Download to read offline



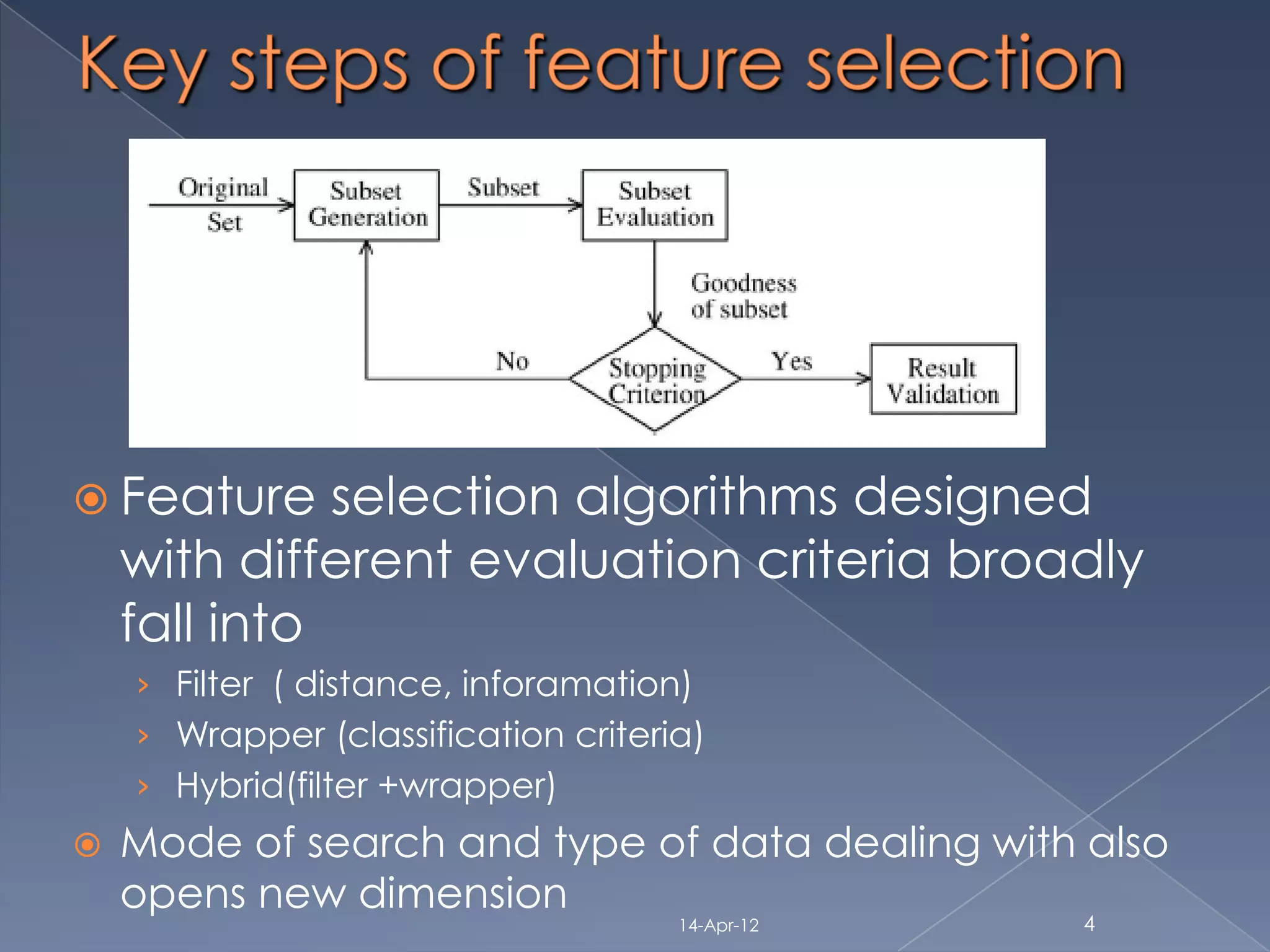
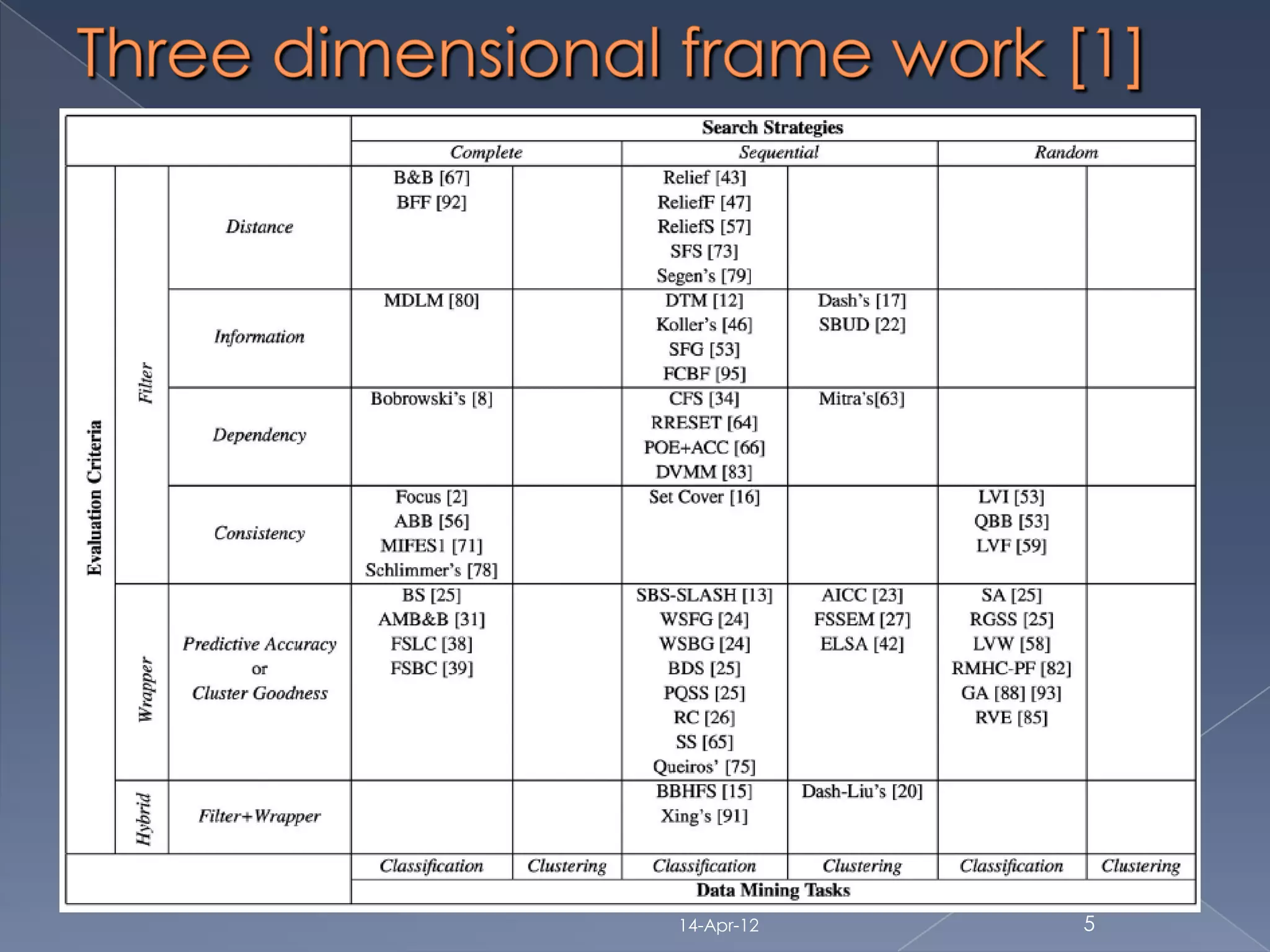

Feature selection based on mutual
information [H.Peng 2005](covers wrapper: {filter:
