Downloaded 345 times

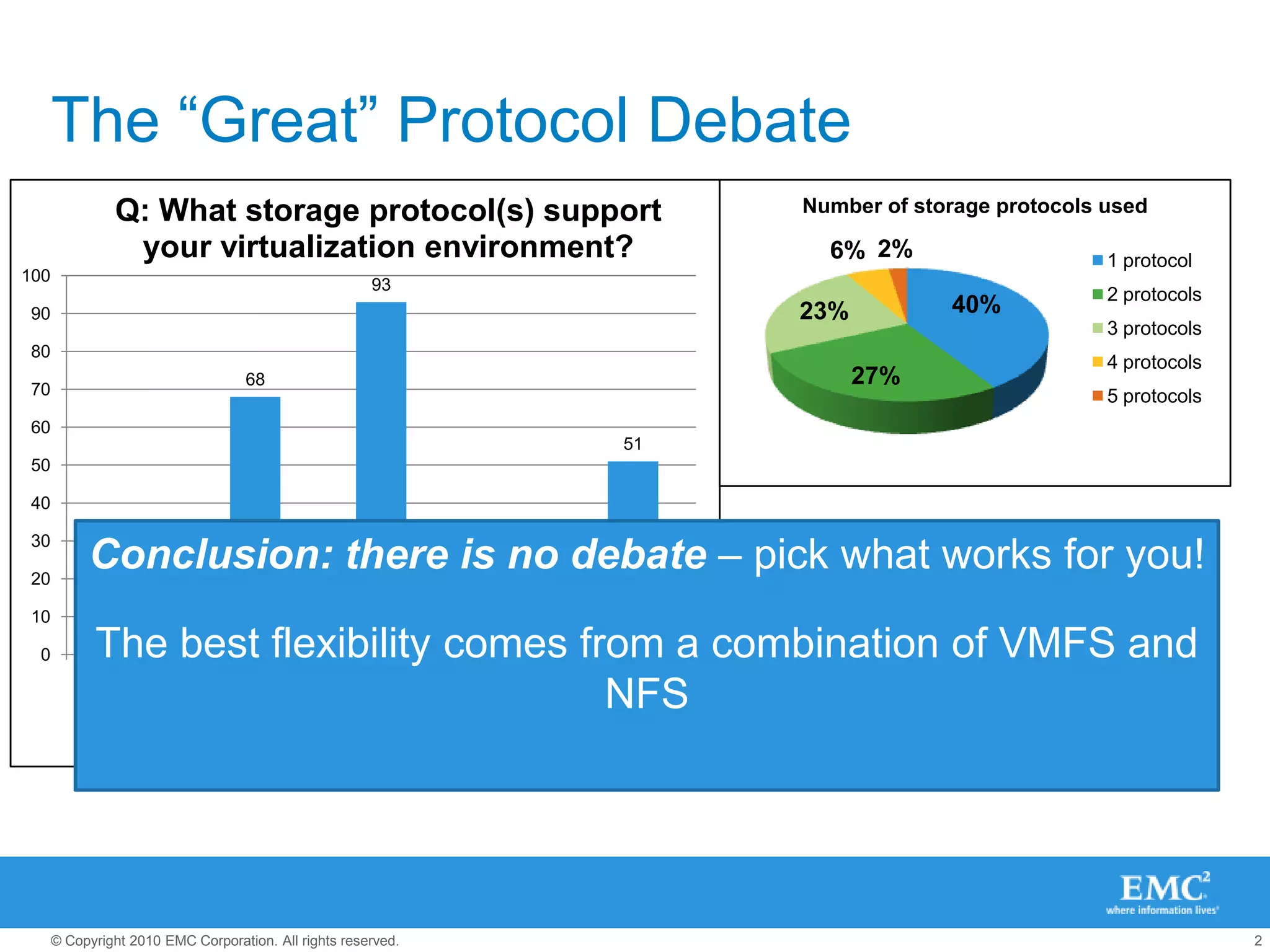





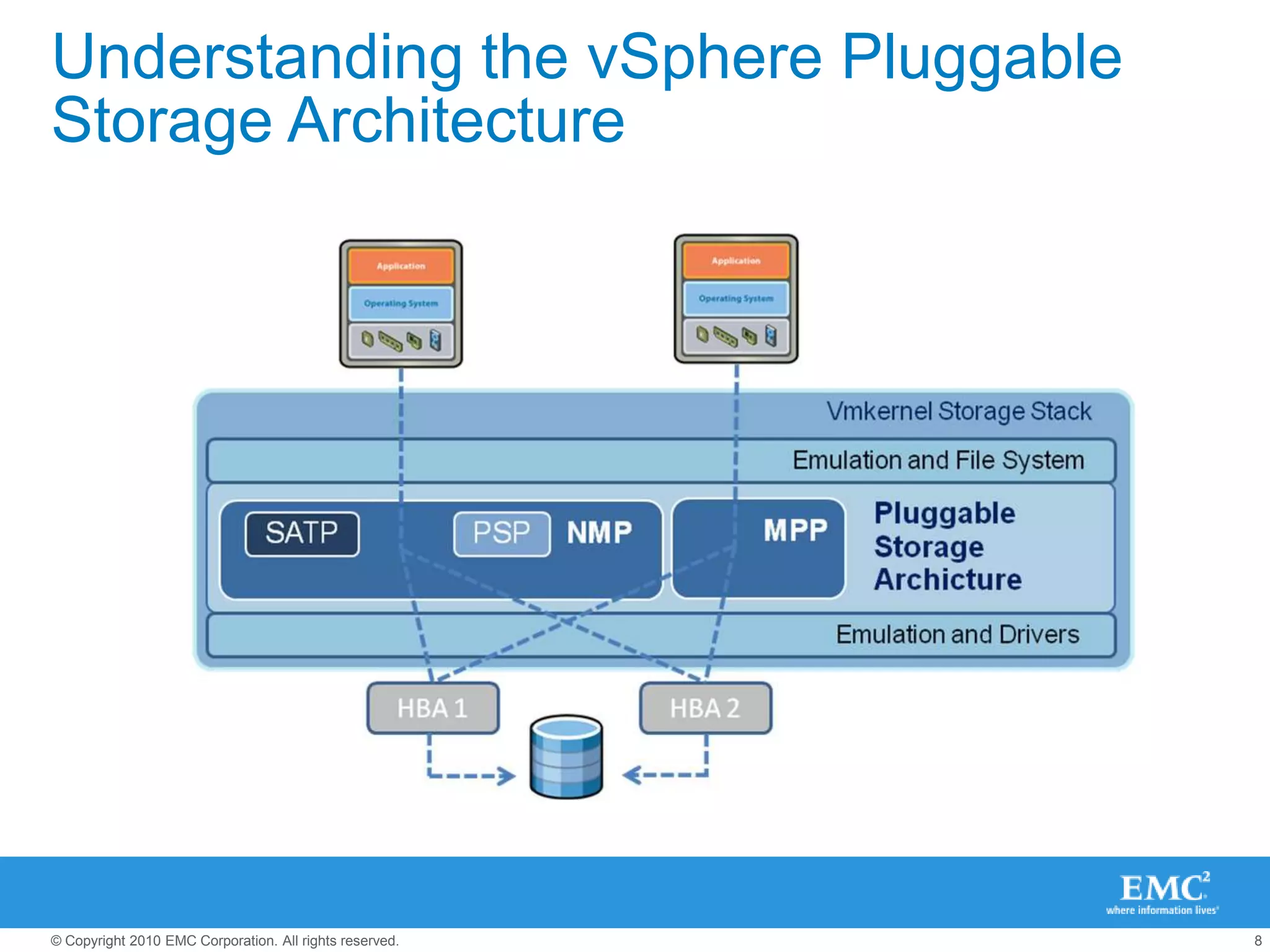
![What’s “out of the box” in vSphere 4.1?[root@esxi ~]# vmware -vVMware ESX 4.1.0 build-260247 [root@esxi ~]# esxcli nmp satp listName Default PSP DescriptionVMW_SATP_SYMM