Download as PDF, PPTX





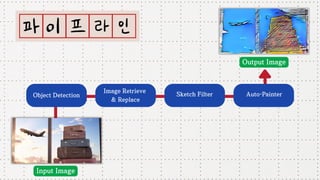
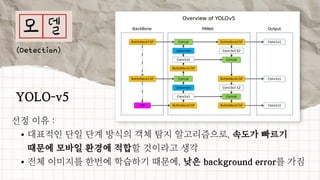
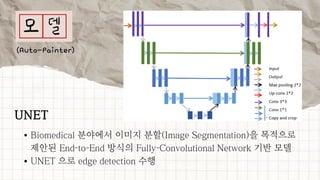
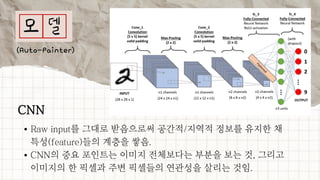


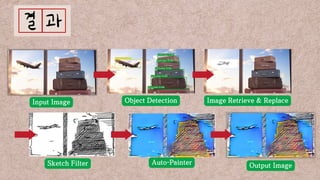










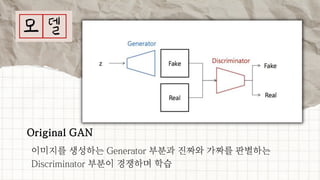
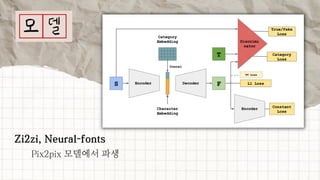
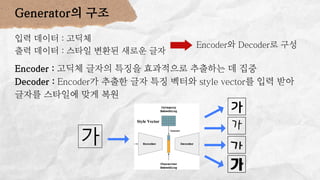
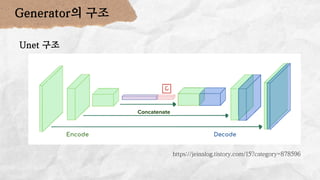



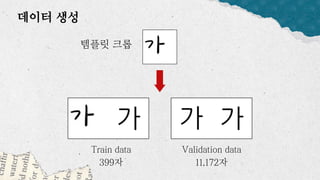







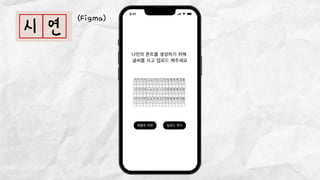
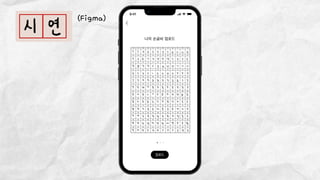
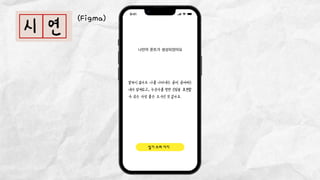
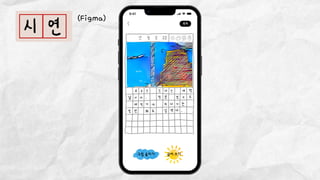


