 9 10226 2014 ツツカナ vs 森下卓九
段九段に初勝利
2016 ponanza vs 山崎隆之
叡王 2-0
2017 ponanza vs佐藤天彦
叡王 2-0
モンテカルロ法
ロジスティック回帰→
ディープラーニング
強化学習
囲碁 19 x 19 10360 2016 AlphaGo vs 李世乭 4-1
2017 AlphaGo vs 柯潔 3-0
モンテカルロ法
CNN
強化学習
ダイヤモンド社の書籍オンライン
人工知能はどのようンいして「名人」を超えたのか?山本一成著より
なお、トッププロの定義と年についてはそれらしい年にしました
85. 木構造、三目並べ
全部で、9!なるが、対称性を考えと
最初の手は、
最初に打てる手は
最初は手で書けるかと思ったのですが、面倒そうだったので、
コードで書いてみた
https://github.com/mbenzaki/Sanmoku
https://raw.githubusercontent.com/mbenzaki/Sanmoku/master/San
moku/result.txt 85
(1)
○ ○○
横線を引く
と(1)と対称
○
○ ○
○
縦線を引く
と(1)と対称
斜線を引く
と(1)と対称
左の4つの手はすべ
て対称であるため、
同じものとみなせる
○
○ ○
対称性を考慮する
と、先手〇の打てる
箇所は左の3つしか
ありません。後の6
箇所はすべてこれら
の対称です
86. 87. 将棋
チェスに比べ、評価関数の記述が難しい
局面が大すぎるので、今のところ完全解は見つけられていな
い
ponanzaは、1億個のパラメータを使ったロジスティック回帰
+強化学習で、佐藤名人に2連勝、今は深層学習に変更された
ただし、コンピュータ同士の対戦では、2位
87
https://ja.wikipedia.org/wiki/Ponanza
1位
ponanzaのプロ棋士との対決時
OS:Windows 10 Home 64bit (Linux の使用を希望する
場合は、コンピュータ予選初日の前日に各自で OS 換装を行
うこと)
CPU:Core i7-6700
メモリ:32GB DDR4
ストレージ: SSD 480GB + HDD 2TB
グラフィックボード:NVIDIA GeForce GTX1060 6GB
http://www2.computer-
shogi.org/wcsc27/appeal/Ponanza_Chainer/Ponanza_Chainer.pdf
ponanza Chainerの学習時の構成
「さくらインターネット高火力コンピューティング」を
使用
最大火力で勝負
CPU 1092cpu(Xeon)
GPU 128基(Maxwell TITAN X)
88. 碁
将棋に比べても評価関数の記述が難しい→Give Up
碁石の白、黒を画像として認識すること(深層学習:CNN)
と強化学習(Deep Q Network)で
2016 AlphaGo vs 李世乭 4-1
2017 AlphaGo vs 柯潔 3-0
88
最強囲碁AI アルファ碁 解体新書 深層学習、モンテカルロ木探索、強化学習から見たその
仕組み 大槻 知史 (著), 三宅 陽一郎 (監修)
89. 90. 91. 92. 雲の中のこびとさん
(siri, スマートスピーカー、ボット)
• 松村太郎さんのブログ(2017/7/6)
• Amazonの人工知能は加速度的に賢くなっている—Alexaのスキルが15000に到
達(https://tarosite.net/amazon-alexa-got-15000-skills-d44f84900964)
• 確かにAlexaにはSkillはたくさんあるのですが、初めての指示に対しては、
Skillをスマホアプリから追加しろ、と冷たい反応が返ってきます。それより
は、Google検索を声で行うような感覚のGoogle Homeのほうが、現状役に
立っている、という印象です
• ソニーとパナソニックからもスマートスピーカ--Googleアシスタント2017/9/1
https://japan.cnet.com/article/35106637/
92
93. 94. 95. AIを使った人事制度
ソフトバンクが新卒の「ES選考」をAIに任せた理由
http://www.itmedia.co.jp/business/articles/1708/29/news011.html
人工知能 入社試験の選考でも導入 2016年8月25日 付け毎日新聞
https://mainichi.jp/articles/20160825/k00/00m/020/139000c