VMW_PSP_FIXED Placeholder (plugin not loaded)VMW_SATP_SVC VMW_PSP_FIXED Placeholder (plugin not loaded)VMW_SATP_MSA VMW_PSP_MRU Placeholder (plugin not loaded)VMW_SATP_LSI VMW_PSP_MRU Placeholder (plugin not loaded)VMW_SATP_INV VMW_PSP_FIXED Placeholder (plugin not loaded)VMW_SATP_EVA VMW_PSP_FIXED Placeholder (plugin not loaded)VMW_SATP_EQL VMW_PSP_FIXED Placeholder (plugin not loaded)VMW_SATP_DEFAULT_AP VMW_PSP_MRU Placeholder (plugin not loaded)VMW_SATP_ALUA_CX VMW_PSP_FIXED_AP Placeholder (plugin not loaded)VMW_SATP_CX VMW_PSP_MRU Supports EMC CX that do not use the ALUA protocolVMW_SATP_ALUA VMW_PSP_RR Supports non-specific arrays that use the ALUA protocolVMW_SATP_DEFAULT_AA VMW_PSP_FIXED Supports non-specific active/active arraysVMW_SATP_LOCAL VMW_PSP_FIXED Supports direct attached devices](https://image.slidesharecdn.com/2010-12-06-midwest