Code로 이해하는 RNN
TheUnreasonable Effectiveness of Recurrent Neural Networks
에서 학습용으로 제공하는
“minimal character-level RNN language mode” 의 코드 이해
- 약 100 line 정도의 코드를 통해 BPTT의 개념을 확인
- 상태가 어떻게 BPTT를 통해서 역전파 되고,
- Vanishing gradient 문제를 유발하늦지 이해
freepsw
2.
1) Character RNN흐름
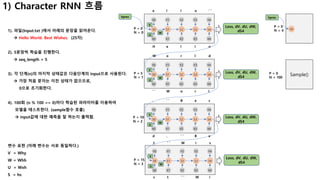
1). 파일(Input.txt )에서 아래의 문장을 읽어온다.
à Hello World. Best Wishes. (25자)
2). 5문장씩 학습을 진행한다.
à seq_length = 5
3). 각 단계(n)의 마지막 상태값은 다음단계의 input으로 사용된다.
à 가장 처음 문자는 이전 상태가 없으므로,
0으로 초기화한다.
4). 100회 (n % 100 == 0)마다 학습된 파라미터를 이용하여
모델을 테스트한다. (sample함수 호출)
à input값에 대한 예측을 잘 하는지 출력함.
변수 표현 (아래 변수는 서로 동일하다.)
V = Why
W = Whh
U = Wxh
S = hs
S0 S1 S2 S3 S4
Y0 Y1 Y2 Y3 Y4
X0 X1 X2 X3 X4
s t ‘ ‘ W i
t ‘ ‘ W i s
Loss, dV, dU, dW,
dS4
U
W
V
P = 15
N = 3
S0 S1 S2 S3 S4
Y0 Y1 Y2 Y3 Y4
X0 X1 X2 X3 X4
H e l l o
e l l o ‘ ‘
Loss, dV, dU, dW,
dS4
U
W
V
P = 0
N = 0
S0 S1 S2 S3 S4
Y0 Y1 Y2 Y3 Y4
X0 X1 X2 X3 X4
‘ ‘ W o r l
W o r l d
Loss, dV, dU, dW,
dS4
U
W
V
P = 5
N = 1
S0 S1 S2 S3 S4
Y0 Y1 Y2 Y3 Y4
X0 X1 X2 X3 X4
d . ‘ ‘ B e
, ‘ ‘ B e s
Loss, dV, dU, dW,
dS4
U
W
V
P = 10
N = 2
P = 0
N = 4 S0
hprev hprev
Sample()P = 0
N = 100
3.
2) Code 구조
RNN실행에필요한 input, output, hidden layer 관련 변수 설정
정해진 단어 갯수(seq_length=5) 별로 학습을 진행 (무한 loop)
- 학습할 전체 문자가 25개
- 5개씩 학습하게 되는데,
- 이때 마지막 5개 input 문자 “shes.” 가 예측할 target문자인
- 26번째 문자가 존재하지 않아서 “shes.”에 대한 학습은 하지 않는다.
모든 단계에서 Loss를 통해서 파라미터를 최적화 하고, à lossFun(…)
매 100번 째에 학습된 모델을 테스트해 본다. à sample(…)
2) Training 데이터준비
학습할 input data와 정답(output) data 준비
• 한번에 seq_length(5) 만큼 읽고,
• Target 문자를 예측하도록 학습한다.
p : 0 input : [5, 2, 6, 6, 7]
p + seq_length + 1 = 6
input(ch) : Hello
target(ch) : ello
p : 5
p + seq_length + 1 = 11
input(ch) : Worl
target(ch) : World
p : 10
p + seq_length + 1 = 16
input(ch) : d. Be
target(ch) : . Bes
p : 15
p + seq_length + 1 = 21
input(ch) : st Wi
target(ch) : t Wis
p : 20
p + seq_length + 1 = 26
5글자씩만 읽으니까,
마지막 “shes.” 까지 학습하지 못하는 문제가 있다.
이 부붐은 무시할 것인지, 마지막 까지 학습할 수 있
도록 할지는 적용영역별로 결정하여 로직을 추가해야
한다
또는 word-rnn으로 해결이 가능할것 같기도..
