프로젝트 개요 -주제 선정 배경
취준생들을 위한 서비스를 개발해보자!
채용 면접 준비용 서비스를 기획
Hap-py ?
음성 인식 기반 AI 면접 솔루션
: 합(Hap)격하면 해삐(Hap-py)해진다 ☺️
채용 면접을 대비할 수 있는 모의 면접 기능 제공
음성 인식을 통한 면접 분석 및 피드백 제공
5.
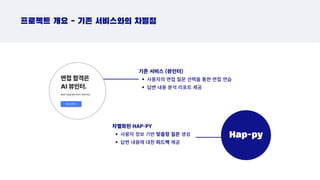
프로젝트 개요 -기존 서비스와의 차별점
Hap-py
기존 서비스 (뷰인터)
사용자의 면접 질문 선택을 통한 면접 연습
답변 내용 분석 리포트 제공
차별화된 HAP-PY
사용자 정보 기반 맞춤형 질문 생성
답변 내용에 대한 피드백 제공
6.
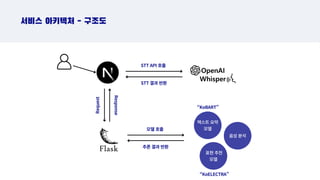
서비스 아키텍처 -구조도
STT API 호출
STT 결과 반환
모델 호출
추론 결과 반환
텍스트 요약
모델
음성 분석
표현 추천
모델
Request
Response
“KoBART”
“KoELECTRA”
7.
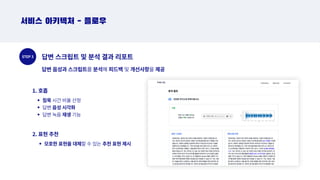
사전 정보 입력모의 면접 진행
답변 스크립트 및
분석 결과 리포트
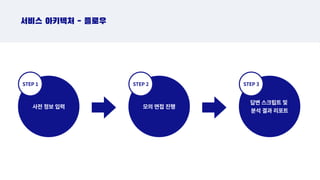
서비스 아키텍처 - 플로우
STEP 1 STEP 2 STEP 3
8.
STEP 1
인성 질문
기업형태
경력 여부
직무
질문 개수
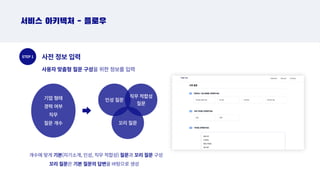
서비스 아키텍처 - 플로우
사전 정보 입력
사용자 맞춤형 질문 구성을 위한 정보를 입력
직무 적합성
질문
꼬리 질문
개수에 맞게 기본(자기소개, 인성, 직무 적합성) 질문과 꼬리 질문 구성
꼬리 질문은 기본 질문의 답변을 바탕으로 생성
9.
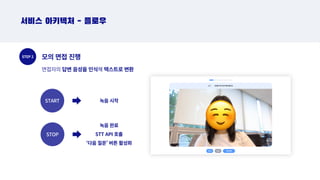
STEP 2
START
면접자의 답변음성을 인식해 텍스트로 변환
STOP
녹음 시작
녹음 완료
STT API 호출
‘다음 질문’ 버튼 활성화
서비스 아키텍처 - 플로우
모의 면접 진행
10.
STEP 3
답변 음성과스크립트를 분석해 피드백 및 개선사항을 제공
서비스 아키텍처 - 플로우
답변 스크립트 및 분석 결과 리포트
침묵 시간 비율 산정
답변 음성 시각화
답변 녹음 재생 기능
2. 표현 추천
모호한 표현을 대체할 수 있는 추천 표현 제시
1. 호흡
11.
분석 과정 -오디오 전처리 for 형식 변환
mp4 (핸드폰 녹음기)등 다양한 오디오 파일 형식
변환 후 학습과 전처리에 유용한 ‘wav’ 파일로 변환
기존
“AudioSegment”
12.
