Downloaded 13 times










![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [YouPlace 팀] : 카프카와 스파크를 활용한 유튜브 영상 속 제주 명소 검색](https://image.slidesharecdn.com/10youplace-220124105901/75/15-BOAZ-YouPlace-25-2048.jpg)

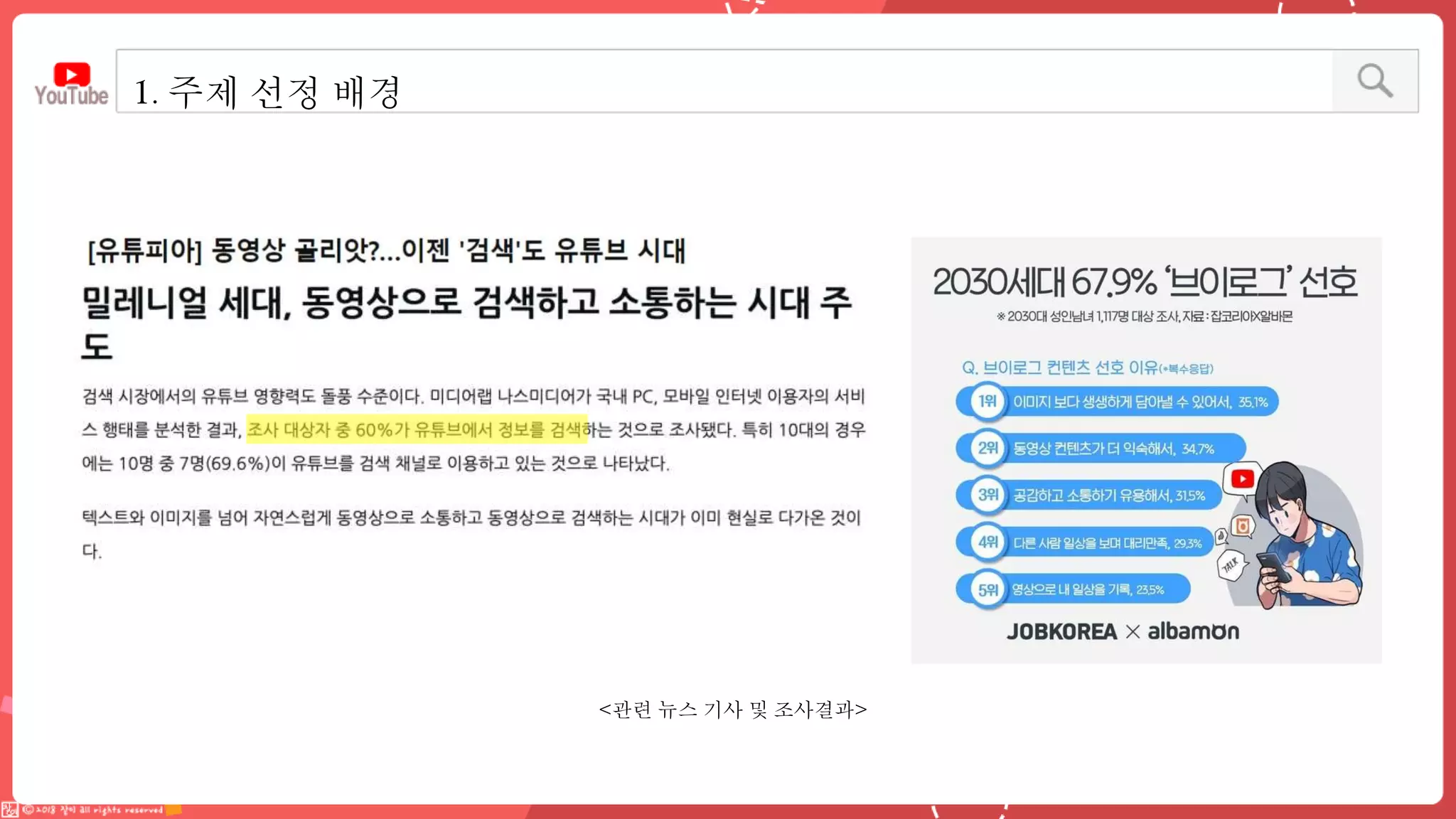
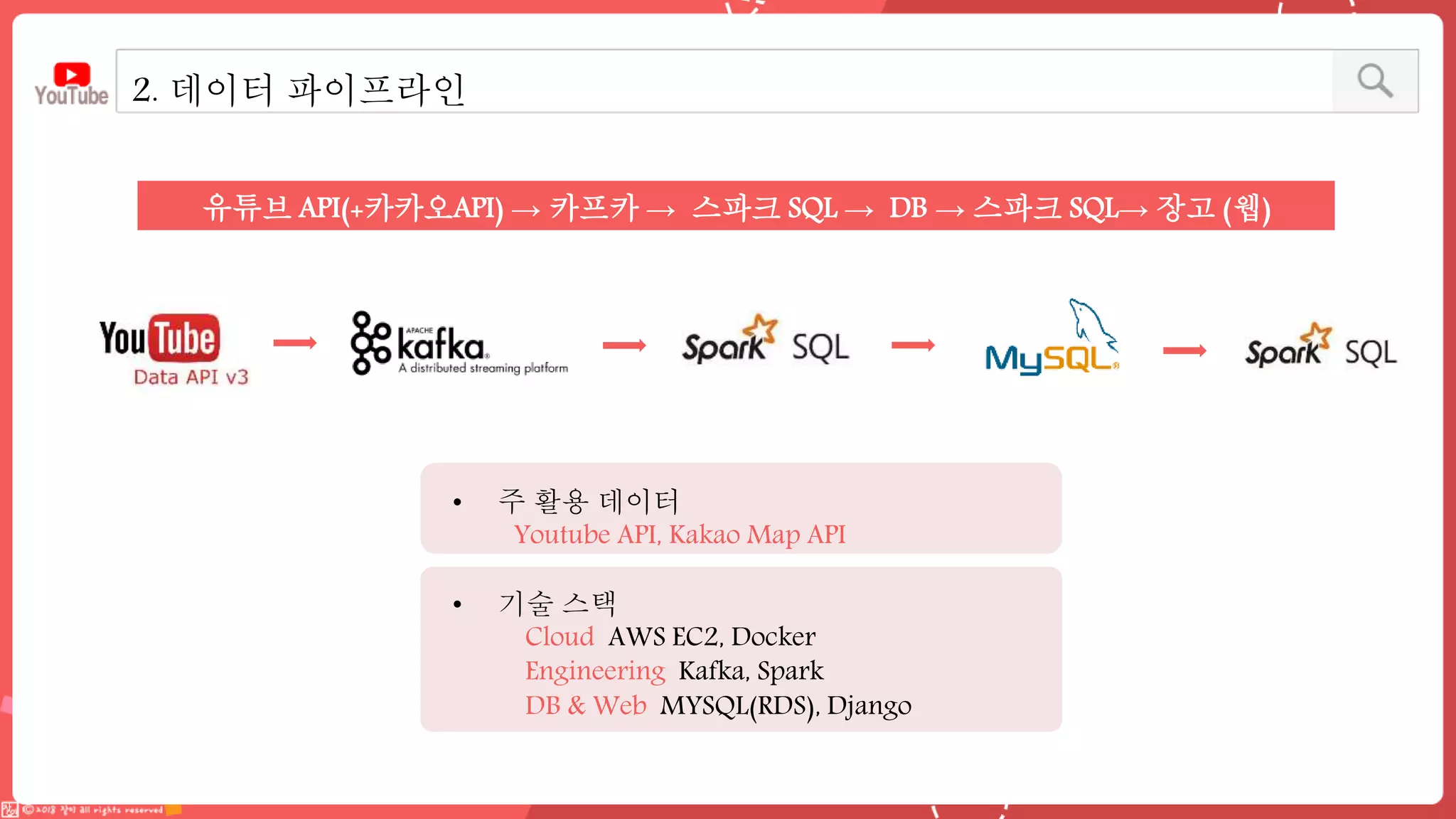
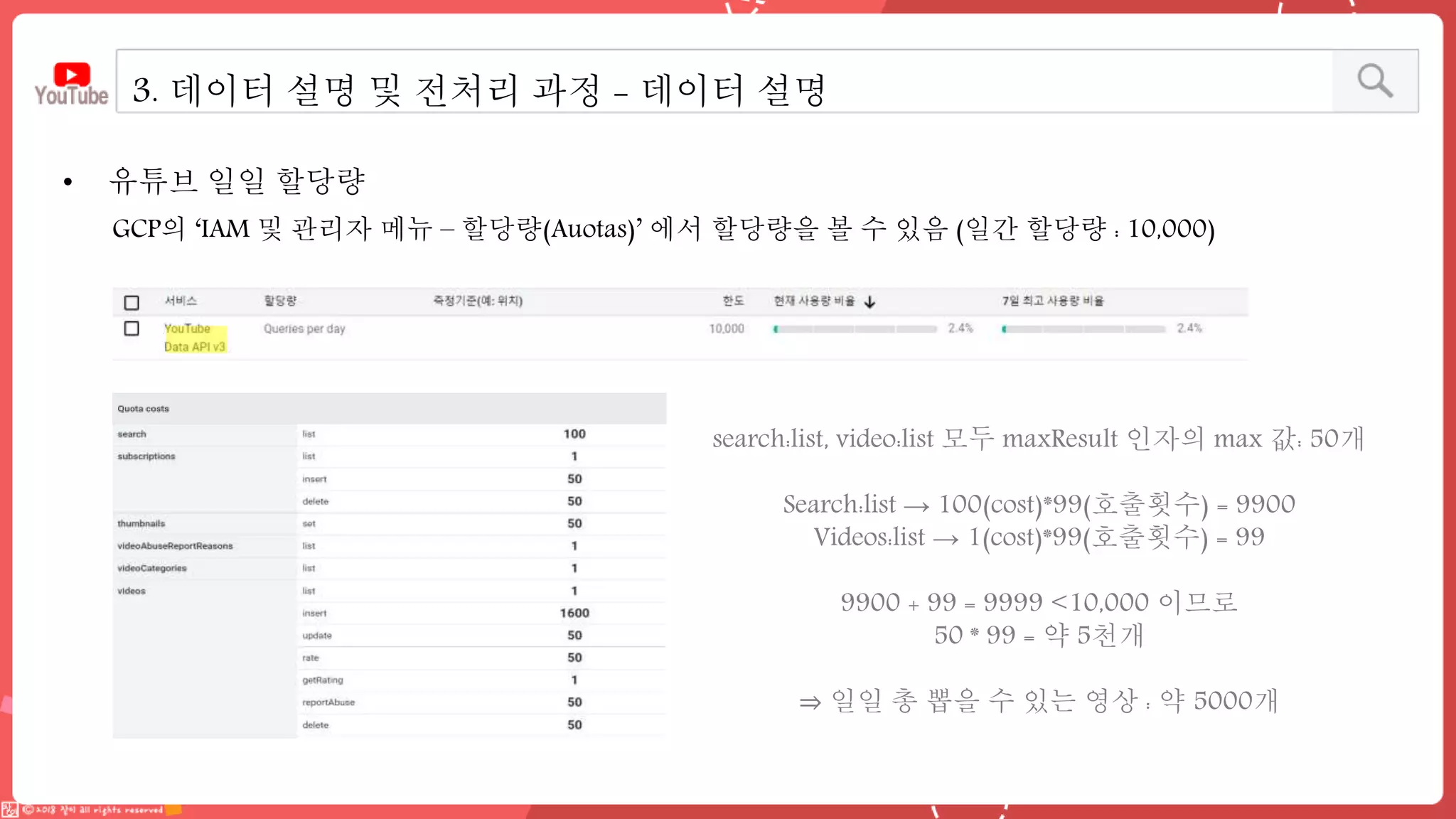
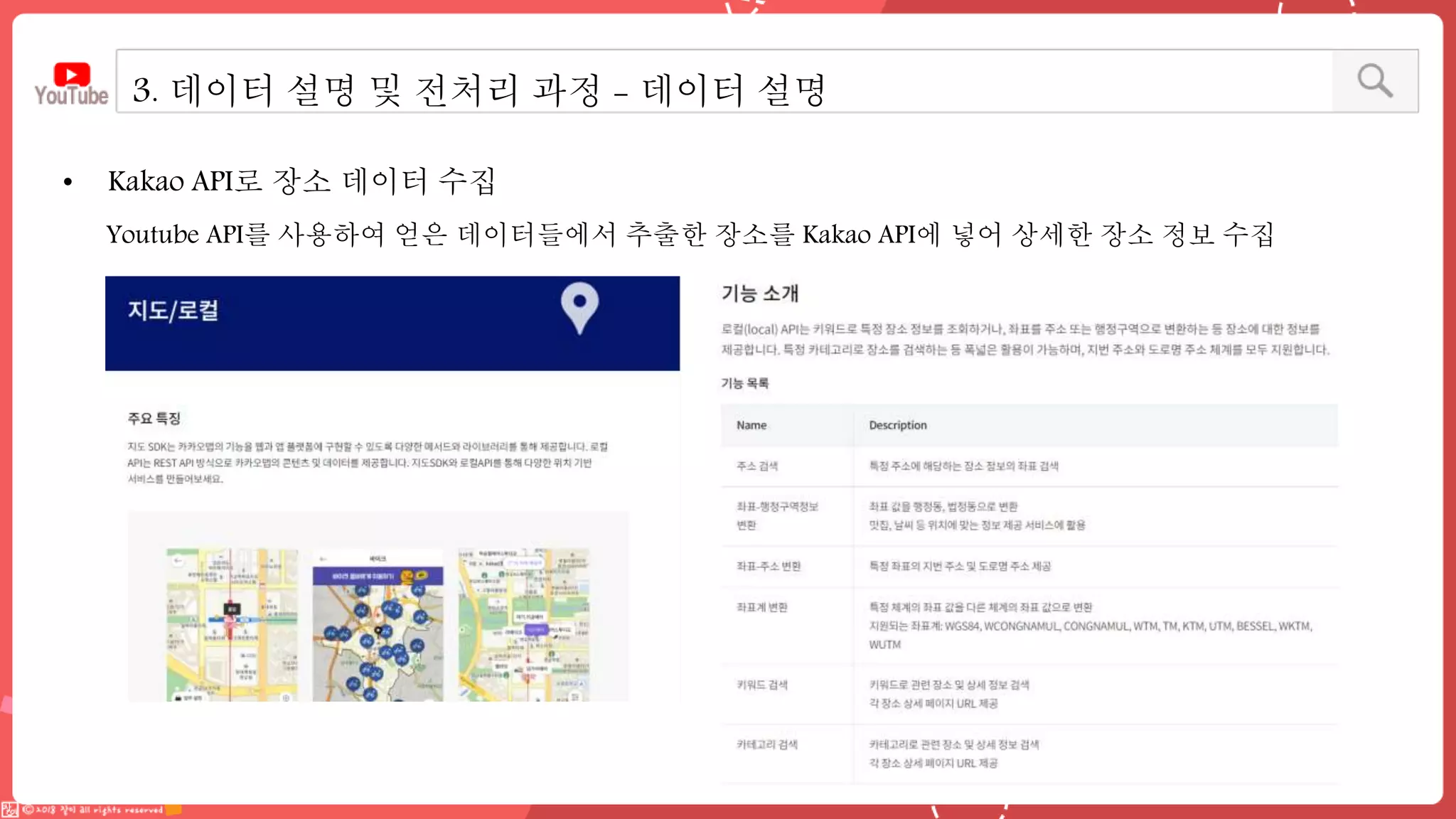
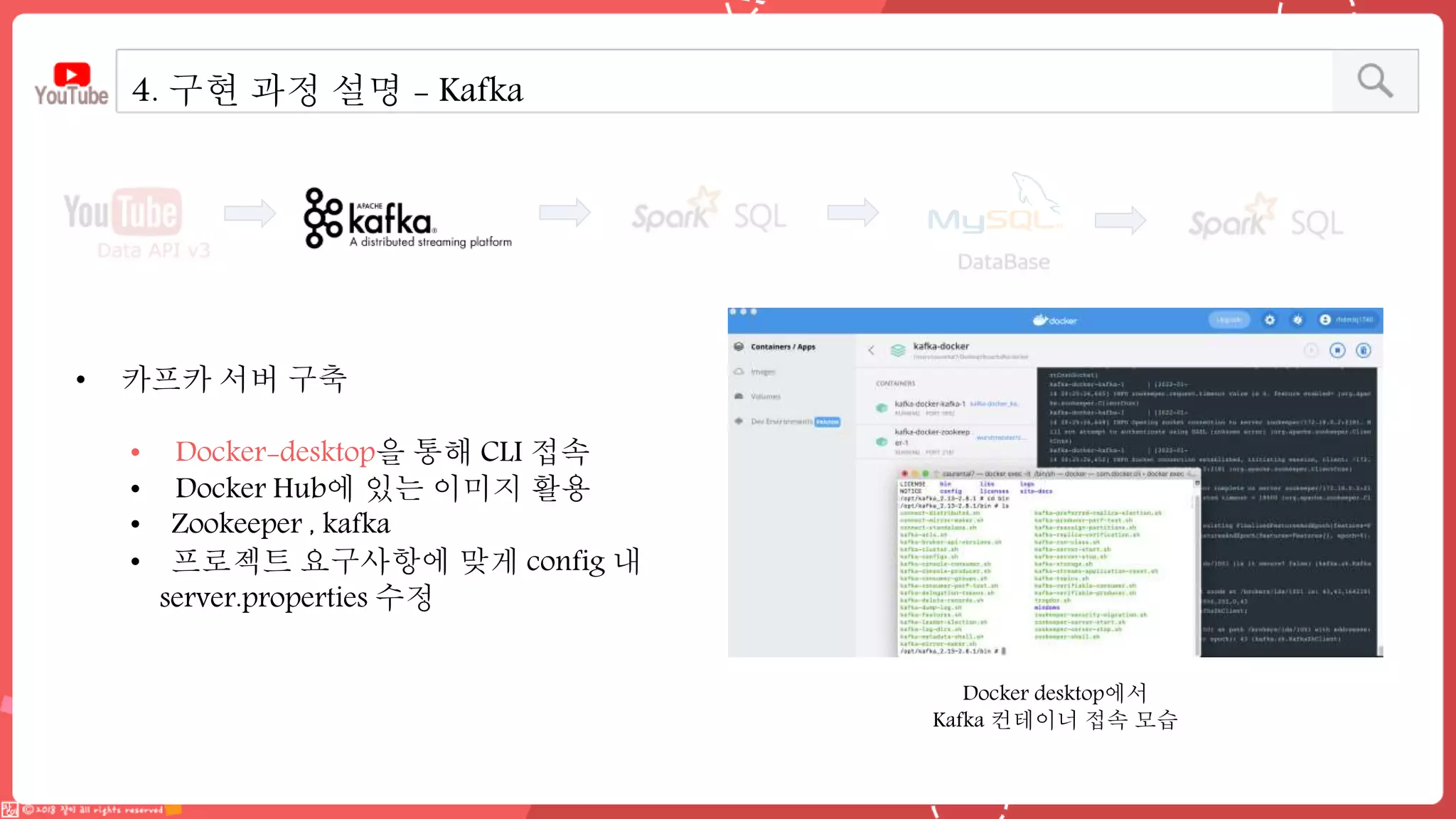
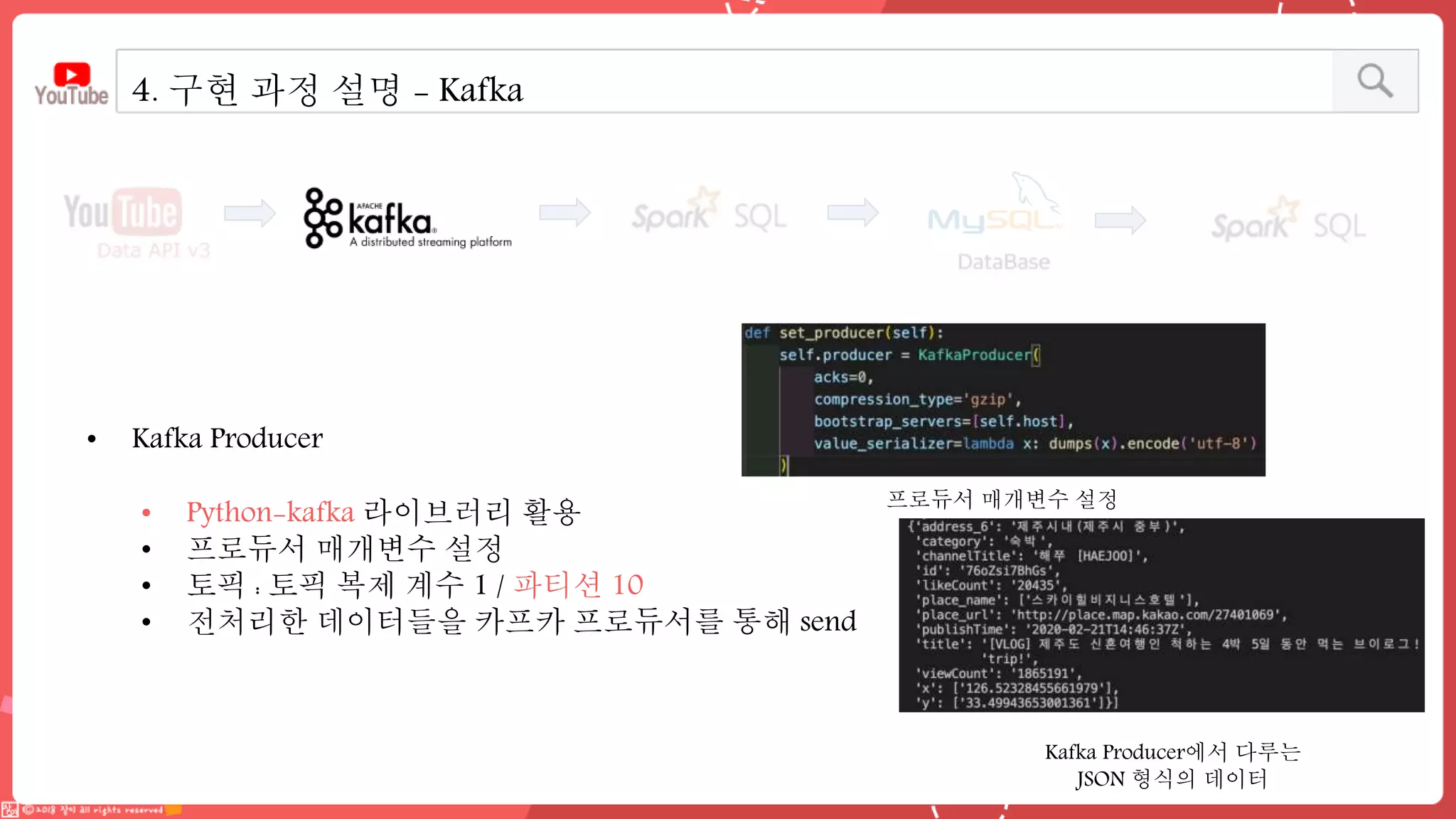
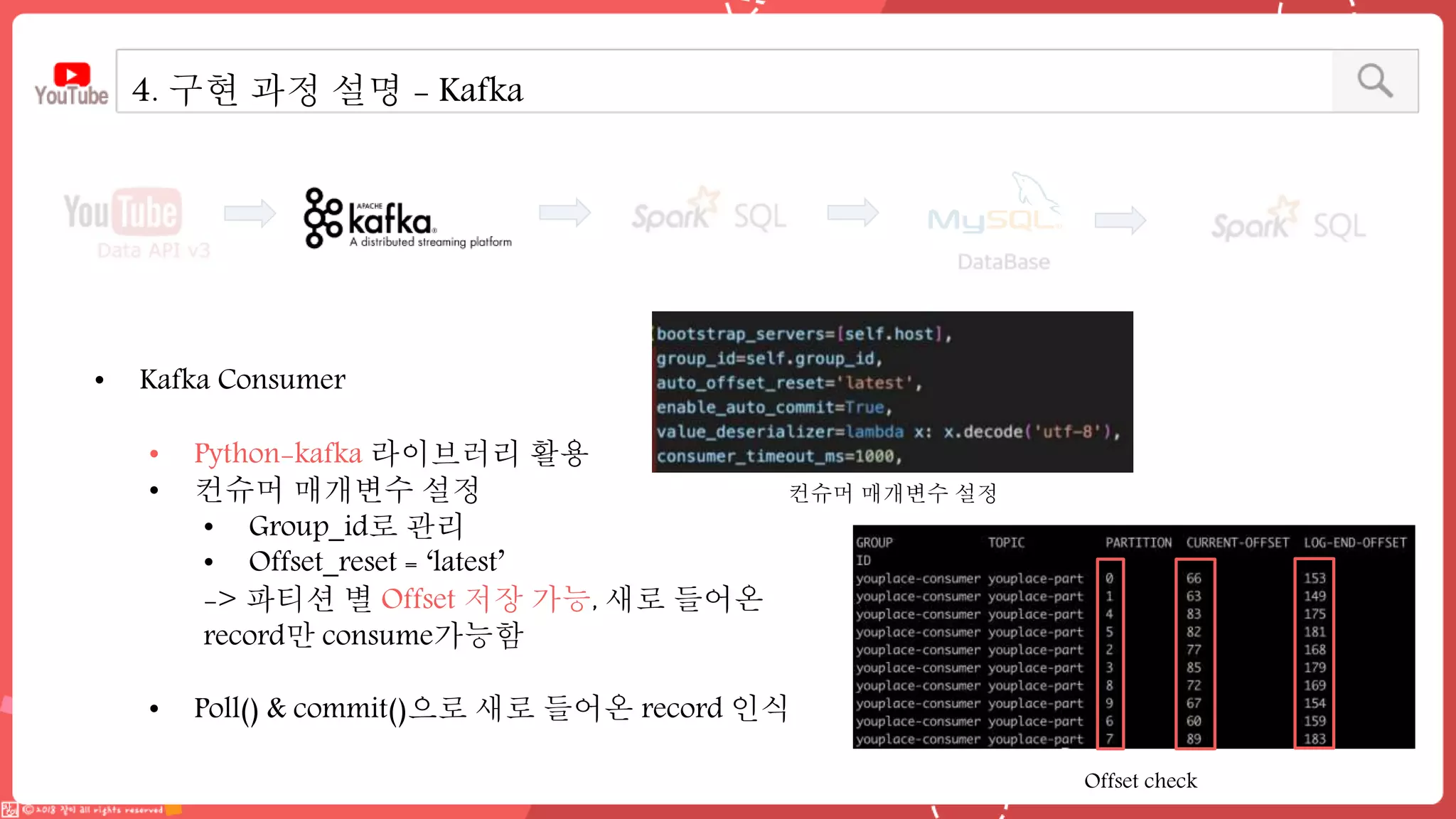
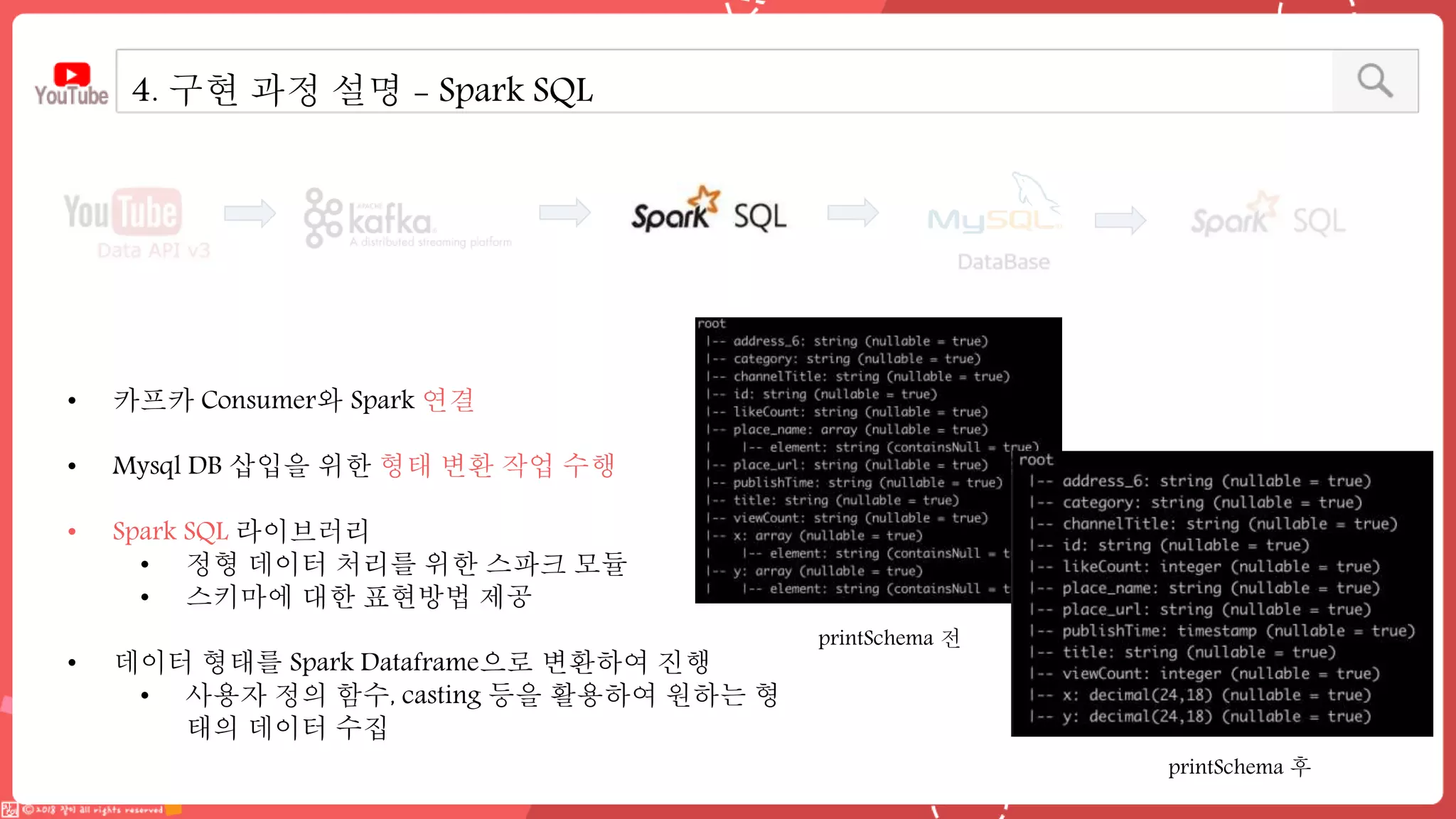
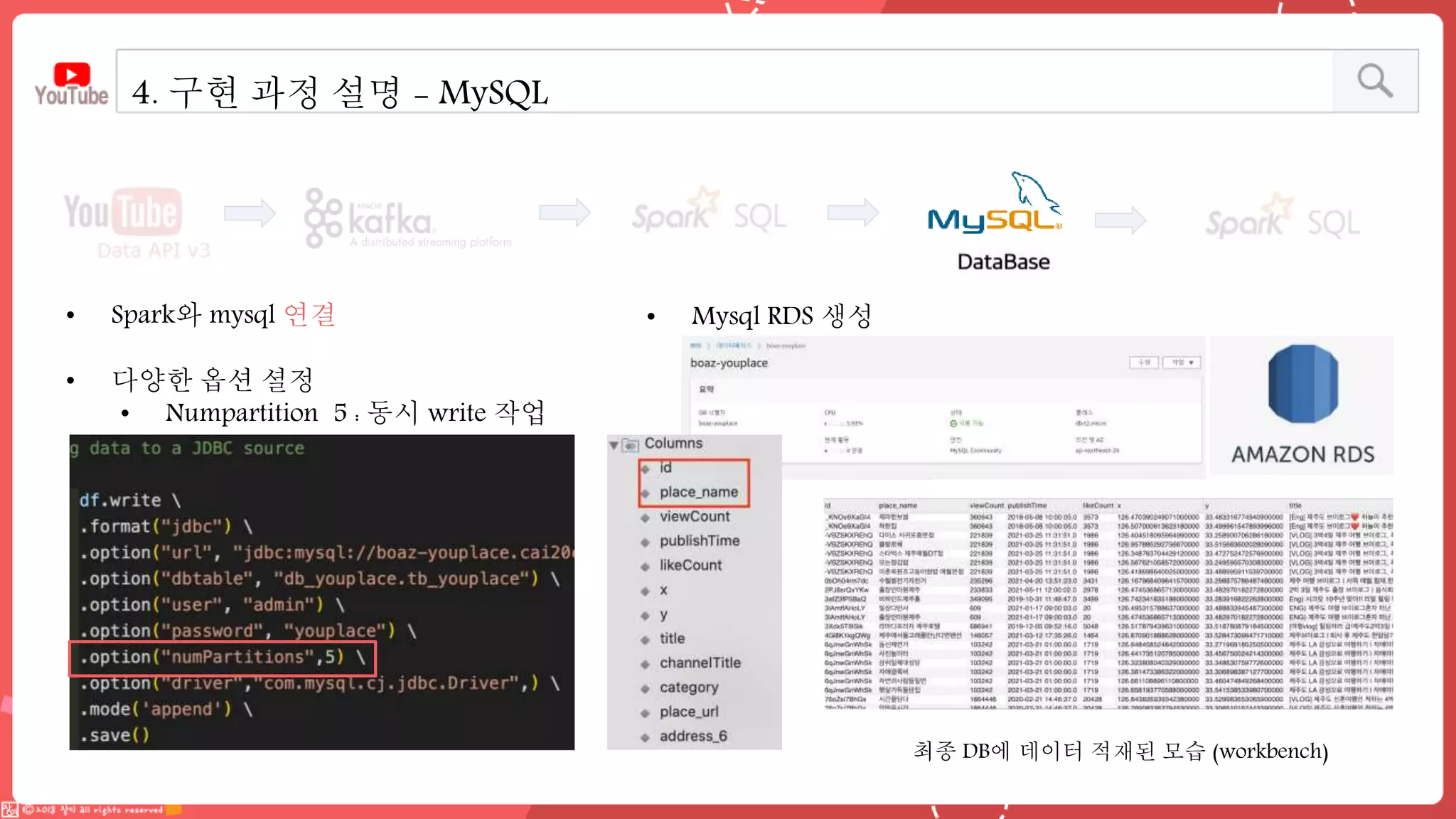
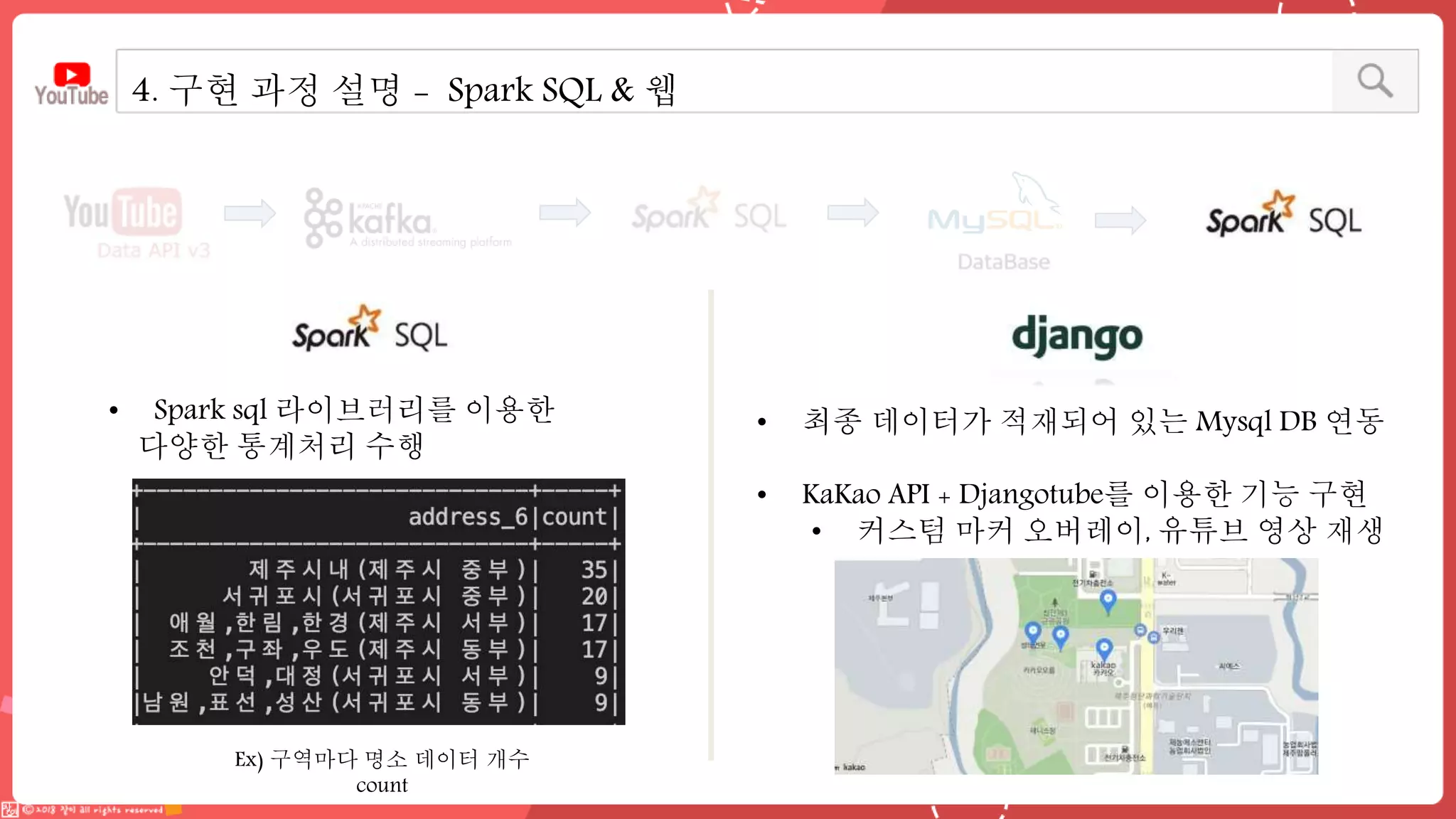
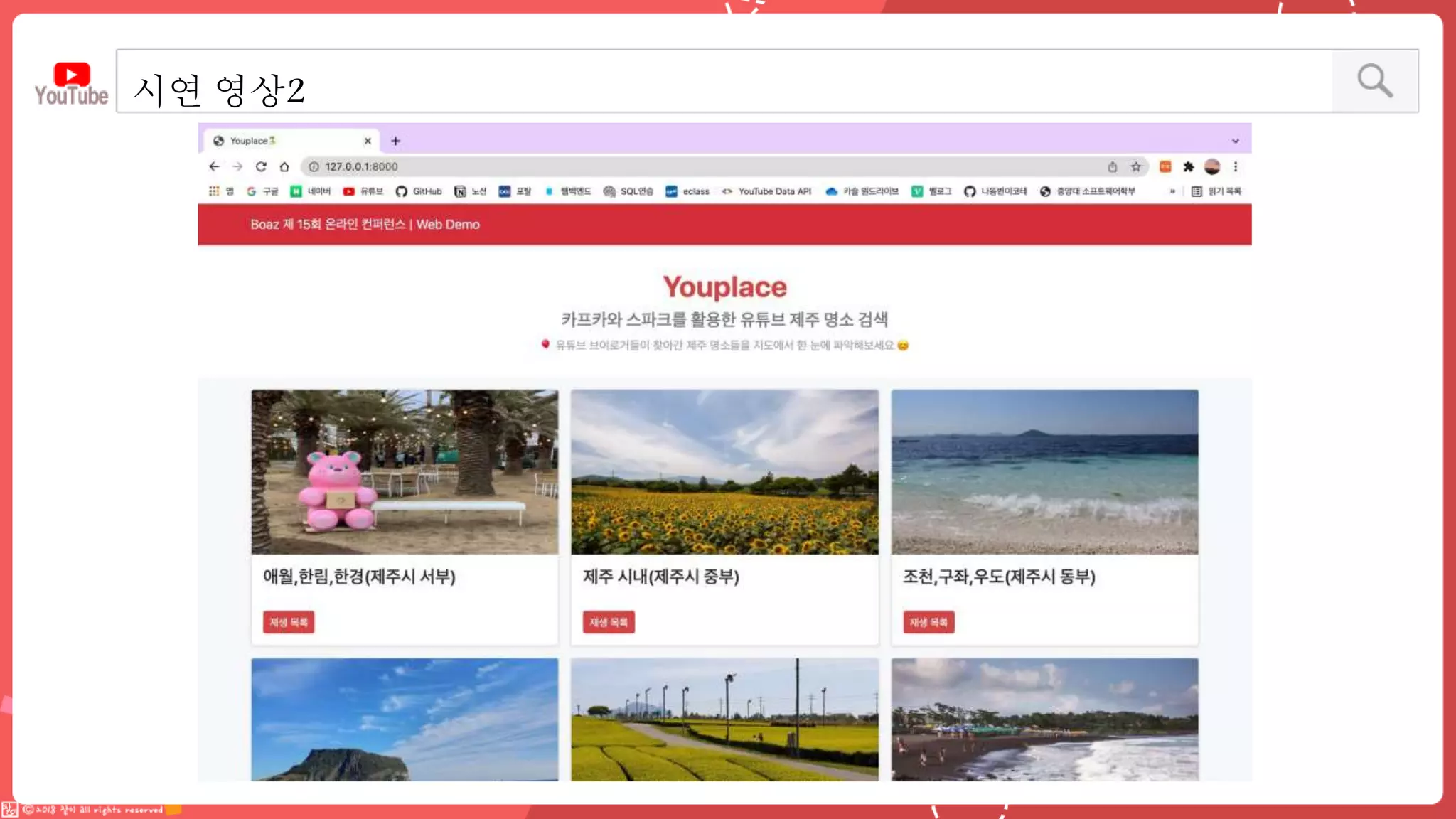
데이터 엔지니어링 프로젝트를 진행한 YouPlace팀에서는 아래와 같은 프로젝트를 진행했습니다. <aside> 이젠 검색도 유튜브 시대 제주여행을 계획할 때 브이로그 영상을 많이 참고하실텐데요 수많은 영상들과 영상 속 분산된 명소들을 하나 하나 찾으려 생각하면 막막하지 않으셨나요? 이러한 고민을 갖고 계신 분들을 위해, 유튜브 브이로거들이 찾아간 여행 명소들을 지도에서 한 눈에 파악할 수 있도록 만들었어요 (github : https://github.com/Boaz-Youplace) 16기 엔지니어링 고은서 | 중앙대학교 소프트웨어학부 16기 엔지니어링 류정화 | 성신여자대학교 융합보안공학과 16기 엔지니어링 송경민 | 국민대학교 소프트웨어학과

![라이트브레인 UX 아카데미 24기오픈프로젝트 [캐치테이블 - UX/UI 개선]](https://cdn.slidesharecdn.com/ss_thumbnails/rbuxa24thcatchtable-240715031011-6814c4d6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DevGround] 