information+ classifier bayesian}search: sequential and classification)
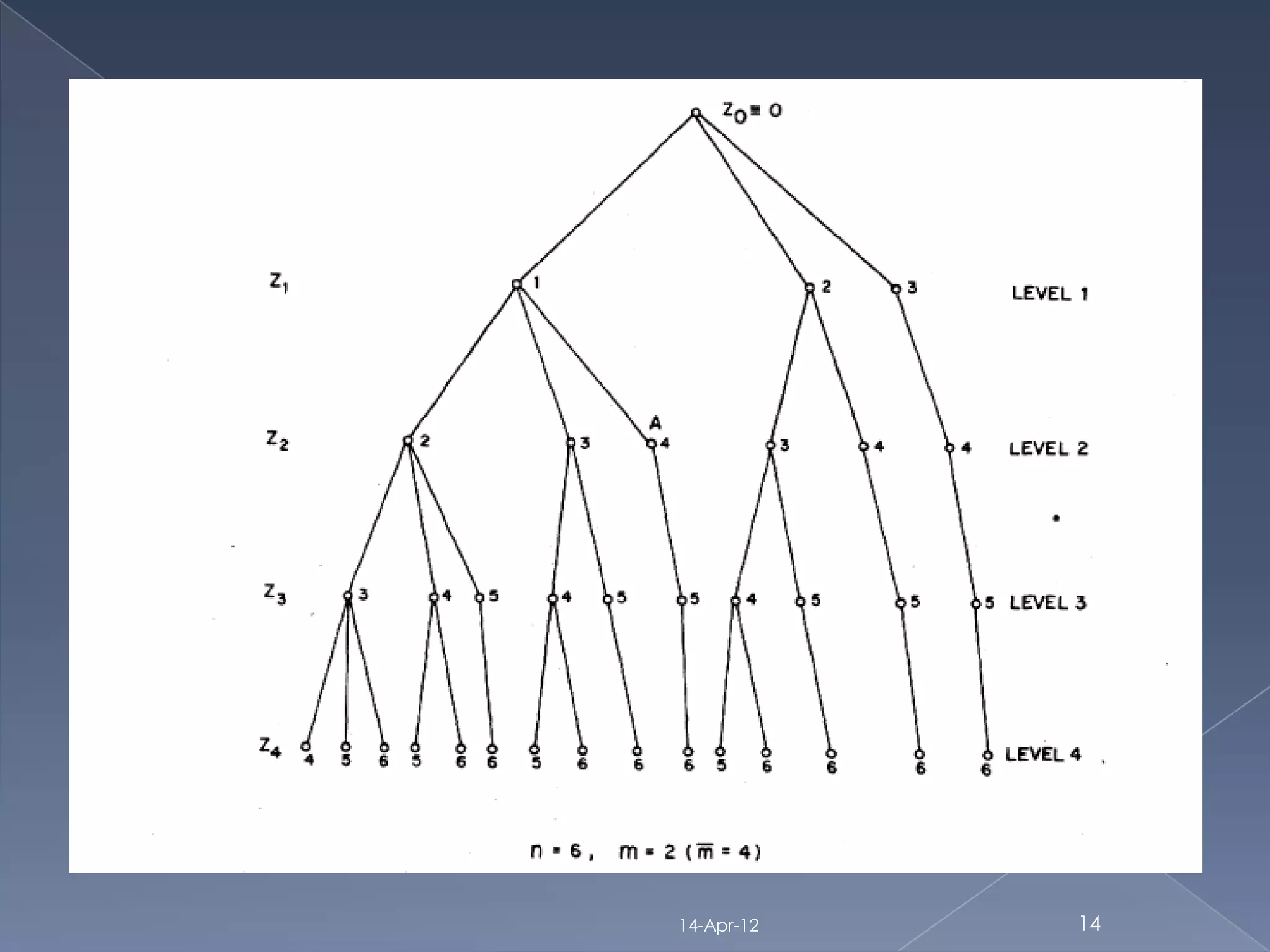
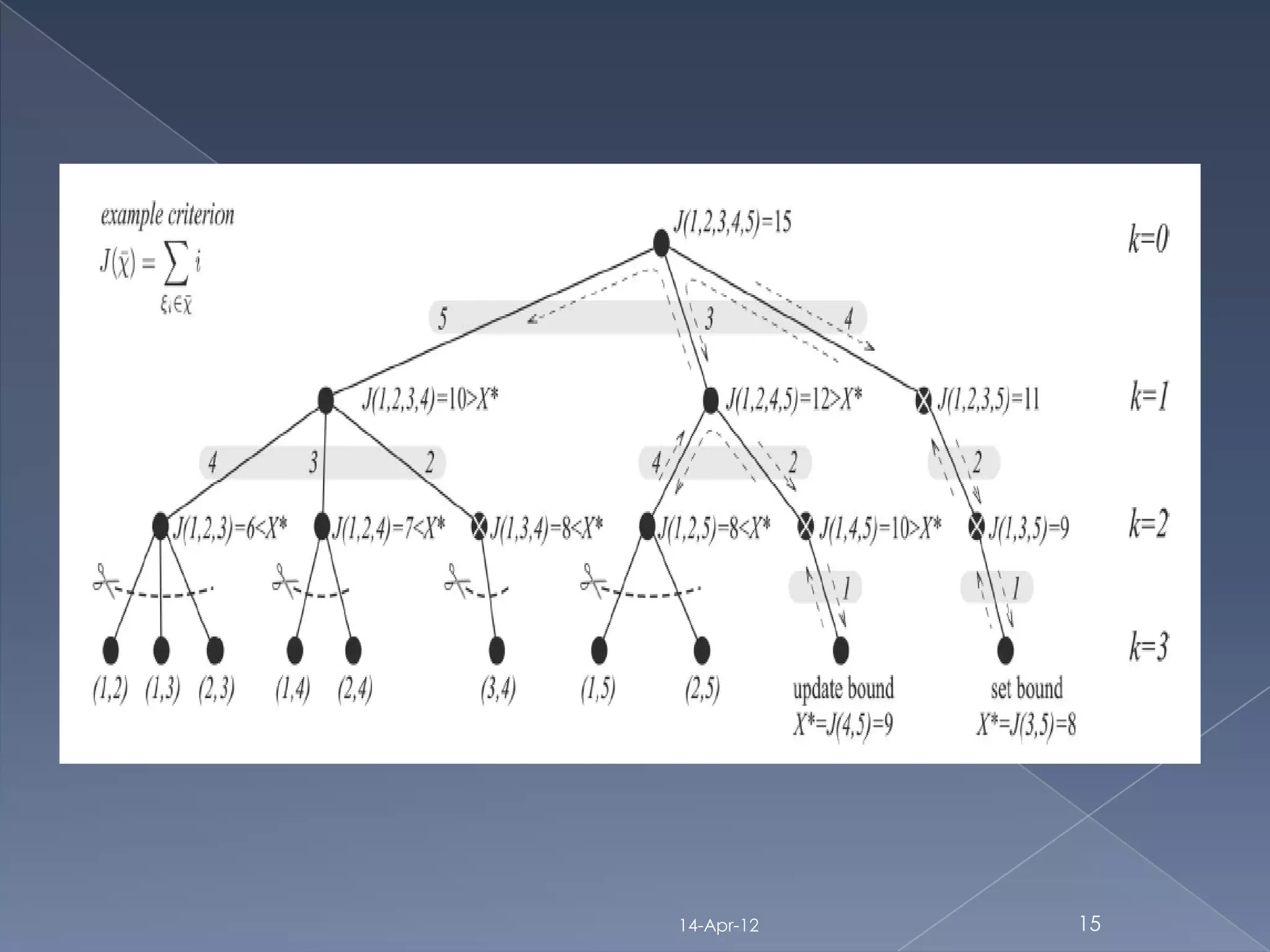
