


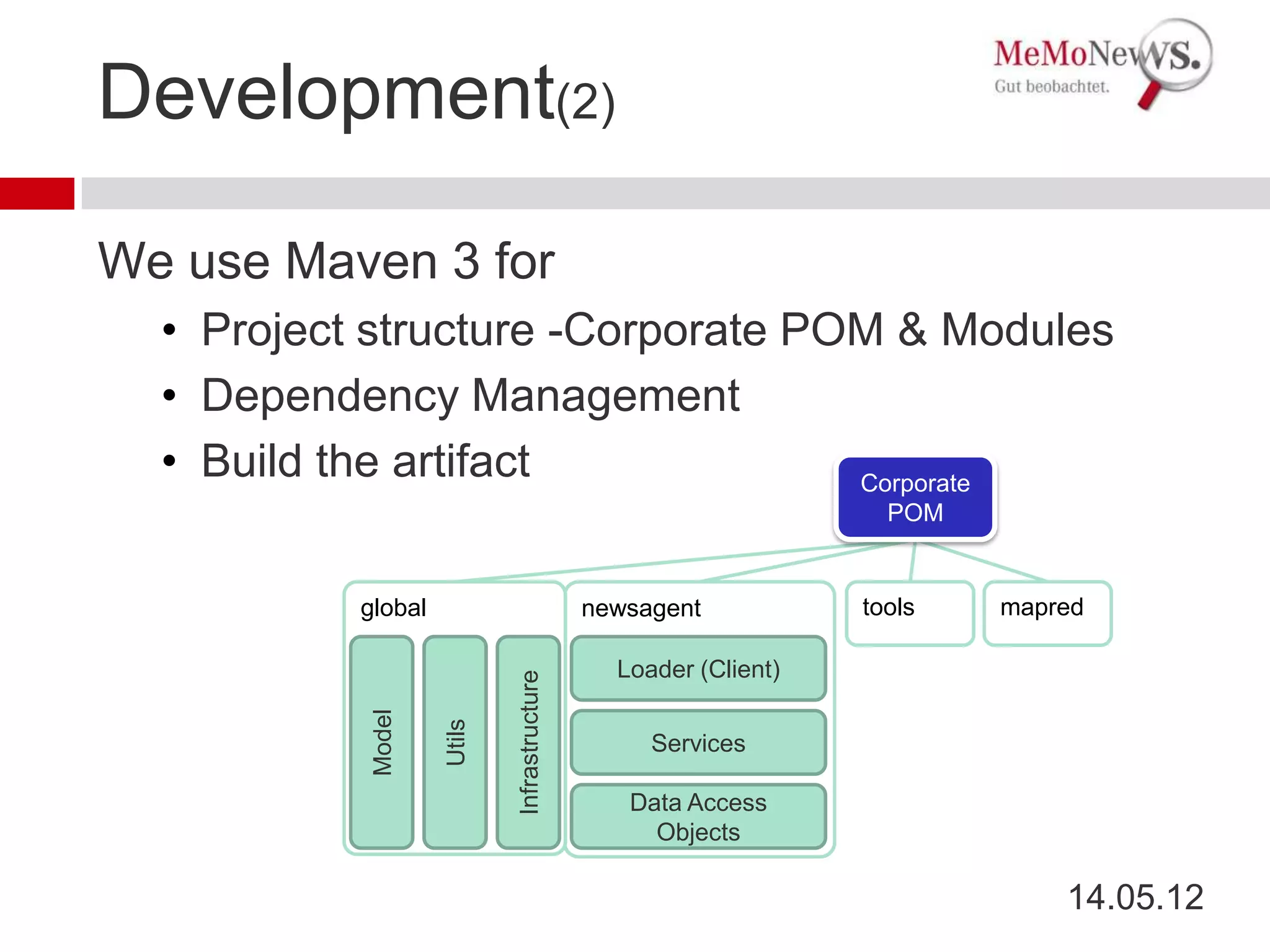

















This document discusses development, testing, and deployment practices for applications in the Hadoop ecosystem. It describes the architecture of a distributed news aggregation application built on Spring, Hadoop, HBase, and Zookeeper. It outlines the use of tools like Maven, MapReduce, Pig, and Hadoop testing utilities. Automated deployment is done with Capistrano. Other devops tools mentioned include Azkaban, Jenkins, Git, Icinga, Ganglia, and Graphite.



































