린하게 구축하는 스타트업 데이터파이프라인](https://cdn.slidesharecdn.com/ss_thumbnails/devgroundkmongrevisedcraig190627finalscriptformatted-190828020444-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [#인스타툰 팀] : 해시태그 기반 인스타툰 추천 챗봇](https://cdn.slidesharecdn.com/ss_thumbnails/random-220728125517-c1a27331-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [개미야 뭐하니?팀] : 투자자의 반응을 이용한 실시간 등락 예측(feat. 카프카)](https://cdn.slidesharecdn.com/ss_thumbnails/06-220124105013-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [WHY 팀] : 나만의 웹툰일기 Toonight](https://cdn.slidesharecdn.com/ss_thumbnails/whytoonight-220728094742-132fa7c2-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [하둡메이트 팀] : 하둡 설정 고도화 및 맵리듀스 모니터링](https://cdn.slidesharecdn.com/ss_thumbnails/random-220728094615-7bbbfc3e-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Indus2ry 팀] : 2022산업동향- 편의점 & OTT 완벽 분석](https://cdn.slidesharecdn.com/ss_thumbnails/05indus2ry-220124104616-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [BAOBAB 팀] : 반려동물 미용업 모바일 서비스 분석](https://cdn.slidesharecdn.com/ss_thumbnails/baobab-220728095441-2b81735a-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [기린그림 팀] : 사용자의 손글씨가 담긴 그림 일기 생성 