아래 규칙에 따라 처음 loop( n == 0) 이거나,
읽을 () 사이즈가 전체보다 클 경우 상태값을 초기화 하고,
문장의 처음부터 읽도록 한다 (p=0)
if p + seq_length + 1 >= len(data) or n == 0:
hprev = np.zeros((hidden_size, 1)) # reset RNN memory
p = 0 # go from start of data
p += seq_length # p : 다음에 읽어올 input 문자의 시작 index
6.
S0 S1 S2S3 S4
YS0 YS1 YS2 YS3 YS4
X0 X1 X2 X3 X4
H e l l o
U
W
Vhprev
inputs
targets
0 1 2 3 4t
e l l o ‘ ‘
PS0 PS1 PS2 PS3 PS4
E0 E1 E2 E3 E4
Inputs 문자열을 기준으로 tagets 문자열을 예측하고, loss(E)를 계산
• Input : ‘Hello’ (입력된 Hello에서 H를 제외한 나머지 5개 단어 학습)
• Target : ‘ello ‘ (H à e, He à l, Hel à l, Hell à o, Hello à ‘ ‘
• hprev : 상태값 (첫문자에서는 0로 초기화됨)
단계별 변수 설명
• YS = V * S + bh
• 상태값(S)와 파라미터 V, bh를 이용한 선형함수 계산 값
• PS = softmax(YS)
• YS 값을 0~1 사이의 확률값으로 변환
• E = -log(PS)
• 자연로그 함수를 이용하여 정답과의 거리를 계산 (loss를 계산)
• 예를 들어 PS의 값이 1(정답)이라면 E는 0으로 loss가 없다.
• PS가 0(오답)이라면 자연상수 e로 무한대의 값을 가진다
3) lossFun 함수 – Forward : Loss(Error) 계산
Loss(E)의 총합
V = Why
W = Whh
U = Wxh
S = hs
7.
3) lossFun 함수– Forward : Loss(Error) 계산 – 1
xs : [input_length][vocab_size] 배열
• xs[t][inputs[t]] = 1
hs[t] = np.tanh(np.dot(Wxh, xs[t]) + np.dot(Whh, hs[t - 1]) + bh)
(100, 14) * (14, 1) + (100, 100) * (100, 1) + (100, 1)
(100, 1) + (100, 1) + (100, 1)
Input 값과 파라미터(U, W), 이전상태값을 이용하여 현재 상태값을 계산한다.
• X (xs) : inputs[t]에 해당하는 문자(one hot encoding되어 숫자로 표현)
• 예를 들어 H의 경우 5로 표현
• U (Whx) : xs에 대한 파라미터
• 𝑺 𝒕 (hs) = U * X + W * 𝑺 𝒕#𝟏 + bh
• 현재의 상태(𝑺 𝒕 )는 이전 상태(𝑺 𝒕#𝟏)에 영향을 받도록 구성되어 있다.
S0 S1 S2 S3 S4
YS0 YS1 YS2 YS3 YS4
X0 X1 X2 X3 X4
H e l l o
U
W
Vhprev
inputs
targets
0 1 2 3 4t
e l l o ‘ ‘
PS0 PS1 PS2 PS3 PS4
E0 E1 E2 E3 E4
{0: array([[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 1.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.]])} to char : H
{0: array([[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 1.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.]]),
1: array([[ 0.],
[ 0.],
[ 1.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.]])} to char : e
t = 0 t = 1
(14, 1)
(14, 1)
{0: array([[ -8.13582810e-03],
[ -1.57227229e-03],
[ -2.00276238e-02],
[ -4.71613068e-04],
[ -1.08314518e-02],
[ 1.17515240e-02],
[ 8.16061705e-03]]),
-1: array([[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.]])}
xs hs
t = 0
8.