-reg-vmug-101206110506-phpapp01/75/Next-Generation-Best-Practices-for-VMware-and-Storage-9-2048.jpg)

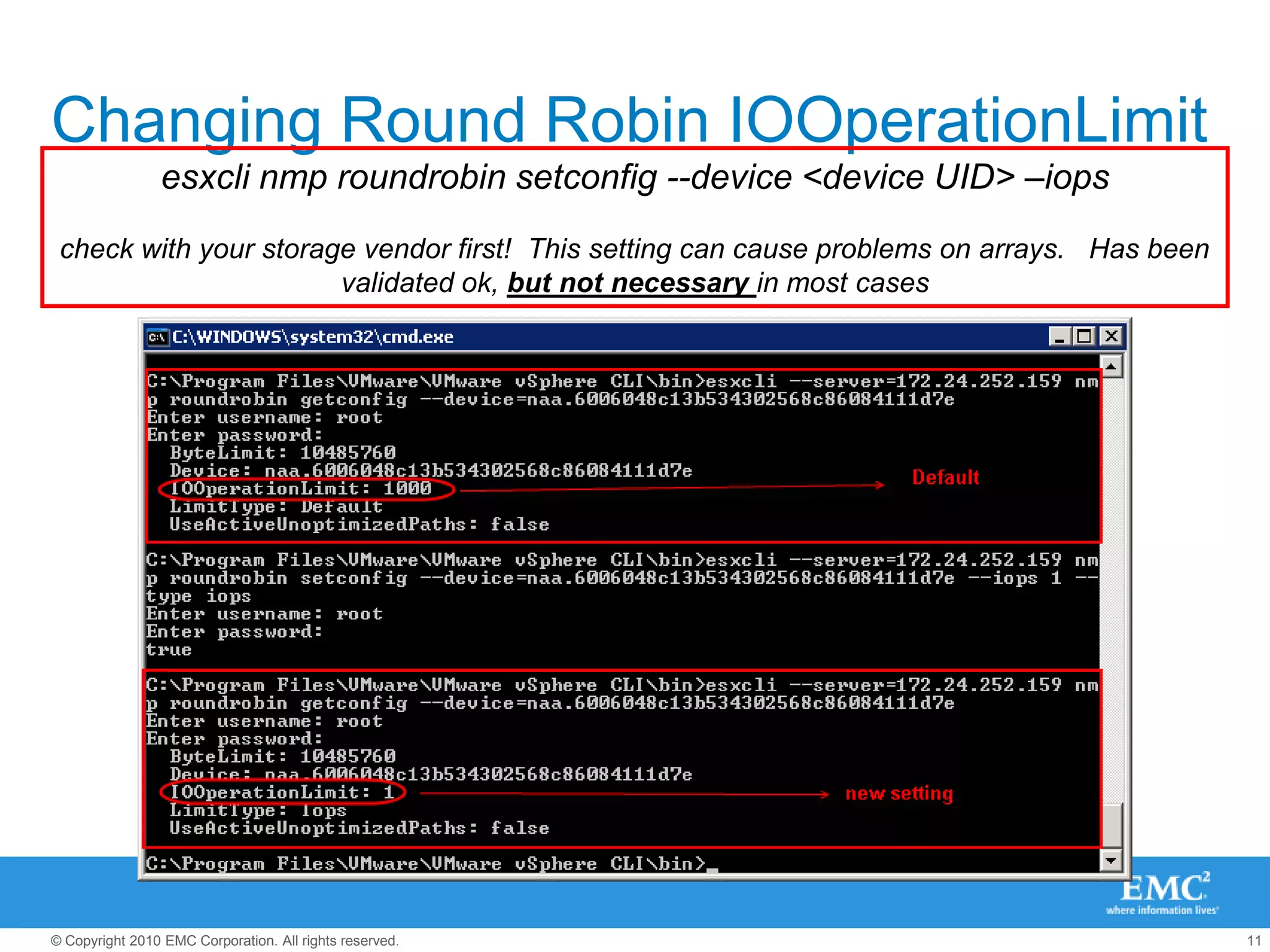

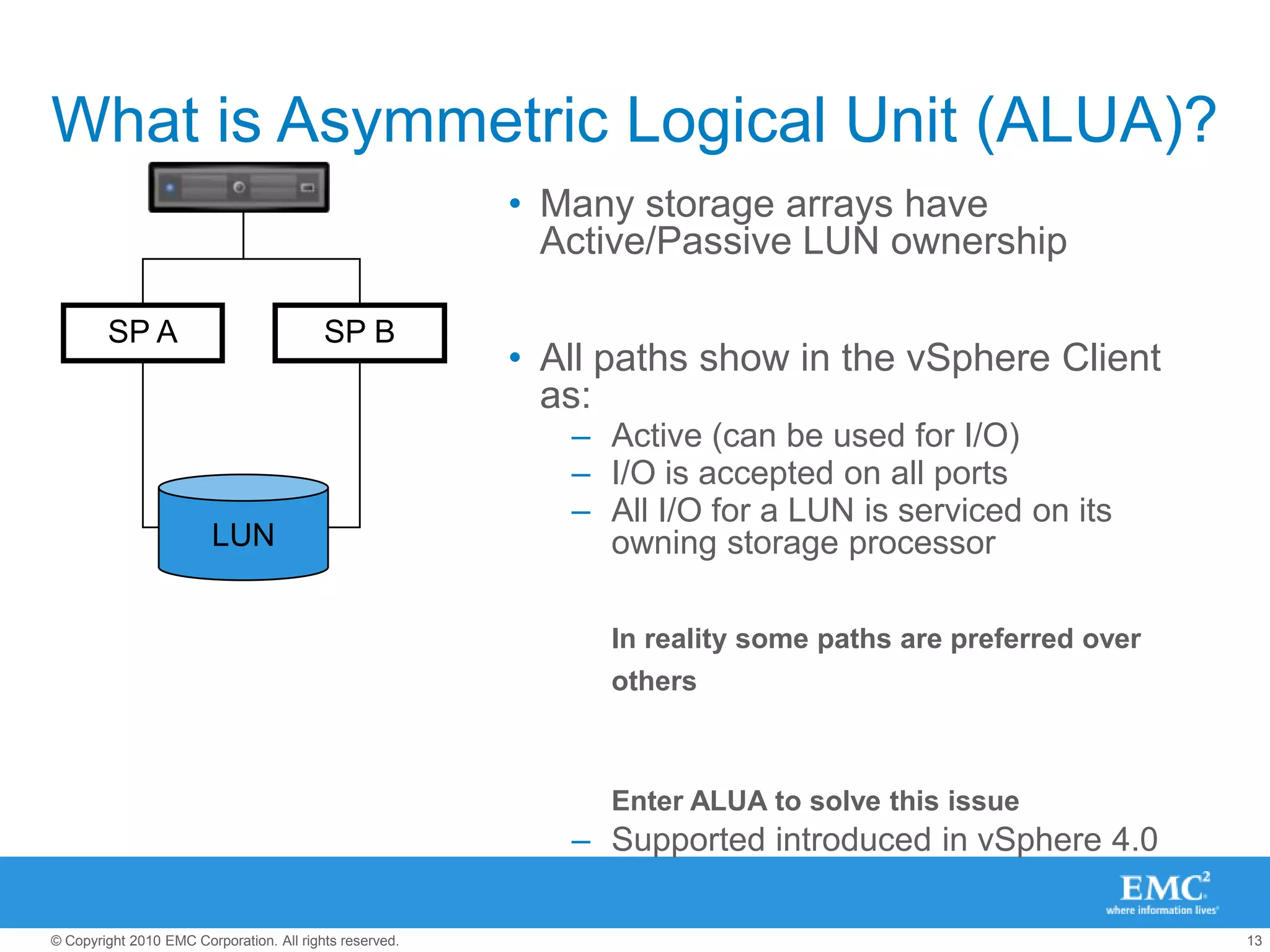

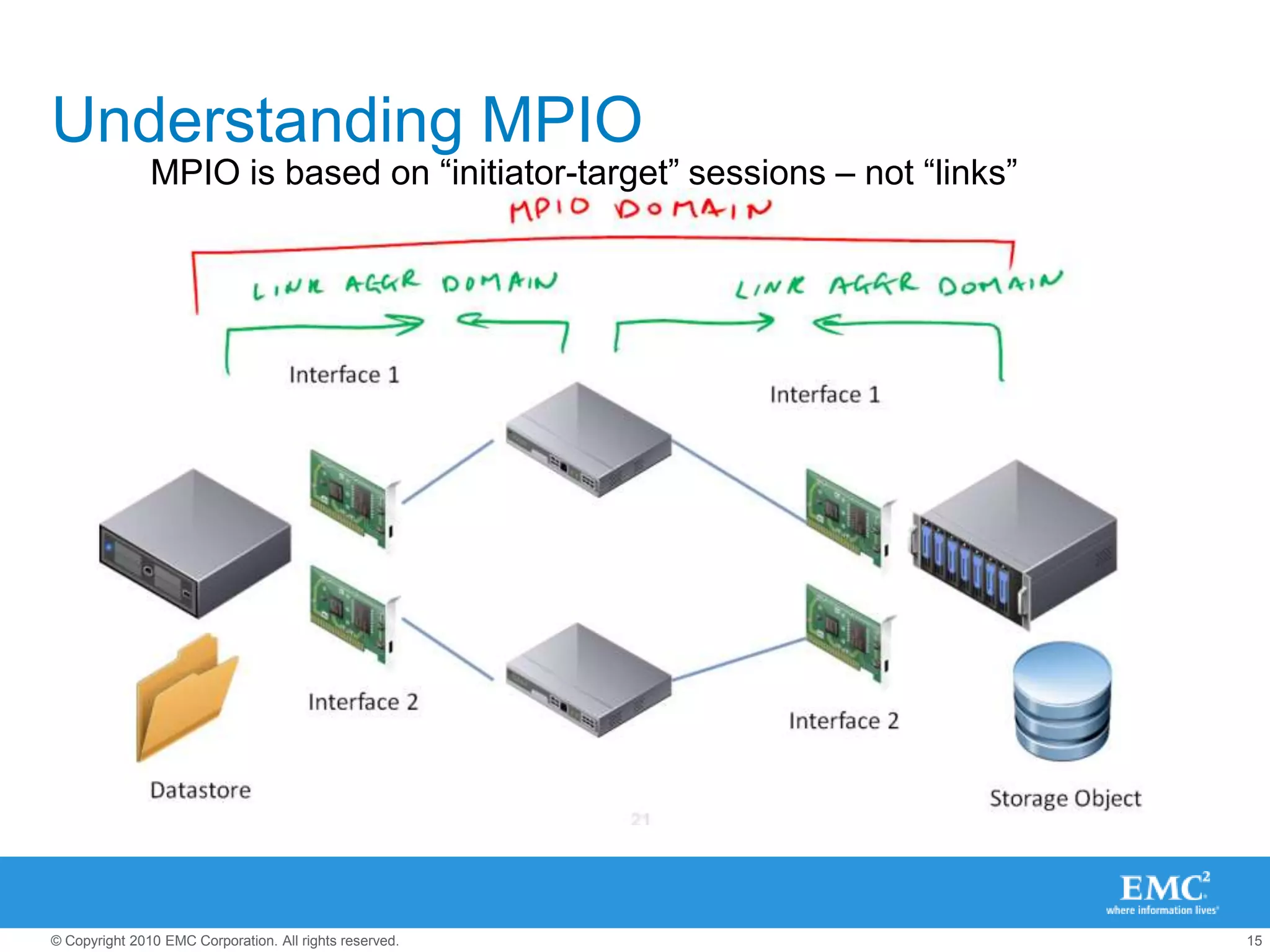

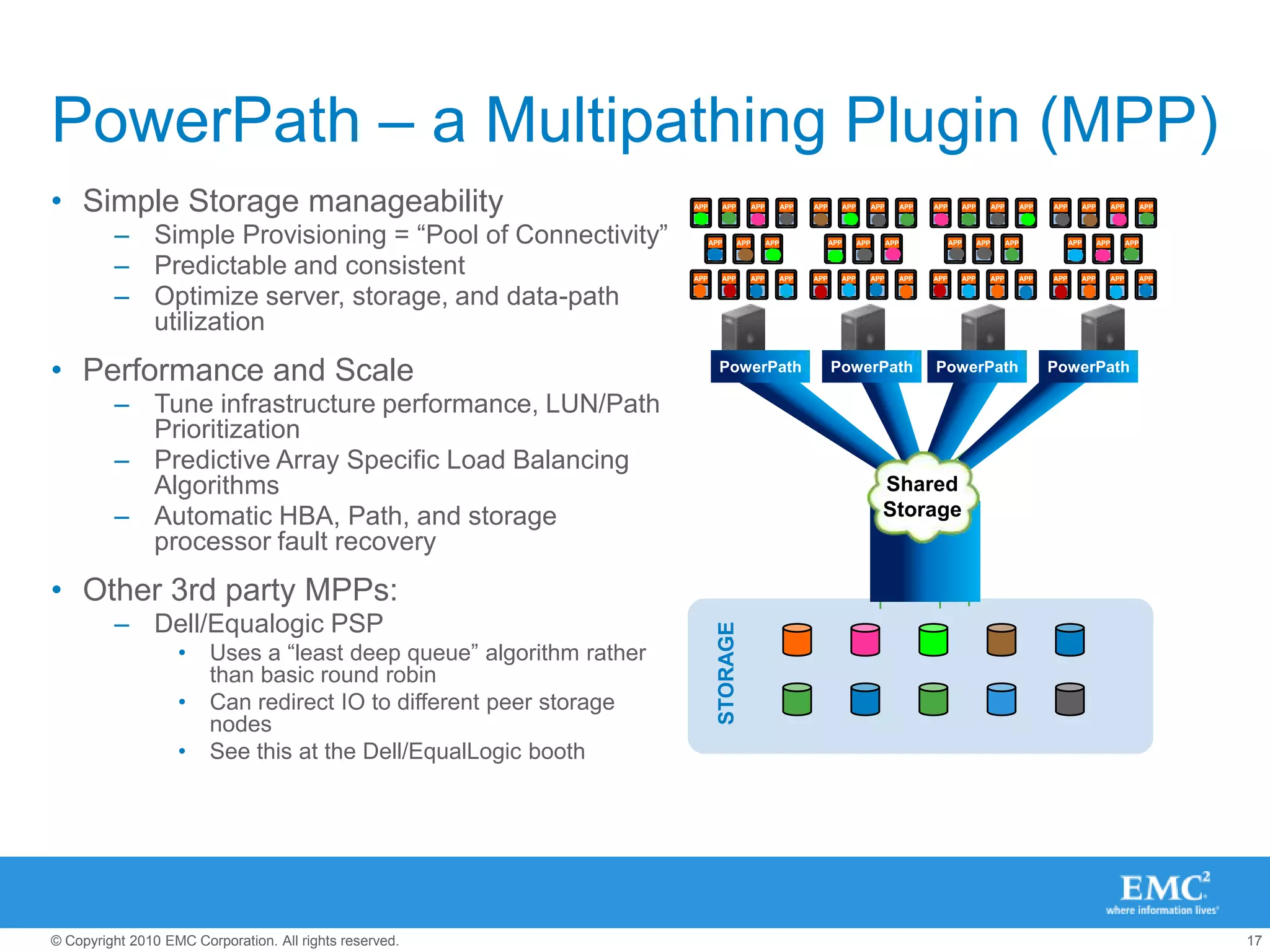