서비스](https://cdn.slidesharecdn.com/ss_thumbnails/random-220728094901-ef1ebc42-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MarketIN팀] : 디지털 마케팅 헬스체킹 서비스](https://cdn.slidesharecdn.com/ss_thumbnails/09marketin-220124105610-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 18회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [보아酒] : 리뷰 감정분석을 통한 전통주 추천 서비스](https://cdn.slidesharecdn.com/ss_thumbnails/pdf-230809122213-2c021e29-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 14회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [카페 어디가?팀] : 카페 및 장소 추천 서비스](https://cdn.slidesharecdn.com/ss_thumbnails/seoulyumyum-210806020316-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Secret X 팀] : XAI를 활용한 수능 영어영역 문제풀이](https://cdn.slidesharecdn.com/ss_thumbnails/xai-220728094640-df53ef35-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 17회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Catch, Traffic!] : 지하철 혼잡도 및 키워드 분석 데이터 파이프라인 구축](https://cdn.slidesharecdn.com/ss_thumbnails/catchtrafficppt-230220154703-8361d63a-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Find Your Style 팀] : 사용자 이미지 라벨링을 통한 의류 추천 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/04findyourstyle-220124104046-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 14회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [TweetViz팀] : 카프카와 스파크를 통한 tweetdeck 개발](https://cdn.slidesharecdn.com/ss_thumbnails/tweetvizconferenceboazengineeringadv-210806022123-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [쇼미더뮤직 팀] : 텍스트 감정추출을 통한 노래 추천](https://cdn.slidesharecdn.com/ss_thumbnails/07-220124105215-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 17회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [ztyle] : 손그림 의류 검색 서비스](https://cdn.slidesharecdn.com/ss_thumbnails/ztyle-230221082810-938747b1-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 18회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [투니버스] : 스파크 기반 네이버 웹툰 댓글 수집 및 분석](https://cdn.slidesharecdn.com/ss_thumbnails/random-230809123044-ba4ea828-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [코끼리책방 팀] : 사용자 스크랩 내용 기반 도서 추천](https://cdn.slidesharecdn.com/ss_thumbnails/random-220728094946-1e72ce02-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Stalker 팀] : 감정분석을 통한 MBTI 기반 개인별 투자 성향 분석](https://cdn.slidesharecdn.com/ss_thumbnails/stalkermbti-220728094055-0258bbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 17회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [중고책나라] : 