NEC
NECのシステムは昨年12月に開発。過去に入社試験を受けた約2000人分の履
歴書データと合否結果があれば、その企業がどんな人材を採用してきたかをAIが学
習する。AIはこれらのデータをもとに、入社志望者の履歴書の記載内容を分析し、
採用方針に合致する人材を選び出す。
既に人材紹介会社が顧客企業と求職者をマッチングするために使うなど導入が始まっ
ている。今後の改良で学習の精度が高まれば、AIによる採用候補者の絞り込みが一
段と進み、事実上の1次面接までAIが担うことも可能になる。NECは「客観的な
判断ができる点をアピールし、来年度中にさらに10社程度での導入を目指す」と話
す。
ただ、志望者が採用に有利になりそうな虚偽の内容を履歴書に書いても、現時点でA
Iがそれを見抜くのは難しい。NECは「最終的には人間による面接が必要」と説明
する。
人材紹介のビズリーチ(東京都)
ビズリーチも来年から、AIが人事評価をするシステムを販売。2019年6月まで
に2000社以上の導入を目指す。
採用や人事でのAIの活用は「感情を挟まずに評価できる」(ビズリーチ)利点があ
るが、千葉商科大の常見陽平専任講師(労働社会学)は「頼り過ぎると画一的な人材
が増え、組織に多様性がなくなる可能性がある。最後は人間の目で評価すべきだ」と
指摘する。
95
96. 97. 特化型AIと汎用AI
現在あるのは特化型AI
汎用AIというのは突き詰めれば人間の脳を実現すること
汎用型AIの難しさ
技術的に難しい
特化型AIだけではつくれない。特化型AIを司るものが必要
自発的に情報を取得しないといけない。
ネットにないものはどうやって学習させる?(人間が教える!)
フレーム問題(横断歩道、右をみて、左見て、右みて、車がいると渡れない、
いつまでたっても渡れない)
哲学、倫理の問題
心ってどうやってモデルにする?
第六感ってある?
ロボット3原則
自動運転が事故を起こす直前、怪我する人数を減らせるとして、搭乗者・通行
人どちらを守るべきか?
脳をデータ化して保存することの倫理性
政治、法律の問題
自動運転の車が事故をおこすとだれの責任? 97
98. Deep Mind社の論文
Deep MindはGoogle傘下のAlpha Goを作った会社
2013年から2015年頃は碁がプロの棋士に勝つのは10年かかると
言われていた。
2017年には、人類最強のプロ棋士(柯潔)と 3-0で完勝、2年で
プロ棋士に勝つ
2017年、柯潔対決後、公式の場でプロ棋士との対決は終了と宣
言
Deep Mind社の論文
https://deepmind.com/research/publications/
The hippocampus as a predictive map:予測マップとしての海馬
The successor representation in human reinforcement
learning:人間の強化学習における次の表現
Neuroscience-Inspired Artificial Intelligence:神経科学に鼓吹さ
れた人工知能
Learning human behaviors from motion capture by adversarial
imitation:敵対的模倣によるモーションキャプチャからの人間
の行動の学習 98
99. Top Trends in the Gartner Hype Cycle for Emerging Technologies, 2017
Source from Gartner(http://www.gartner.com/smarterwithgartner/top-trends-in-
the-gartner-hype-cycle-for-emerging-technologies-2017/)
イノベーション
トリガー
インフレ期待
のピーク
幻滅の谷間 啓蒙のスロープ 生産性の進歩
99
100. 101. 文献
機械学習全般
Machine Learning – Sandford University at Coursera
https://www.coursera.org/learn/machine-learning
日本語の字幕がついています
全部で11週かかります(だいたい一週間3時間)
MIT Press Machine Learning
オンライン http://www.deeplearningbook.org/
日本語訳 http://www.deeplearningbook.me/
英語版で800ページ以上あります
Udemy