A branch and bound algorithm for
feature subset selection[P.M.Narendra
1977] (covers filter: distance search: complete and classification)
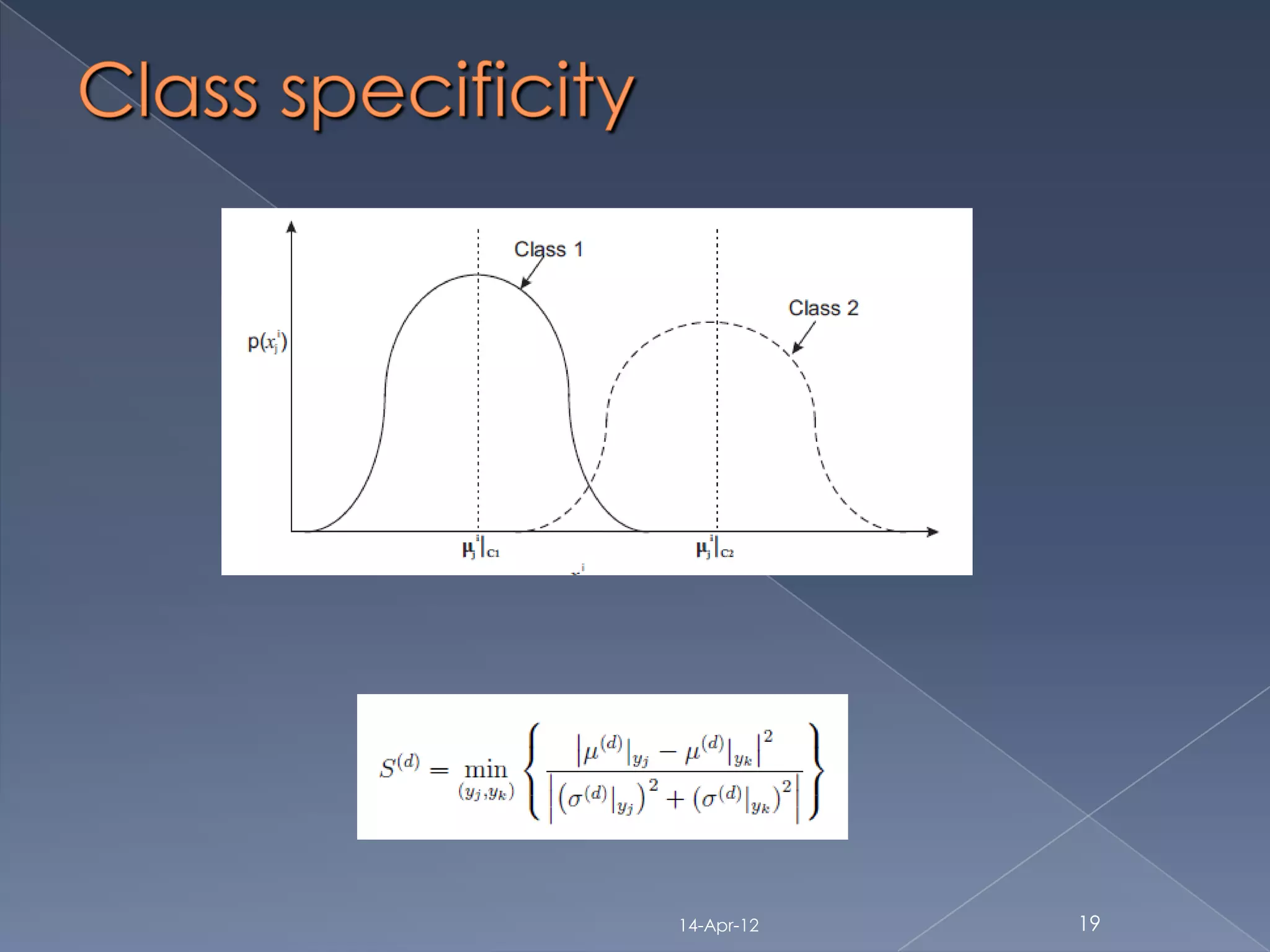