3) lossFun 함수– Forward : Loss(Error) 계산 – 2
xs : [input_length][vocab_size] 배열
• xs[t][inputs[t]] = 1
hs[t] = np.tanh(np.dot(Wxh, xs[t]) + np.dot(Whh, hs[t - 1]) + bh)
ys[t] = np.dot(Why, hs[t]) + by
(14, 100) * (100, 1) + (14, 1)
(14, 1) + (14, 1)
ps[t] = np.exp(ys[t]) / np.sum(np.exp(ys[t]))
loss += -np.log(ps[t][targets[t], 0])
S0 S1 S2 S3 S4
YS0 YS1 YS2 YS3 YS4
X0 X1 X2 X3 X4
H e l l o
U
W
Vhprev
inputs
targets
0 1 2 3 4t
e l l o ‘ ‘
PS0 PS1 PS2 PS3 PS4
E0 E1 E2 E3 E4
현재 상태와 V 파라미터를 이용하여 계산한 결과를 이용하여 정답의 확률 및 Loss(Error)를 계산
• YS = V * S + bh
• 상태값(S)와 파라미터 V, bh를 이용한 선형함수 계산 값
• PS = softmax(YS)
• YS 값을 0~1 사이의 확률값으로 변환
• E = -log(PS)
• 자연로그 함수를 이용하여 정답과의 거리를 계산 (loss를 계산)
• 예를 들어 PS의 값이 1(정답)이라면 E는 0으로 loss가 없다.
• PS가 0(오답)이라면 자연상수 e로 무한대의 값을 가진다
ps[0][targets[0], 0] = 0.0714479
np.log(0.0714479) = -2.63878676622
loss += -(-2.63878676622)
- ps에는 모든 문자별로 예측한 확률이 저장되어 있음. (100%기준)
- 이 중 정답(여기서는 index 2번)의 값이 높은지 비교함.
- 값이 1과 가깝다면 잘 예측한것으로 판단할 수 있음.
- 여기서는 0.07로 예측률이 너무 낮음. 전체적으로 예측률의 차이가 없다고 보
여짐.(학습이 안되어 있음)
Log(1) = 0이므로, 이 말은 해당 값이 1에 가까우면 loss도 작아진다는 뜻.
학습을 통해 계산된 확률(ps)이 정답의 index에서 1에 가깝도록 weight를
조정해야 한다
참고로 Log(x) = a : 자연상수 e를 a승 하면, x가 된다는 의미.
모든 입력문자 (여기서는 5자)별로 loss를 계산하여 합산한다.
마이너스(-)를 곱한 이유는 log의 결과가 음수로 나오므로, 이를 양수로 변환하기 위함 (loss
를 양수로 계산하기 편함)
loss를 계산하는 부분 à
cross_entropy
http://cs231n.github.io/neural-
networks-case-study/
9.
4) lossFun 함수– Back Propagation – 1단계
가장 마지막 결과인 Loss(E)를 기준으로 모든 파라미터를 back propagation을 통해서 계산한다.
1). 먼저 정답의 score(ys)가 Loss(E)에 미치는 영향 (gradient)를 계산
• 이 부분은 정답 y가 1인 경우에 대한 간단한 공식이 있다.
• http://cs231n.github.io/neural-networks-case-study
•
&'(
&)*(
= 𝑝𝑠. − 1 = 𝑑𝑦
2). V가 E에 미치는 gradient를 계산
• V(Why)와 연관된 변수는 상태(S), Loss에 대한 score의 기울기가 있다.
• Chain rule을 적용하여 V에 대한 gradient를 계산하면
• 아래와 같은 결과가 도출된다.Wxh
xs
Whh
hs(t-1)
bh
x
x +
dWxh
xs
Whh
hs(t-1)
𝒅𝒉𝒏𝒆𝒙𝒕
dbh
x
x +
6
7
8
9
BPTT (Back Propagation Through Time)
Why
hs
by
+ tanh
dWhy
dh
dby
+ tanhg
g
dhraw
2
3
4
5
ysx
dyx
1
ps
softmax
ps -1
Loss(E)
cross entropy
+
+
𝜕𝐸.
𝜕𝑦𝑠.
= 𝑝𝑠. − 11
2
𝜕𝐸.
𝜕𝑉
=
𝜕𝐸.
𝜕𝑦𝑠.
∗
𝜕𝑦𝑠.
𝜕𝑉
= 𝑑𝑦 ∗ 𝑠.
𝒚𝒔𝒕 = 𝑽 ∗ 𝒔𝒕 + 𝒃𝒚
𝜕𝑦𝑠.
𝜕𝑉
= 𝑠.
𝜕𝑦𝑠.
𝜕𝑠.
= 𝑉
𝜕𝑦𝑠.
𝜕𝑏𝑦
= 1
𝑬 𝒕 = −log(𝑦.)