데이터 분석 프로젝트를 진행한 기린그림 팀에서는 아래와 같은 프로젝트를 진행했습니다. 기린그림 팀은 사용자의 글씨체를 학습하여 나만의 폰트로 일기를 쓰고, 사진을 업로드 하면 직접 그림을 그린 것처럼 변환하여 그림일기를 쓸 수 있도록 하는 프로젝트를 진행 했습니다. 16기 김유진 이화여자대학교 과학교육과 17기 김송성 고려대학교 통계학과 17기 박종은 연세대학교 언더우드국제학부 17기 여해인 동덕여자대학교 컴퓨터학과 17기 이보림 중앙대학교 소프트웨어학부
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [YouPlace 팀] : 카프카와 스파크를 활용한 유튜브 영상 속 제주 명소 검색](https://cdn.slidesharecdn.com/ss_thumbnails/10youplace-220124105901-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [#인스타툰 팀] : 해시태그 기반 인스타툰 추천 챗봇](https://cdn.slidesharecdn.com/ss_thumbnails/random-220728125517-c1a27331-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [하둡메이트 팀] : 하둡 설정 고도화 및 맵리듀스 모니터링](https://cdn.slidesharecdn.com/ss_thumbnails/random-220728094615-7bbbfc3e-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [코끼리책방 팀] : 사용자 스크랩 내용 기반 도서 추천](https://cdn.slidesharecdn.com/ss_thumbnails/random-220728094946-1e72ce02-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [WHY 팀] : 나만의 웹툰일기 Toonight](https://cdn.slidesharecdn.com/ss_thumbnails/whytoonight-220728094742-132fa7c2-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [개미야 뭐하니?팀] : 투자자의 반응을 이용한 실시간 등락 예측(feat. 카프카)](https://cdn.slidesharecdn.com/ss_thumbnails/06-220124105013-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 14회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [카페 어디가?팀] : 카페 및 장소 추천 서비스](https://cdn.slidesharecdn.com/ss_thumbnails/seoulyumyum-210806020316-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MarketIN팀] : 디지털 마케팅 헬스체킹 서비스](https://cdn.slidesharecdn.com/ss_thumbnails/09marketin-220124105610-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [쇼미더뮤직 팀] : 텍스트 감정추출을 통한 노래 추천](https://cdn.slidesharecdn.com/ss_thumbnails/07-220124105215-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [BAOBAB 팀] : 반려동물 미용업 모바일 서비스 분석](https://cdn.slidesharecdn.com/ss_thumbnails/baobab-220728095441-2b81735a-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Find Your Style 팀] : 사용자 이미지 라벨링을 통한 의류 추천 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/04findyourstyle-220124104046-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 17회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [힐링세포들] : MHTI (Mental Health Type Indicator)](https://cdn.slidesharecdn.com/ss_thumbnails/mhti-230220153518-9135d0db-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [리뷰의 재발견 팀] : 이커머스 리뷰 유용성 파악 및 필터링](https://cdn.slidesharecdn.com/ss_thumbnails/03-220124103455-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 18회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [보아酒] : 리뷰 감정분석을 통한 전통주 추천 서비스](https://cdn.slidesharecdn.com/ss_thumbnails/pdf-230809122213-2c021e29-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Secret X 팀] : XAI를 활용한 수능 영어영역 문제풀이](https://cdn.slidesharecdn.com/ss_thumbnails/xai-220728094640-df53ef35-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Hands-on 팀] : 수어 번역을 통한 위험 상황 속 의사소통 시스템 구축](https://cdn.slidesharecdn.com/ss_thumbnails/08handson-220124105412-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 17회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Catch, Traffic!] : 지하철 혼잡도 및 키워드 분석 데이터 파이프라인 구축](https://cdn.slidesharecdn.com/ss_thumbnails/catchtrafficppt-230220154703-8361d63a-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 17회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [굿아이디어스] : 아이디어스 작가를 위한 비지니스 대시보드](https://cdn.slidesharecdn.com/ss_thumbnails/random-230220152921-e5f24b59-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [보야져 팀] : 기업연계프로젝트 3종세트 [마케팅시각화/서비스기획/분석시스템 구축]](https://cdn.slidesharecdn.com/ss_thumbnails/3pdf-220728094525-4e6eef82-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 17회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [시켜줘, 보아즈 명예경찰관] : 보이스피싱 탐지 알고리즘](https://cdn.slidesharecdn.com/ss_thumbnails/random-230221083238-ec8e8f45-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Cm:)e팀] : 이커머스 고객경험 관리 분석](https://cdn.slidesharecdn.com/ss_thumbnails/01cmile-220124102549-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 14회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [대법관 김보아즈팀] : 일상 속 뉴스를 신속하게 ! 뉴스 속 판례를 정확하게 !](https://cdn.slidesharecdn.com/ss_thumbnails/pinprecedentsinnews-210806014000-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 17회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [ztyle] : 손그림 의류 검색 서비스](https://cdn.slidesharecdn.com/ss_thumbnails/ztyle-230221082810-938747b1-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [로깅줍깅] : 로그 스트림 파이프라인 여행기](https://cdn.slidesharecdn.com/ss_thumbnails/02-220124102706-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Indus2ry 팀] : 2022산업동향- 편의점 & OTT 완벽 분석](https://cdn.slidesharecdn.com/ss_thumbnails/05indus2ry-220124104616-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 17회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [중고책나라] : 실시간 데이터를 이용한 Elasticsearch 클러스터 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/random-230220154251-7145ba84-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [마페터 팀] : 고객 페르소나를 활용한 마케팅 전략 대시보드](https://cdn.slidesharecdn.com/ss_thumbnails/marpeter-220728094707-57b4b232-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Stalker 팀] : 감정분석을 통한 MBTI 기반 개인별 투자 성향 분석](https://cdn.slidesharecdn.com/ss_thumbnails/stalkermbti-220728094055-0258bbe7-thumbnail.jpg?width=640&height=640&fit=bounds)

