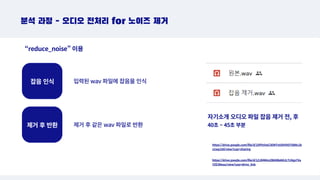
입력된 wav 파일에잡음을 인식
제거 후 반환
잡음 인식
분석 과정 - 오디오 전처리 for 노이즈 제거
제거 후 같은 wav 파일로 반환
“reduce_noise” 이용
https://drive.google.com/file/d/1DfYeVwC5EMTnUlVHX0758Mc1b
x2wg1A0/view?usp=sharing
https://drive.google.com/file/d/1ZJR4MmZB848bAMJLT24gp7Va
YZE3Neuu/view?usp=drive_link
자기소개 오디오 파일 잡음 제거 전, 후
40초 ~ 45초 부분
13.
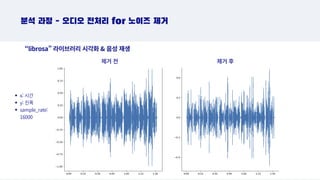
분석 과정 -오디오 전처리 for 노이즈 제거
제거 전
“librosa” 라이브러리 시각화 음성 재생
제거 후
x: 시간
y: 진폭
sample_rate:
16000
14.
분석 과정 -오디오 for 침묵 구간 탐색
제거 후 반환
잡음 인식
“detect_nonsilent” 이용
배경음 등 잡음이 제거된 wav 입력 파형 탐색 - ‘json’ 파일로 반환
침묵 시간이 5초 이상이면 침묵이라 판정
전체 시간 중 침묵 시간 비율을 반환
반환된 면접 자기소개 음성 파일
15.
분석 과정 -모델링 for 텍스트 요약 기능
입력 텍스트 일부에 노이즈를 추가
- 다시 원문으로 복구하는 autoencoder의 형태로 학습됨
“KoBART” 모델이란?
KoBART
논문에서 사용된 Text Infilling 노이즈 함수를 사용
40GB 이상의 한국어 텍스트에 대해서 학습한 한국어 encoder-decoder 언어 모델
- KoBART-base 배포
BART
16.
분석 과정 -모델링 for 텍스트 요약 기능
“KoBART” 모델이란?
tokenizers 패키지의 Character BPE tokenizer로 학습됨
Data
Model
Tokenizer
17.
분석 과정 -모델링 for 텍스트 요약 기능
“KoBART” 모델이란?
뉴스 기사 요약
Demo
18.
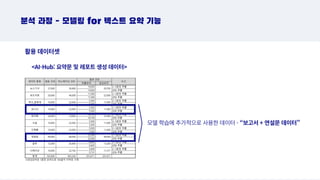
분석 과정 -모델링 for 텍스트 요약 기능
활용 데이터셋
모델 학습에 추가적으로 사용한 데이터 - “보고서 + 연설문 데이터”
AI-Hub: 요약문 및 레포트 생성 데이터
19.
원문 기반으로 새로운텍스트를 생성하는 NLG(Natural Language Generation) 방식
추출 요약
생성 요약
분석 과정 - 모델링 for 텍스트 요약 기능
문서 요약 task
문장 단위로 중요도를 scoring - 이를 기반으로 선택하고 조합하여 요약하는 방식
생성요약: 모델에서 새로운 텍스트 생성 - 말이 되지 않는 표현 만들어질 가능성 존재
추출요약: 주어진 문서 내에 존재하는 단어, 문장 그대로 사용
- 문서의 내용을 잘 반영한 요약문을 만들 가능성이 높음
“추출 요약”
20.
금융결제원은 국내 다양한금융 관련 서비스를 지원하는 최고의 기업으로서 금융공동망과
인터넷지로 서비스를 이용해 본 경험이 있으며 이곳에서 개발자로 일하며 다양한 사람을 위한
서비스를 만들 때 경험과 저의 지식이 도움이 될 수 있을 것이라 생각합니다.
분석 과정 - 모델링 for 텍스트 요약 기능
“KoBART” 모델 학습 결과
21.