𝒑𝒔𝒕 = softmax(𝒚𝒔𝒕)
=
OPQR
∑ O
PQT
T
dy
dWhy
Chain rule 적용
V = Why
W = Whh
U = Wxh
S = hs
10.
4) lossFun 함수– Back Propagation – 2단계
dWxh
xs
Whh
hs(t-1)
𝒅𝒉𝒏𝒆𝒙𝒕
dbh
x
x +
6
7
8
9
BPTT (Back Propagation Through Time)
dWhy
dh
dby
+ tanhg
dhraw
2
3
4
5
dyx
1
ps -1
Loss(E)
+
현재 상태(S)가 현재 loss(E)에 미치는 영향을 계산해 보자. è 여기서 S는 tanh를 적용한 상태(S)
그런데 RNN 구조상 현재 상태(𝑺𝒕) 는 이전 상태(𝑺𝒕#𝟏)에 영향을 받는 구조이다.
à 𝒈 𝒕 = 𝑼 ∗ 𝒙𝒕 + 𝑾 ∗ 𝒔𝒕#𝟏 + 𝒃𝒉
à 𝒔𝒕 = tanh 𝑔.
따라서 𝑺𝒕 는 이전의 상태를 back propagation 시에 반영해야 한다.
• 여기서 이전상태는 backward 방향에서의 이전상태이다.
• 예를 들어, backward에서는 Time step의 마지막에서 거꾸로 계산하게 되므로,
• 현재 t=4라면 그 이전(t=5)인 상태는 없으므로 𝑺 𝟓는 0이 된다.
1) 먼저 단순하게 이전 상태가 없다고 생각하고 gradient를 계산해 보자.
•
&'(
&*(
=
&'(
&)*(
∗
&)*(
&*(
= 𝑝𝑠. − 1 ∗ 𝑉 = 𝑑𝑦 ∗ 𝑉
2) 그럼 이전 상태가 있는 경우, 이전 상태는 어떻게 반영할까?
• Backward 방향으로 현재 시점의 상태가 영향을 미치는 모든 Loss(E)를 계산하여 더해주어야
한다.
• 예를들어 (t=4)라면 backward 방향으로 영향을 주는 상태가 없고,
• (t=2) 이라면 𝑺 𝟐가 𝐸n, 𝐸o , 𝐸p에 영향을 주게 된다. 따라서 아래와 같이 2개의 값을 더해준다.
•
&'q
&*q
=
&'q
&*q
+
&'r
&*q
+
&'s
&*q
• 이렇게 이전의 상태가 Loss에 미치는 영향을 다 합해줘야 하는데, 이를 계산해 놓은 것이
“ 𝒅𝒉𝒏𝒆𝒙𝒕” 이다.
𝜕𝐸.
𝜕𝑠.
3dh
S0 S1 S2 S3 S4
Tanh(U*X + W*𝑺#𝟏 + bh)
Tanh(U*X + W*𝑺 𝟎 + bh)
Tanh(U*X + W*𝑺 𝟏 + bh)
S0 = 5
로 가정
Tanh(5) =
0.9
Tanh(0.9)
= 0.74
Tanh(0.74)
= 0.62
S0가 미치는 영향도가 점점
작아짐.
Vanishing gradient 문제
5) Sample함수로 다음단어 예측 - 1
Sample 함수의 파라미터
• sample_ix = sample(hprev, inputs[0], 25)
• hprev : state (100, 1) 정보 (문장의 처음에 0으로 초기화) à xavier로 초기화 하면 좋아질까?
• Input[0] : input문장(5글자)의 첫번째 문자의 index (Hello à H à 5) (char_to_ix 에 저장된 index)
• 25 : input[0]를 입력으로 25번 loop를 돌면서 25개의 output 문자를 예측한다.