Feature usability Index [D.Sheet 2010]
14-Apr-12 6](https://image.slidesharecdn.com/11mm91r05-130209105016-phpapp02/75/11-mm91r05-6-2048.jpg)










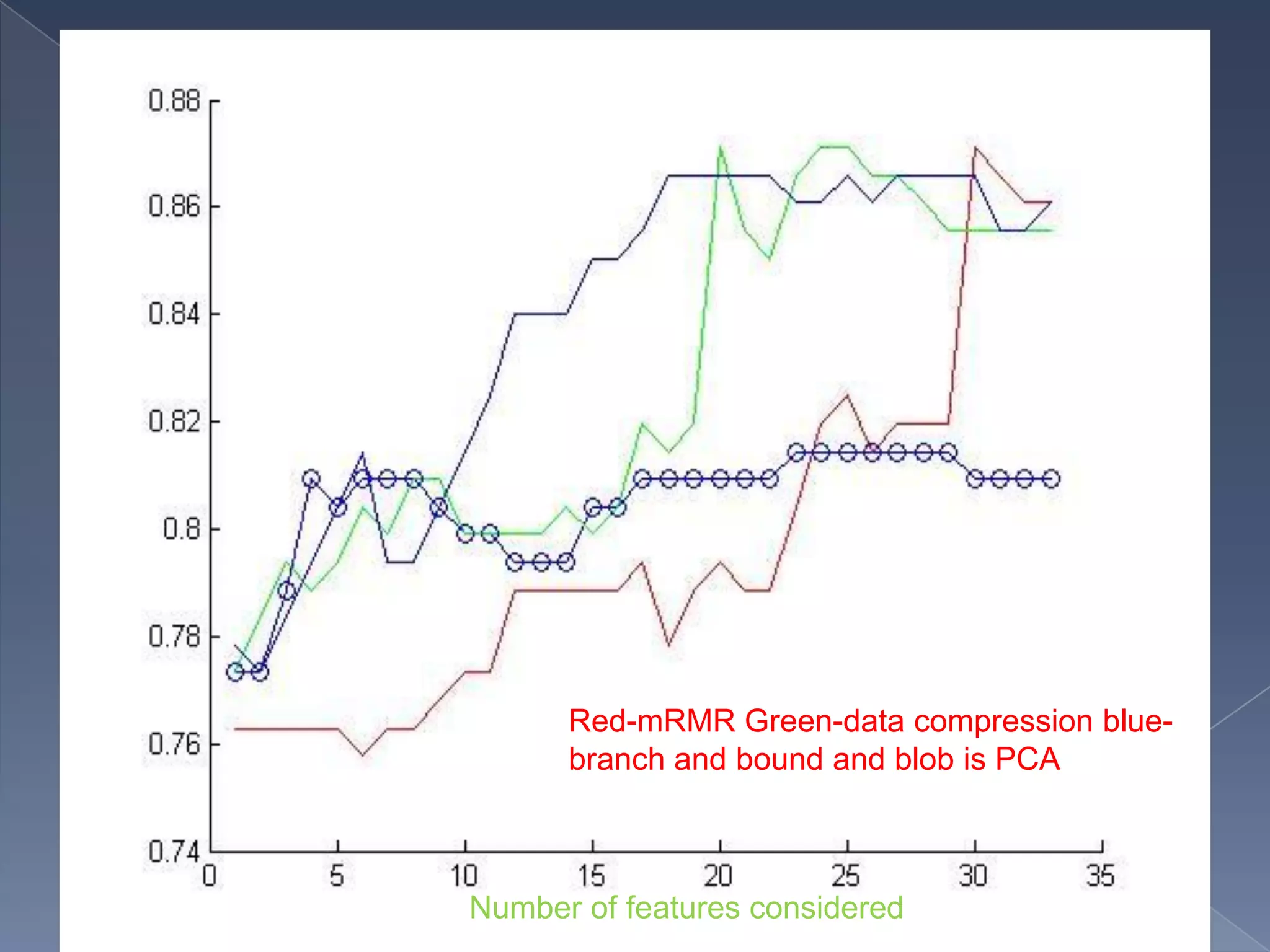