Recall-Oriented Understudy forGisting Evaluation의 준말
Reference Summary(사람 생성 요약)와 System Summary(모델 생성 요약)를 비교하여 점수 구함
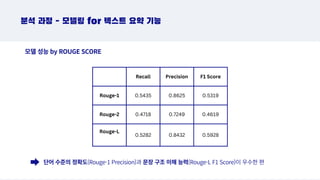
분석 과정 - 모델링 for 텍스트 요약 기능
모델 성능 평가 지표: “ROUGE metric”
Rouge-Recall
: Reference Summary와 매칭되는 System Summary의 N-Gram 개수/Reference Summary의 N-Gram 개수
Rouge-Precision
: System Summary와 매칭되는 Reference Summary의 N-Gram 개수/System Summary의 N-Gram 개수
Rouge-F1
: Rouge Recall과 Rouge Precision을 가지고 조화 평균을 내준 것
ROUGE-N
: Reference Summary에서 N-Gram으로 Count한 개수/Reference Summary와 System Summary에서 N-Gram으로 겹치는 개수
ROUGE-L
: Reference Summary와 System Summary에서 겹치는 최장 공통부분 수열(LCS, Longest Common Subsequence) 값이 분자
22.
Ko-ELECTRA
Recall Precision F1Score
Rouge-1 0.5435 0.8625 0.5319
Rouge-2 0.4718 0.7249 0.4619
Rouge-L
0.5282 0.8432 0.5928
분석 과정 - 모델링 for 텍스트 요약 기능
모델 성능 by ROUGE SCORE
단어 수준의 정확도(Rouge-1 Precision)과 문장 구조 이해 능력(Rouge-L F1 Score)이 우수한 편
23.
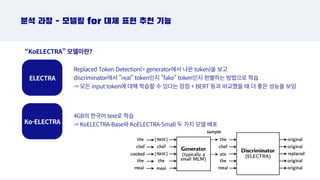
분석 과정 -모델링 for 대체 표현 추천 기능
Replaced Token Detection(= generator에서 나온 token)을 보고
discriminator에서 real token인지 fake token인지 판별하는 방법으로 학습
- 모든 input token에 대해 학습할 수 있다는 장점 + BERT 등과 비교했을 때 더 좋은 성능을 보임
“KoELECTRA” 모델이란?
Ko-ELECTRA
4GB의 한국어 text로 학습
- KoELECTRA-Base와 KoELECTRA-Small 두 가지 모델 배포
ELECTRA
24.
분석 과정 -모델링 for 대체 표현 추천 기능
“KoELECTRA” 모델이란?
v1, v2: 약 14G Corpus (2.6B tokens)를 사용 (뉴스, 위키, 나무위키)
v3: 약 20G의 모두의 말뭉치를 추가적으로 사용 (신문, 문어, 구어, 메신저, 웹)
Data
Model
Wordpiece 사용, 모델 s3 업로드
- OS 상관없이 Transformers 라이브러리만 설치하면 곧바로 사용 가능
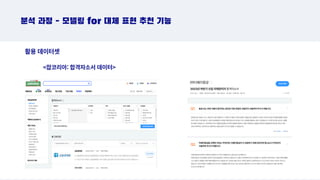
분석 과정 -모델링 for 대체 표현 추천 기능
활용 데이터셋
잡코리아: 합격자소서 데이터
27.
분석 과정 -모델링 for 대체 표현 추천 기능
“KoELECTRA” 모델 학습 + 대체 표현 추천
대체 표현 추천
학습된 모델 사용 - [MASK] 토큰 위치에 들어갈 단어 예측
1.
예측된 logits에서 확률이 가장 높은 상위 K개의 단어 추출
2.
추출된 단어들 중에서 유의어 리스트에 있는 단어들 필터링 - 최종 추천 단어로 반환
3.
28.
분석 과정 -모델링 for 대체 표현 추천 기능
“KoELECTRA” 모델 학습 결과
금융결제원은 국내 다양한 금융 관련 서비스를 지원하는 일류 기업입니다. 이런 여러 서비스 운영에 있어 중요한 것
은 사용자에게 적절한 UI를 제공하고, 효율적인 데이터 처리를 통해 빠른 속도를 제공하는 것입니다. 저는 이를 배우
기 위해 매일 알고리즘 풀이를 진행하고, 기존에 공부했던 JSP를 더 깊이 파악하기 위해 관련 학원에서 공부하며 여
러 예제를 사용한 Spring 프로젝트를 진행했습니다. 그리고 JPA를 사용하는 여러 방식과 주의점, querydsl 등 다양
한 부분에 대해 공부했습니다. 백엔드 외에도 front-end에 활용되는 javascript의 기능을 더 잘 이해하기 위해
vanilla JS를 사용하여 점점 난이도를 높여가며 프로젝트를 진행 중입니다. 그렇게 실력을 쌓던 중, 운이 좋게도 제가
공부하였고 앞으로의 진로로 결정한 java spring이 기반이 되는 전산직 사무원을 채용한다는 소식을 들었고, 최고의
기업에서 좋아하는 공부를 할 수 있을 것이라는 기대감으로 지원하게 되었습니다.