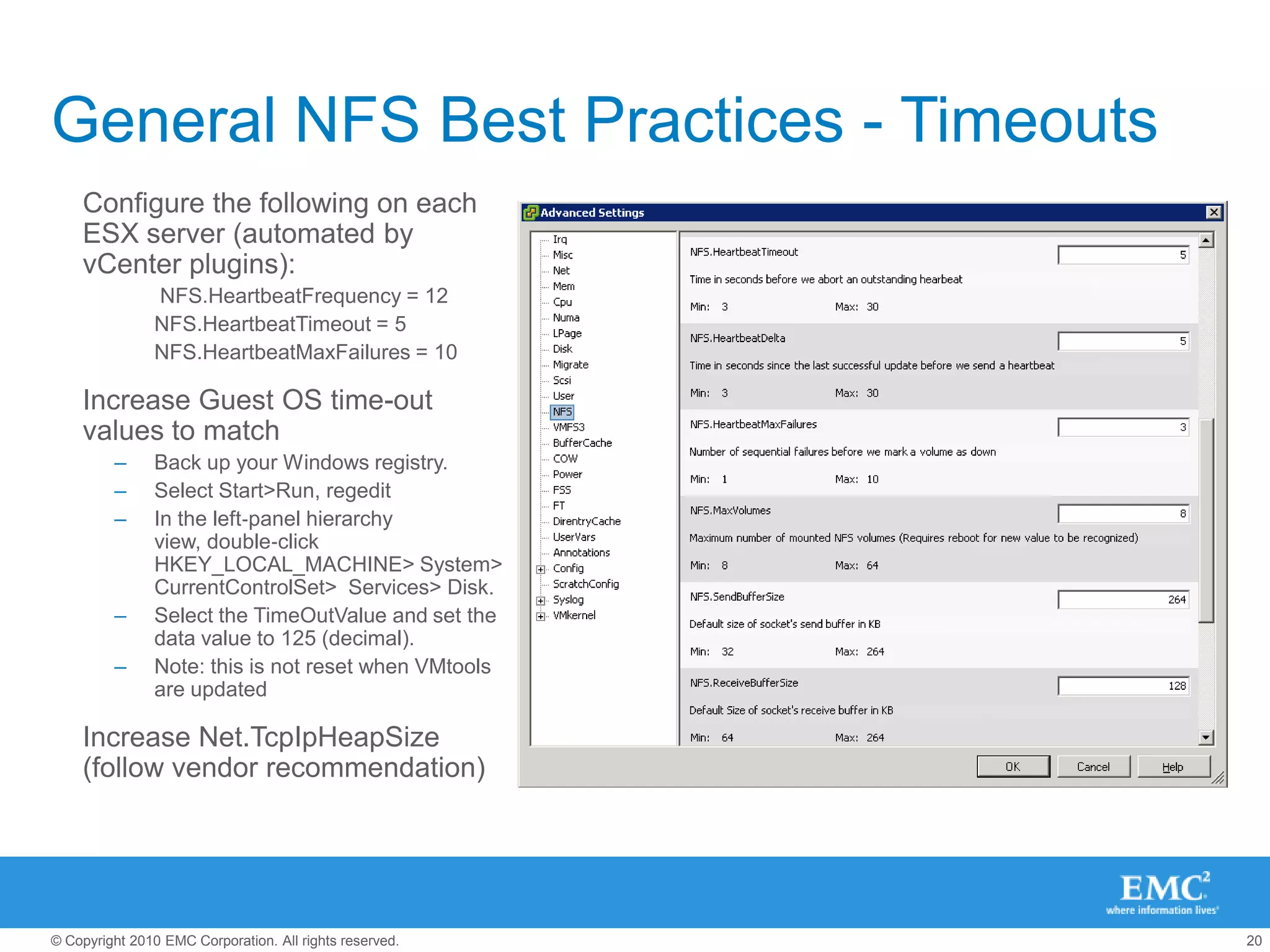
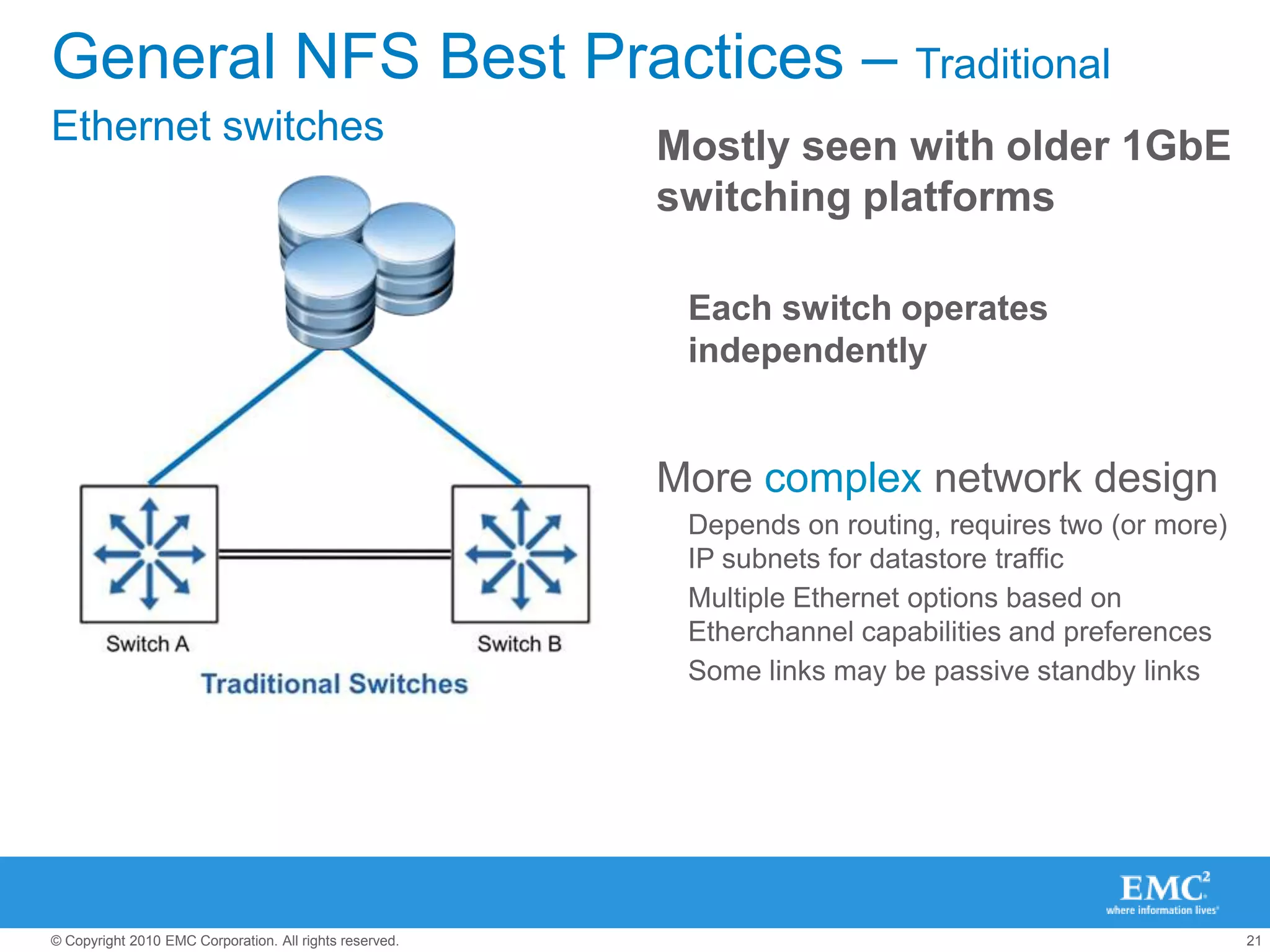
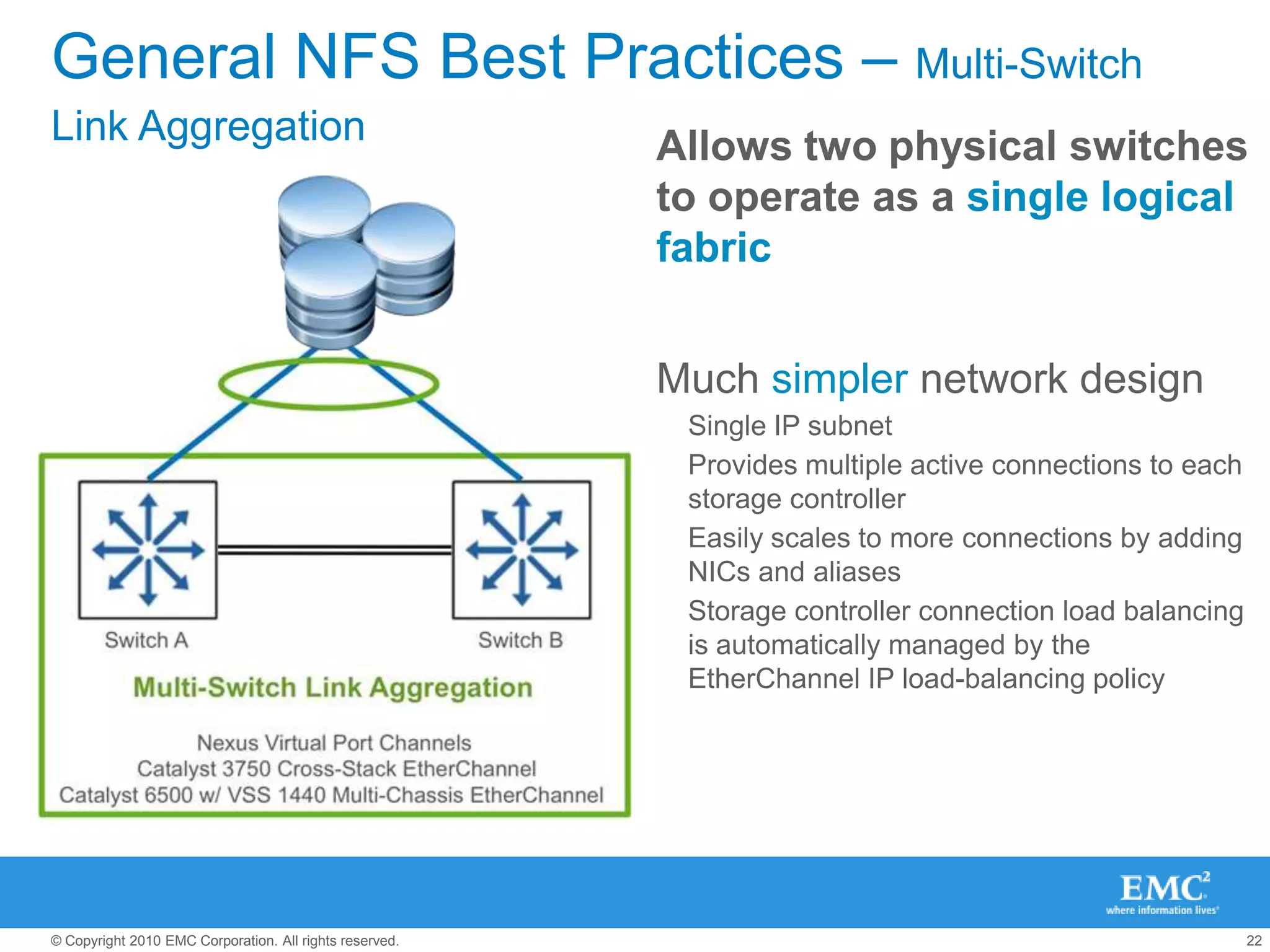
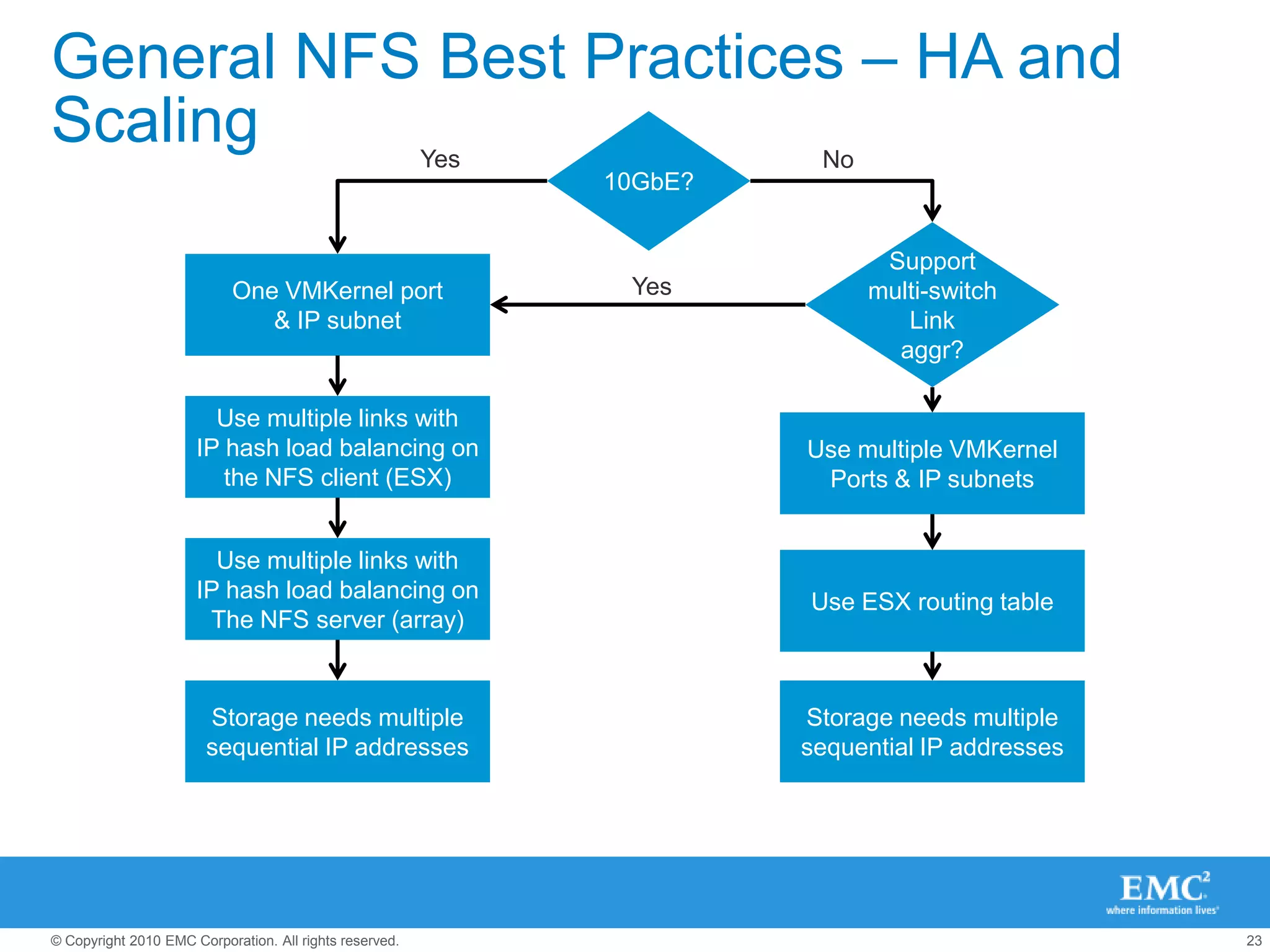
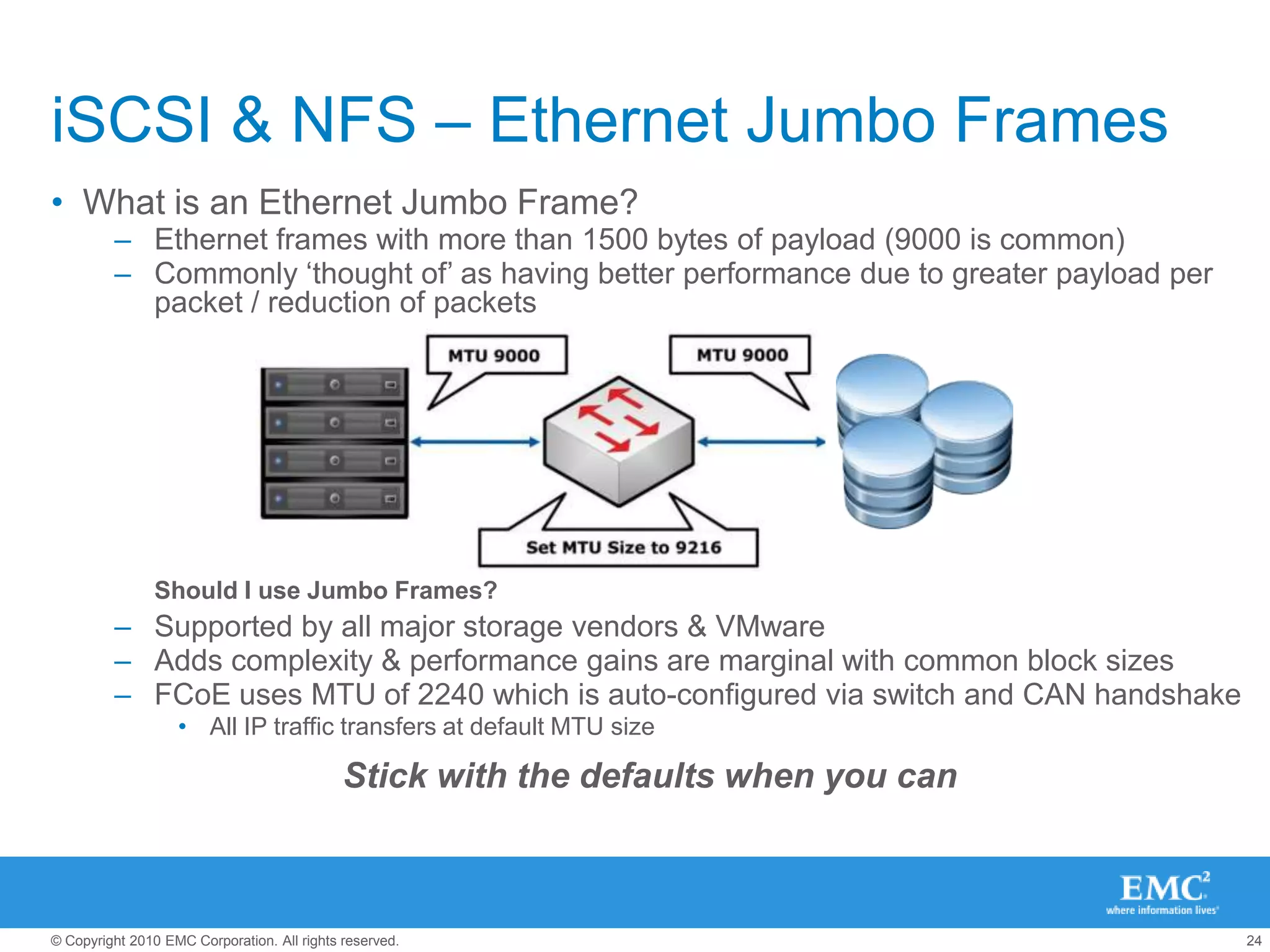





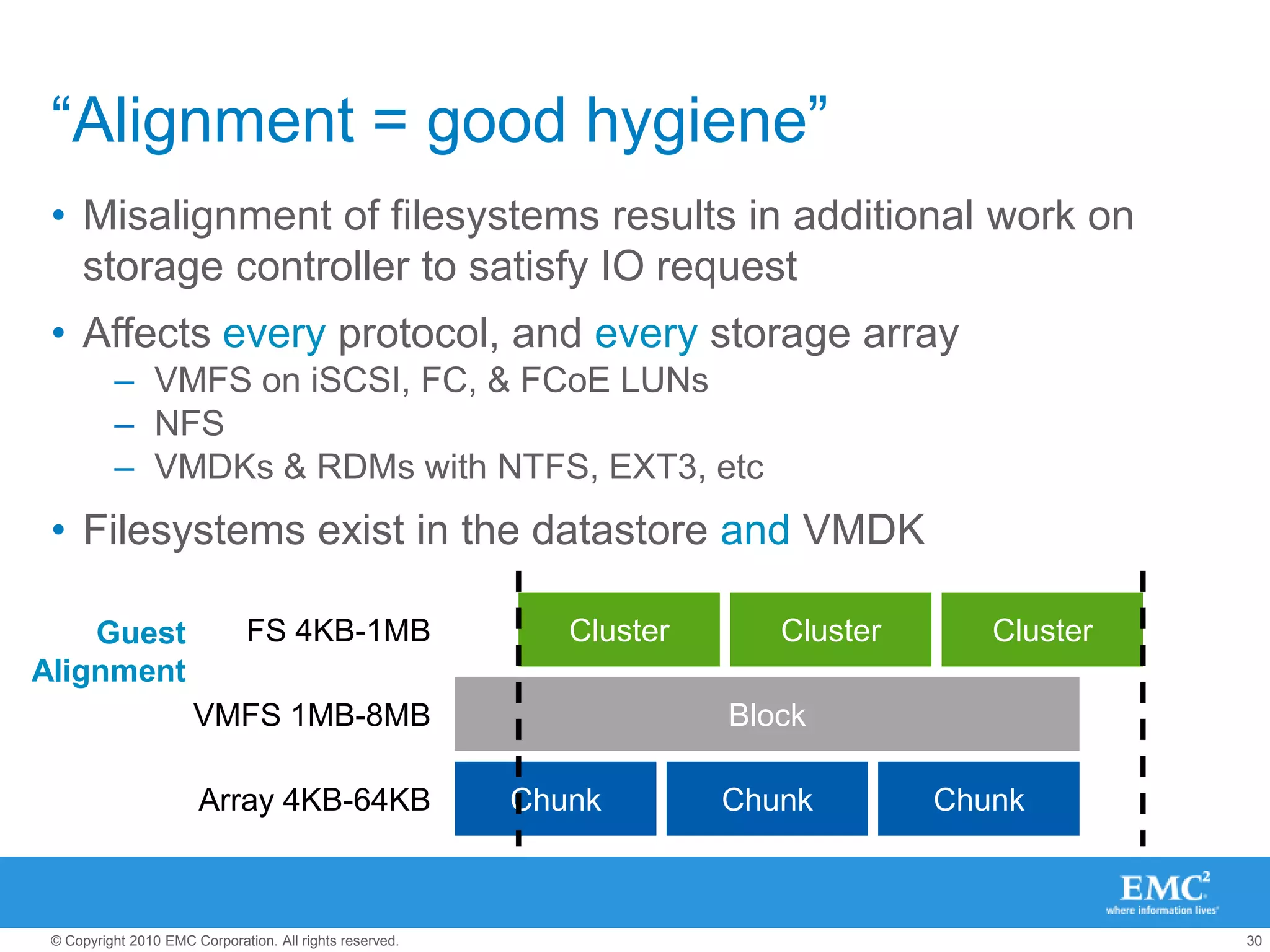






















The document presents best practices for storage management in VMware environments, emphasizing the importance of choosing the right protocol based on specific performance needs. It covers key aspects of multipathing, storage alignment, and NFS usage, while recommending vendor-specific documentation as essential resources. Recommendations include leveraging VMware features and plugins for optimized storage performance, as well as thorough understanding of multipathing options and configurations.






















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