실시간 데이터를 이용한 Elasticsearch 클러스터 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/random-230220154251-7145ba84-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 19회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [백발백준] : 백준봇 : 컨테이너 오케스트레이션 기반 백준 문제 추천 봇](https://cdn.slidesharecdn.com/ss_thumbnails/random-240209055922-328cce98-thumbnail.jpg?width=640&height=640&fit=bounds)







![제 20회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Last Piece] 카프카 기반 리그오브레전드 챔피언 추처...](https://cdn.slidesharecdn.com/ss_thumbnails/lasstpiece-240811072853-cf5fec13-thumbnail.jpg?width=640&height=640&fit=bounds)

![제 21회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [LKVK] : 디토다이닝_서버리스 데이터 파이프라인을 곁들인 맛집 추천 서비스](https://cdn.slidesharecdn.com/ss_thumbnails/random-250208084808-3f257f02-thumbnail.jpg?width=640&height=640&fit=bounds)









![제 21회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [닭다리] : 쿠챗_RAG를 활용한 건국대학교 맞춤 챗봇](https://cdn.slidesharecdn.com/ss_thumbnails/random-250208153615-fde93618-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 21회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [데조영] : 유저 행동 분석 기반 인터랙티브 대시보드 구축](https://cdn.slidesharecdn.com/ss_thumbnails/boazpdfx-250208084412-101b33a5-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 21회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [WishU] : 직원을 위한 기업 경영 KPI 대시보드 및 커뮤니티 서비스 활성화를 위...](https://cdn.slidesharecdn.com/ss_thumbnails/wishu-250208085001-2c985577-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 20회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [스타팅] 플라이북 프로덕트 성장을 위한 이...](https://cdn.slidesharecdn.com/ss_thumbnails/random-240811152435-a5ace7ff-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 21회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Da.ily] : 상호작용 데이터 기반 와인 추천 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/da-250208084923-3816ac52-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 21회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [보아저스] : 목표 관리앱_챌린지로 보는 유저 행동](https://cdn.slidesharecdn.com/ss_thumbnails/boazersppt-250210203302-25682b2b-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 20회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [B01Z] HAP-PY_음성 인식 기반 AI 면접 솔루...](https://cdn.slidesharecdn.com/ss_thumbnails/b01zhap-pyai-240812134440-ff36618d-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 21회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [2인 