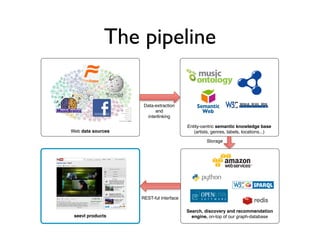
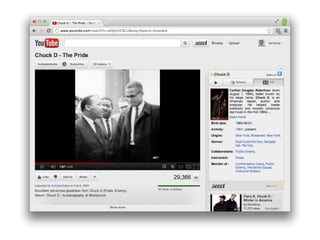
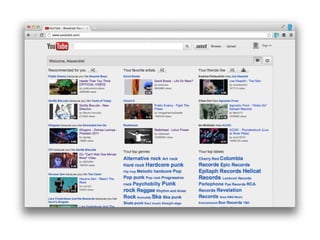
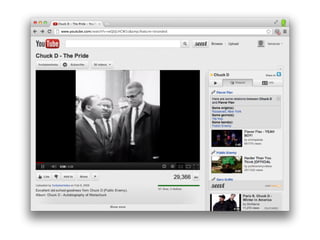
The document discusses Seevl, a data-driven music discovery platform led by co-founder Alexandre Passant. It outlines the technical architecture, challenges faced, and solutions employed, including the use of semantic web technologies and user-centric design principles. Key topics include data extraction, recommendations, user experience, and scalability using SPARQL and Redis for efficient query handling.






































![Bio ontologies and semantic technologies[2]](https://cdn.slidesharecdn.com/ss_thumbnails/bioontologiesandsemantictechnologies2-180509123734-thumbnail.jpg?width=640&height=640&fit=bounds)







































































