Downloaded 20 times


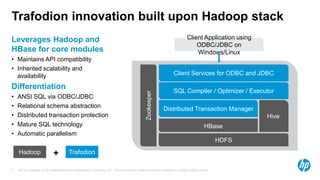

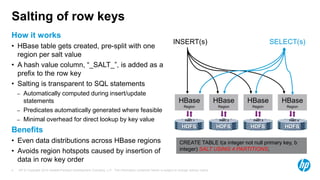



Trafodion is a transactional SQL engine that runs on Hadoop and HBase, providing ANSI SQL access via ODBC/JDBC drivers. It maintains compatibility with Hadoop APIs while adding relational schema support, distributed transactions, secondary indexes and automatic parallelism. Trafodion uses HBase for storage but adds features like ACID compliance across rows and tables and more optimized performance for transactional workloads. By running SQL on Hadoop, Trafodion allows users to leverage existing SQL skills while gaining scalability and flexibility of big data platforms.



































