【世界で3万人以上が受講】実践データサイエンス&機械学習 with
Python
https://www.udemy.com/datascience-
machinelearning/learn/v4/overview
Amazonで長年レコメンドシステムの開発に携わった、Frank Kane
が教えるデータサイエンスと機械学習のコースの日本語版(値段は
時期によって異なります)
深層学習
ゼロから作る Deep Learning 斉藤康穀 著
101
102. 文献
Framework:
TensorFlow
TensorFlowはじめました 実践!最新Googleマシンラーニング
Kindle 1080円
Udemy [4日で体験] TensorFlow x Python3 で学ぶディープラー
ニング
https://www.udemy.com/tensorflow/learn/v4/overview
TensorFlow HP
https://www.tensorflow.org/
それ以外にも
http://qiita.com/ にはいっぱい情報があります
102
















































![機械学習のことば
Scholar (スカラー)
一つの実数、例えば、1.0 とか0.0とか𝜋とか𝑒
𝑒はネイピア数(= 2.71828182846)と呼ばれ、 𝑒 𝑥
を𝑥で微分しても
𝑒 𝑥
となる。(𝑒 𝑥
)′
= 𝑒 𝑥
または、
𝑑
𝑑𝑥
𝑒 𝑥
= 𝑒 𝑥
と記述
Vector (ベクトル、ベクター)
スカラが集まった一次元の数字の集まり、横に並べることが多い
[1.0, 2.0, 3.0], [0, 0, 0, 0, 0] などなど
Matrix (行列、マトリックス)
2次元のスカラを並べたもの
1 2 3
4 5 6
は2行3列で2×3の行列とよ
ぶ
スカラは1×1の行列、ベクトルは1×N(またはN×1 )の行列
Tensor(テンソル、テンサー)
上記の概念をひっくるめたもの、上記の総称
階数0がスカラー、階数1がベクター、階数2が行列
49](https://image.slidesharecdn.com/20171015mosamachinelearning-171209143733/85/20171015-mosa-machine-learning-49-320.jpg)
![機械学習の数学(行列)
行列の(内)積
𝑎 =
𝑎11 𝑎12 𝑎13
𝑎21 𝑎22 𝑎23
, 𝑏 =
𝑏11 𝑏12
𝑏21 𝑏22
𝑏31 𝑏32
の場合、
c=𝑎・𝑏 =
𝑎11 𝑏11 + 𝑎12 𝑏21 +𝑎13 𝑏31 𝑎11 𝑏12 + 𝑎12 𝑏22 +𝑎13 𝑏32
𝑎21 𝑏11 + 𝑎22 𝑏21 +𝑎23 𝑏31 𝑎21 𝑏12 + 𝑎22 𝑏22 +𝑎23 𝑏32
𝑚× 𝑛の行列と𝑛× 𝑘の行列の積は𝑚 × 𝑘の行列となる(前の行列の列数と
後ろの行列の行数が同じでないものは積は計算できない)
すなわち、Cで記述すると、
for (i=0; i<M; ++i) {
for ( j=0; j<K; ++j) {
c[i][j] = 0;
for ( l=0; l<N; ++l) {
c[i][j] += a[i][l]*b[l][j];
}
}
}
転置行列
M×Nの行列の転置行列は、N×Mの行列。行と列を反対にしたも
の
50](https://image.slidesharecdn.com/20171015mosamachinelearning-171209143733/85/20171015-mosa-machine-learning-50-320.jpg)











![分類問題(ロジスティック回帰:2変数の場合)
ロジスティック回帰
評価関数、目的関数
ℎ 𝜃 = 𝑔 𝜃0 + 𝜃1 𝑥1 + 𝜃2 𝑥2
𝑔 𝑧 =
1
1 + 𝑒−𝑧
ℎ 𝜃 =
1
1 + 𝑒− 𝜃0+𝜃1 𝑥1+𝜃2 𝑥2
ここで最適な、 𝜃0, 𝜃1, 𝜃2を探す
実はこの解は、[-3 1 1]となるが、前ページによると、−3 + 𝑥1 + 𝑥2 ≥ 0と
なれば、ℎθ (𝑥) = 𝑔(𝑧) ≥ 0.5となり、 y = 1。変形すると、 𝑥1 + 𝑥2 ≥ 3を
満たしていればy = 1になる。
ロジスティック回帰・誤差関数
Cost(ℎ 𝜃 𝑥 , 𝑡) =
− log ℎ 𝜃 𝑖𝑓 𝑡 = 1
− log 1 − ℎ 𝜃 𝑖𝑓 𝑡 = 0
これもCost関数を微分して、学習率を掛け
たものを新しいθにすれば、降下勾配法が使
えます。
𝑡 = 1 の時