![분석 과정 - 모델링 for 대체 표현 추천 기능
“KoELECTRA” 모델 학습 + 대체 표현 추천
대체 표현 추천
학습된 모델 사용 - [MASK] 토큰 위치에 들어갈 단어 예측
1.
예측된 logits에서 확률이 가장 높은 상위 K개의 단어 추출
2.
추출된 단어들 중에서 유의어 리스트에 있는 단어들 필터링 - 최종 추천 단어로 반환
3.](https://image.slidesharecdn.com/b01zhap-pyai-240812134440-ff36618d/85/20-BOAZ-B01Z-HAP-PY_-AI-pdf-27-320.jpg)



![제 20회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Last Piece] 카프카 기반 리그오브레전드 챔피언 추처...](https://cdn.slidesharecdn.com/ss_thumbnails/lasstpiece-240811072853-cf5fec13-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 20회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [PILL-AZ] : 개인 맞춤형 영양제 조합 추천 ...](https://cdn.slidesharecdn.com/ss_thumbnails/pillforme-240811074306-a2f13d7b-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 17회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Catch, Traffic!] : 지하철 혼잡도 및 키워드 분석 데이터 파이프라인 구축](https://cdn.slidesharecdn.com/ss_thumbnails/catchtrafficppt-230220154703-8361d63a-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [리뷰의 재발견 팀] : 이커머스 리뷰 유용성 파악 및 필터링](https://cdn.slidesharecdn.com/ss_thumbnails/03-220124103455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-1-180430181759-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 19회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [COLLABO-AZ] : 고객 세그멘테이션 기반 개인 맞춤형 추천시스템 for 루빗](https://cdn.slidesharecdn.com/ss_thumbnails/random-240214103130-13fea14b-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [기린그림 팀] : 사용자의 손글씨가 담긴 그림 일기 생성 서비스](https://cdn.slidesharecdn.com/ss_thumbnails/random-220728094901-ef1ebc42-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [#인스타툰 팀] : 해시태그 기반 인스타툰 추천 챗봇](https://cdn.slidesharecdn.com/ss_thumbnails/random-220728125517-c1a27331-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 19회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [무드등] : 무신사를 활용한 고객 상황에 따른 의류 추천 스타일링 대시보드](https://cdn.slidesharecdn.com/ss_thumbnails/random-240209055643-94bfc21f-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [개미야 뭐하니?팀] : 투자자의 반응을 이용한 실시간 등락 예측(feat. 카프카)](https://cdn.slidesharecdn.com/ss_thumbnails/06-220124105013-thumbnail.jpg?width=640&height=640&fit=bounds)


![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [YouPlace 팀] : 카프카와 스파크를 활용한 유튜브 영상 속 제주 명소 검색](https://cdn.slidesharecdn.com/ss_thumbnails/10youplace-220124105901-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 17회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [나만 없어 범고래] : 스니커즈 중심의 리셀 시장 및 플랫폼 KREAM 분석](https://cdn.slidesharecdn.com/ss_thumbnails/kream-230220151043-d6151806-thumbnail.jpg?width=640&height=640&fit=bounds)

![[우리가 데이터를 쓰는 법] 모바일 게임 로그 데이터 분석 이야기 - 엔터메이트 공신배 팀장](https://cdn.slidesharecdn.com/ss_thumbnails/5-160415084345-thumbnail.jpg?width=640&height=640&fit=bounds)
![[115]쿠팡 서비스 클라우드 마이그레이션 통해 배운것들](https://cdn.slidesharecdn.com/ss_thumbnails/115coupang-181011031522-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018] 고객 사례를 통해 본 클라우드 전환 전략](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra06-190131073402-thumbnail.jpg?width=640&height=640&fit=bounds)





![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Cm:)e팀] : 이커머스 고객경험 관리 분석](https://cdn.slidesharecdn.com/ss_thumbnails/01cmile-220124102549-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 14회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Finalyst팀] : 2021 Korea Fintech Visualization](https://cdn.slidesharecdn.com/ss_thumbnails/finalyst-210806013252-thumbnail.jpg?width=640&height=640&fit=bounds)







![[워크숍] Get to know AI, Meet your new teammate!](https://cdn.slidesharecdn.com/ss_thumbnails/gettoknowaimeetyournewteammate-241209073551-a677c30c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[222]대화 시스템 서비스 동향 및 개발 방법](https://cdn.slidesharecdn.com/ss_thumbnails/222-150915011307-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



