Download to read offline










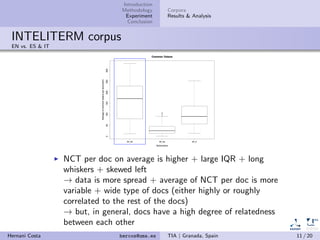










This document summarizes an experiment on measuring relatedness between documents in comparable corpora using distributional similarity measures (DSMs). It finds that DSMs like common tokens (NCT) and Chi-square performed well in filtering out unrelated documents from specialized corpora in English and Italian, but not for the Spanish corpus which appeared to contain less related documents to begin with. The study aims to help automatically describe and evaluate comparable corpora quality by ranking documents based on their relatedness.















