−log(ℎ 𝜃)
𝑡 = 0 の時
−log(1 − ℎ 𝜃)
63](https://image.slidesharecdn.com/20171015mosamachinelearning-171209143733/85/20171015-mosa-machine-learning-63-320.jpg)




![順伝搬(隠れ層の計算)
入力層 隠れ層 出力層
教師
データ
I
H1 H2 O
W3
2行4列
の行列
B
B
W1
4行7列
の行列
W2
4行5列
の行列
1. 前の層の値をAとすると Z=AWを計算
する
① H1の場合は、Z=I・W1
② H2の場合は、Z=(H1の出力)・W2
2. Zを計算の後、Zに対して、活性化関
数と呼ばれるものを計算する
① 出力=活性化関数(Z)
b
0.7
0.9
1.3
0.4
0.5
0.3
1.2
0.6
0.5
0.4
0.3 0.2
0.7
𝑥 = [0.7 1.2 0.3 0.5 0.4 1.3 ]
[1.0 0.7 1.2 0.3 0.5 0.4 1.3 ]
w1 = [ 0.2
0.3
0.4
0.5
0.6
0.7
0.9 ]
𝑧 = 𝑥・𝑤1
=1.0 × 0.2+0.7 × 0.3 + 1.2 × 0.4 + 0.3 × 0.5
+0.5 × 0.6+0.4 × 0.7 + 1.3 × 0.9 69](https://image.slidesharecdn.com/20171015mosamachinelearning-171209143733/85/20171015-mosa-machine-learning-69-320.jpg)






![入力データと予想データ、教師データ
入力データ
764=28x28の1バイトのデータを入力データに
教師データ
MNIST上は、1データにつき1バイトになっているが、教師デー
タは、10個の配列(ベクトル)として扱う。該当する箇所を1
にそれ以外を0にする。これをワン・ホットラベルという。す
なわち、教師データが0の場合は、t[0]=1でそれ以外は0とする。
2の場合は、t[2]=1 でそれ以外の配列は0とする。
予想した、yの値が一番大きなものを正解とします
復習のため、先ほどの、Cross Entropyの計算の部分
𝐸 = −
𝑖=0
𝑛
𝑡(𝑖)log(𝑦 𝑖 )
教師データが0で予想が当たっている場合
t y -log(y) 誤差
1
0
0
0
0
・
・
0.95
0.05
0
0
0
・
・
0.0223
1.3
1.3
∞
∞
・
・
0.0223
0
0
0
0
・
・
教師データが0で予想がはずれている場合
t y -log(y) 誤差
1
0
0
0
0
・
・
0. 05
0
0.05
0.9
0
・
・
1.3
∞
1.3
0.0458
∞
・
・
1.3
0
0
0
0
・
・
76
−log(𝑥)](https://image.slidesharecdn.com/20171015mosamachinelearning-171209143733/85/20171015-mosa-machine-learning-76-320.jpg)

























![文献
Framework:
TensorFlow
TensorFlowはじめました 実践!最新Googleマシンラーニング
Kindle 1080円
Udemy [4日で体験] TensorFlow x Python3 で学ぶディープラー
ニング
https://www.udemy.com/tensorflow/learn/v4/overview
TensorFlow HP
https://www.tensorflow.org/
それ以外にも
http://qiita.com/ にはいっぱい情報があります
102](https://image.slidesharecdn.com/20171015mosamachinelearning-171209143733/85/20171015-mosa-machine-learning-102-320.jpg)
![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)











































![[輪講] 第1章](https://cdn.slidesharecdn.com/ss_thumbnails/random-171231020415-thumbnail.jpg?width=640&height=640&fit=bounds)


