
Downloaded 41 times


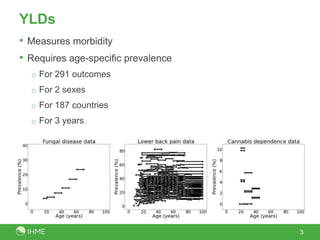


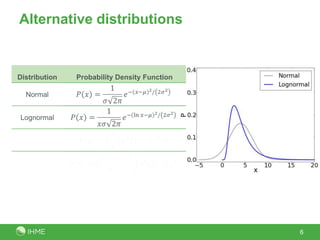




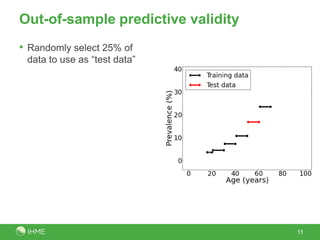

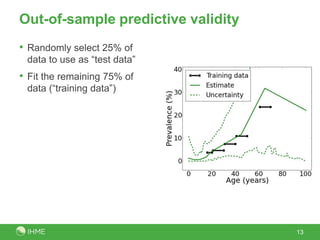


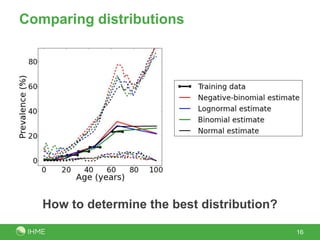

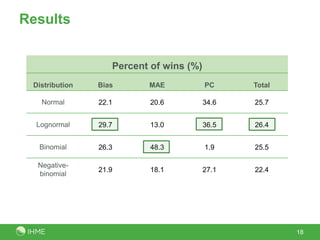


The document discusses the robustness of the meta-regression model using dismod-mr, focusing on the choice of distribution for data analysis in the Global Burden of Disease Study 2010. It evaluates the performance of various distributions (normal, lognormal, binomial, negative-binomial) through out-of-sample predictive validity and concludes that the lognormal distribution typically performs best, although the choice of distribution has minimal impact on results. Further investigation is suggested to determine optimal conditions for different distributions based on covariates and data volume.



































