![제 18회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [분모자] : 분류 모자이크](https://cdn.slidesharecdn.com/ss_thumbnails/random-230809121358-f2742361-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018] 딥러닝을 이용한 카메라 앱 개발](https://cdn.slidesharecdn.com/ss_thumbnails/machinebigdata03purblic-190212053258-thumbnail.jpg?width=640&height=640&fit=bounds)

![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [OnLog]: Real-time Edge-to-Cloud Data Pipeline fo...](https://cdn.slidesharecdn.com/ss_thumbnails/3-4boaz23rdconferenceonlog-260204093729-11983ba7-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [F4] : 시켜줘, 금잔디 명예 플로리스트](https://cdn.slidesharecdn.com/ss_thumbnails/3-3boaz23rdconferencef4-260204011323-1cb48ec9-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [픽미] : 디저트 큐레이팅 플랫폼, 딸기로픽을 위한 데이터 기반 의사결정 프로세스 구축](https://cdn.slidesharecdn.com/ss_thumbnails/3-2boaz23rdconference-260203102931-15458767-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [셋이어때] : 헬퍼잇](https://cdn.slidesharecdn.com/ss_thumbnails/2-3boaz23rdconference-260203102432-6c8c7ed6-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [어벤정스] : ToonP](https://cdn.slidesharecdn.com/ss_thumbnails/2-2boaz23rdconference-260203102006-3a01358e-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [If Lab] : 실시간 투표 커뮤니티 서비스 기반 데이터 파이프라인 구축 및 성능 검증](https://cdn.slidesharecdn.com/ss_thumbnails/2-1boaz23rdconferenceiflab-260203101556-e51663dd-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [SimAI] : Omni_모든 콘텐츠 운영을 하나로](https://cdn.slidesharecdn.com/ss_thumbnails/1-4boaz23rdconferencesimai-260203101225-d673a594-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [JJAI] : Re:Buy - 고객 행동 패턴 기반 재구매 시점 예측 개인화 CRM 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/1-3boaz23rdconferencejjai-260203100705-ab1ce027-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [백 투 더 엔지] : 분산환경 주문 이벤트 처리 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/1-2boaz23rdconference-260203100241-73ce0aa8-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [북적북적] : 데이터 기반 독립출판사,서점 경영지원 대시보드](https://cdn.slidesharecdn.com/ss_thumbnails/1-1boaz23rdconference-260203093712-78abc1a0-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [토이스토리] : Wispy](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250803064626-64a49e3a-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [청진스] : Multi-Label Lung Sound Classification ba...](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801124724-469662d6-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [직행복] : 실시간 로그 처리 기반 추천시스템](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801124036-52794fc9-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [영웅호걸] : Context-Aware Real-time Sentiment based ...](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801123333-f123549e-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [중증외상센터] : 24시간 심전도 Holter 데이터 기반의 소아 PSVT 예측 모델 개발](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801122720-74dafab0-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [아라보아즈] : 아라보아의 장기적 성장을 위한 DDDM 환경 구축](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801031027-23699371-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [소크라데이터스] : 웨어러블 기기를 활용한 생체 신호 기반 감정 데이터 수집 및 감정 ...](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801030109-344e2af9-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [땡큐쏘아마취] : 소마챗 : Agentic RAG 기반 소아마취 업무지원 챗봇](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801025055-4240eed3-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [SNOMED] : LangGraph 기반 OMOP CDM 매핑 파이프라인 구축](https://cdn.slidesharecdn.com/ss_thumbnails/25-1snomed-250801024253-89455097-thumbnail.jpg?width=640&height=640&fit=bounds)