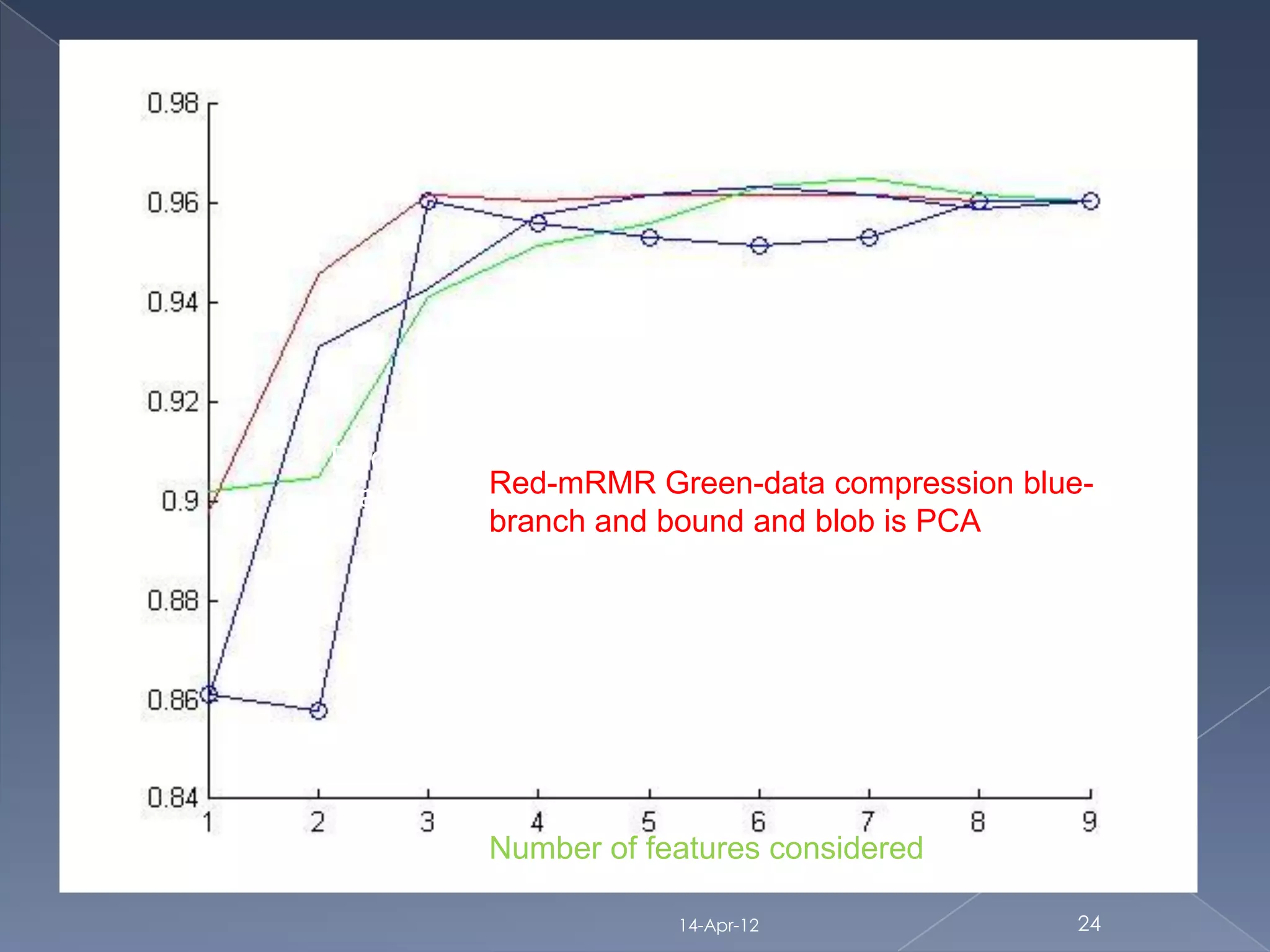
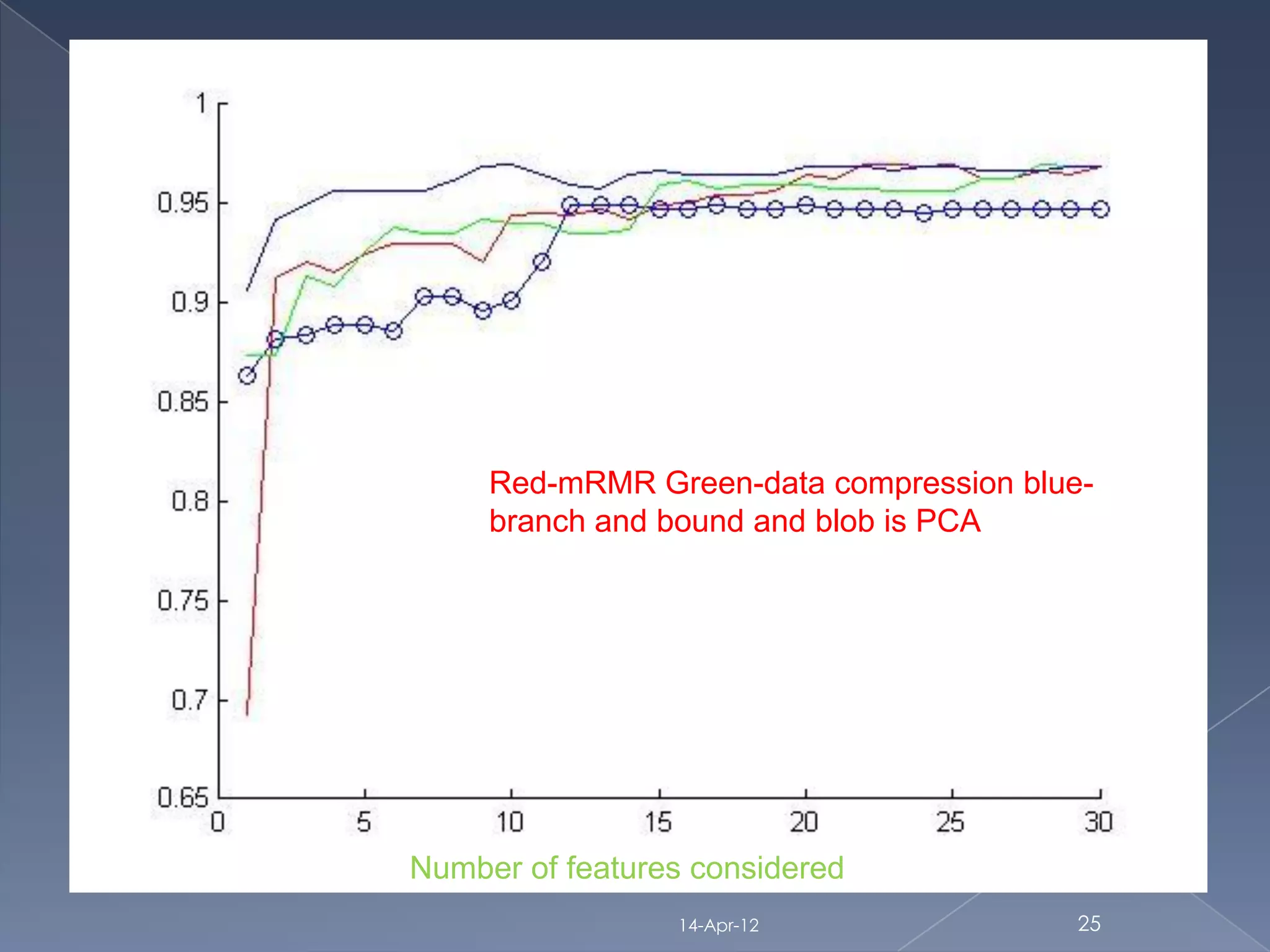


The document discusses dimensionality reduction techniques for reducing high-dimensional data to fewer dimensions. It categorizes dimensionality reduction into feature extraction and feature selection. Feature extraction transforms features to generate new ones, while feature selection selects the best original features. The document then discusses several feature selection algorithms from different categories (filter, wrapper, hybrid) and evaluates their performance on cancer datasets. It finds that linear support vector machines using mRMR feature selection provided the best results.






















































