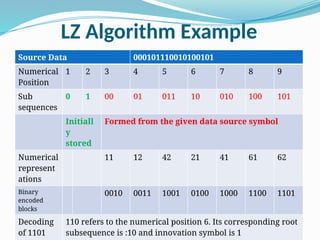
The document discusses Lempel-Ziv coding and its comparison with Huffman coding, highlighting differences in their methodologies and efficiency when compressing data. While Huffman coding requires prior statistical knowledge of the source, Lempel-Ziv coding operates on sequences not previously encountered, allowing for more efficient data compression in certain contexts. The Lempel-Ziv algorithm parses the data into segments, creates a codebook for these segments, and encodes them into a binary form, achieving a higher compression rate than Huffman coding in specific scenarios.