![[224] 번역 모델 기반_질의_교정_시스템](https://cdn.slidesharecdn.com/ss_thumbnails/242-150915010843-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[싸이그램즈 2018] 텍스트 데이터 전처리로 시작하는 NLP](https://cdn.slidesharecdn.com/ss_thumbnails/psygramsnlp101-180704045500-thumbnail.jpg?width=640&height=640&fit=bounds)






![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [OnLog]: Real-time Edge-to-Cloud Data Pipeline fo...](https://cdn.slidesharecdn.com/ss_thumbnails/3-4boaz23rdconferenceonlog-260204093729-11983ba7-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [F4] : 시켜줘, 금잔디 명예 플로리스트](https://cdn.slidesharecdn.com/ss_thumbnails/3-3boaz23rdconferencef4-260204011323-1cb48ec9-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [픽미] : 디저트 큐레이팅 플랫폼, 딸기로픽을 위한 데이터 기반 의사결정 프로세스 구축](https://cdn.slidesharecdn.com/ss_thumbnails/3-2boaz23rdconference-260203102931-15458767-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [셋이어때] : 헬퍼잇](https://cdn.slidesharecdn.com/ss_thumbnails/2-3boaz23rdconference-260203102432-6c8c7ed6-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [어벤정스] : ToonP](https://cdn.slidesharecdn.com/ss_thumbnails/2-2boaz23rdconference-260203102006-3a01358e-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [If Lab] : 실시간 투표 커뮤니티 서비스 기반 데이터 파이프라인 구축 및 성능 검증](https://cdn.slidesharecdn.com/ss_thumbnails/2-1boaz23rdconferenceiflab-260203101556-e51663dd-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [SimAI] : Omni_모든 콘텐츠 운영을 하나로](https://cdn.slidesharecdn.com/ss_thumbnails/1-4boaz23rdconferencesimai-260203101225-d673a594-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [JJAI] : Re:Buy - 고객 행동 패턴 기반 재구매 시점 예측 개인화 CRM 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/1-3boaz23rdconferencejjai-260203100705-ab1ce027-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [백 투 더 엔지] : 분산환경 주문 이벤트 처리 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/1-2boaz23rdconference-260203100241-73ce0aa8-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [북적북적] : 데이터 기반 독립출판사,서점 경영지원 대시보드](https://cdn.slidesharecdn.com/ss_thumbnails/1-1boaz23rdconference-260203093712-78abc1a0-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [토이스토리] : Wispy](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250803064626-64a49e3a-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [청진스] : Multi-Label Lung Sound Classification ba...](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801124724-469662d6-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [직행복] : 실시간 로그 처리 기반 추천시스템](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801124036-52794fc9-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [영웅호걸] : Context-Aware Real-time Sentiment based ...](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801123333-f123549e-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [중증외상센터] : 24시간 심전도 Holter 데이터 기반의 소아 PSVT 예측 모델 개발](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801122720-74dafab0-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [아라보아즈] : 아라보아의 장기적 성장을 위한 DDDM 환경 구축](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801031027-23699371-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [소크라데이터스] : 웨어러블 기기를 활용한 생체 신호 기반 감정 데이터 수집 및 감정 ...](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801030109-344e2af9-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [땡큐쏘아마취] : 소마챗 : Agentic RAG 기반 소아마취 업무지원 챗봇](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801025055-4240eed3-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [SNOMED] : LangGraph 기반 OMOP CDM 매핑 파이프라인 구축](https://cdn.slidesharecdn.com/ss_thumbnails/25-1snomed-250801024253-89455097-thumbnail.jpg?width=640&height=640&fit=bounds)