3각] : FinSum_Dynamic Few-shot기반의 미국 주식 뉴스 리포트...](https://cdn.slidesharecdn.com/ss_thumbnails/23-250210203452-16471e06-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [직행복] : 실시간 로그 처리 기반 추천시스템](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801124036-52794fc9-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [토이스토리] : Wispy](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250803064626-64a49e3a-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [소크라데이터스] : 웨어러블 기기를 활용한 생체 신호 기반 감정 데이터 수집 및 감정 ...](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801030109-344e2af9-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 21회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [OptiMaps] : CE-VRP_Constraint embedding for reco...](https://cdn.slidesharecdn.com/ss_thumbnails/optimapsce-vrpconstraintembeddingforrecognizinginteractionsbetweenconstraintsinsolvingvehiclerouting-250208084619-7e4a6287-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [SNOMED] : LangGraph 기반 OMOP CDM 매핑 파이프라인 구축](https://cdn.slidesharecdn.com/ss_thumbnails/25-1snomed-250801024253-89455097-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [땡큐쏘아마취] : 소마챗 : Agentic RAG 기반 소아마취 업무지원 챗봇](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801025055-4240eed3-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [아라보아즈] : 아라보아의 장기적 성장을 위한 DDDM 환경 구축](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801031027-23699371-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [영웅호걸] : Context-Aware Real-time Sentiment based ...](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801123333-f123549e-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [청진스] : Multi-Label Lung Sound Classification ba...](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801124724-469662d6-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [GO-DIVA] : Fitbnb : 취향에 딱 맞는 에어비앤비 큐레이션 프로젝트](https://cdn.slidesharecdn.com/ss_thumbnails/25-1go-diva-250730114101-e43faf33-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [중증외상센터] : 24시간 심전도 Holter 데이터 기반의 소아 PSVT 예측 모델 개발](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801122720-74dafab0-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 21회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [연말결산] : LOOK-BACK_데이터 기반 3초 자기반성 SaaS 대시보드](https://cdn.slidesharecdn.com/ss_thumbnails/lookback-250208084037-8c346175-thumbnail.jpg?width=640&height=640&fit=bounds)