• 반환값 : 예측한 문자열의 index 배열 (1, 25)
• “[2, 6, 6, 7, 0, 12, 7, 10, 6, 3, 8, 0, 1, 2, 9, 11, 0, 12, 4, 9, 6, 8, 8, 0, 1]”
• ello World. Best Wisl.. B
Input[0] = 5
n = 0
= np.tanh(np.dot(Wxh, x) + np.dot(Whh, h) + bh)
y = np.dot(Why, ) + by
p = np.exp(y) / np.sum(np.exp(y))
(14, 1)
(14, 1)
(100, 1)
ix = np.random.choice(range(vocab_size), p=p.ravel())
H
x
h
y
p
1
2
3
ix4 [[ 0.19226331]
[-3.09023869]
[ 9.50352706]
[-2.42361632]
[-3.56830588]
[-4.5526632 ]
[-0.37720546]
[-1.39742306]
[-2.69937816]
[-0.43220833]
[-1.83925515]
[-1.69037687]
[-1.92273072]
[-4.32781988]]
y
[[ 9.03763871e-05]
[ 3.39220797e-06]
[ 9.99736255e-01]
[ 6.60682628e-06]
[ 2.10310292e-06]
[ 7.85886037e-07]
[ 5.11373042e-05]
[ 1.84358410e-05]
[ 5.01453928e-06]
[ 4.84005598e-05]
[ 1.18516200e-05]
[ 1.37541809e-05]
[ 1.09024659e-05]
[ 9.84028744e-07]]
p
Input[0]인 ‘H’를 입력으로 hidden layer에서 상태값
(0)를 적용한 결과 y를 계산하고
이를 확률로 변환한 p를 추출한다.
여기서 p는 각 단어별로 정답일 확률을 의미한다.
이 예제에서는 3번째 index 2가 가장 높으므로 ‘e’를
예측하였다.
무작위로 1개의 index를 선택하는데,
p에서 비율이 높은 것에 가중치를 많이
부여해서 선택될 확률이 놀게한다.
여기서는 예상대로 2(‘e’)를 선택하였다.
2
- P를 계산하는 과정 :
- Y에서 계산된 값을 지수적으로 확장하여 비정규
화된 값으로 만든다. (np.exp(y))
- 그리고 이 값을 다시 0~1 사이의 정규화된 값으
로 변경하여 확률로 변경한다.
e
2 3
4
14.
Input[0] = 2
n= 0
H
x
h
y
p
ix
e
n = 1
e
x
h
y
p
ix
l
n = 2
l
x
h
y
p
ix
l
n = 3
l
x
h
y
p
ix
o
n = 4
o
x
h
y
p
ix
‘ ‘
n = 5
‘ ‘
x
h
y
p
ix
W
n = 24
.
x
h
y
p
ix
‘ ‘
ello World. Best Wisrld.
‘H’ 문자를 입력으로 나머지 25개의 문자
열을 예측한 결과
5) Sample함수로 다음 단어 예측 - 2
15.
6) Vanishing Gradient문제
S0 S1 S2 S3 S4
Tanh(U*X + W*𝑺#𝟏 + bh)
Tanh(U*X + W*𝑺 𝟎 + bh)
Tanh(U*X + W*𝑺 𝟏 + bh)
S0 = 5
로 가정
Tanh(5) =
0.9
Tanh(0.9)
= 0.74
Tanh(0.74)
= 0.62
S0가 미치는 영향도가 점점
작아짐.
Vanishing gradient 문제
앞에서 이전 상태를 Time Step을 통해 전달하게 되면서,
Time Step이 많아지면 기존 상태값이 거의 0으로 변환되어
BPTT시에 오래된 상태값은 gradient가 거의 사라지는(0에 가까운) 문제가 발생하게 된다.
특히 RNN은 Time step이 많아지는 특성이 있으므로,
Vanishing Gradient는 먼 상태의 값이 현재결과에 거의 영향을 주지 못하는 문제가 발생한다.
이를 해결하기 위한 다양한 방법이 있는데,
• W 행렬을 적당히(?) 잘 초기화
• ReLU 함수 사용
• 가장 최선의 해결책은 Long Short-Term Memory (LSTM) 또는 Gated Recurrent Unit (GRU) 구조
를 사용 http://aikorea.org/blog/rnn-tutorial-3/



![2) Training 데이터 준비
학습할 input data와 정답(output) data 준비
• 한번에 seq_length(5) 만큼 읽고,
• Target 문자를 예측하도록 학습한다.
p : 0 input : [5, 2, 6, 6, 7]
p + seq_length + 1 = 6
input(ch) : Hello
target(ch) : ello
p : 5
p + seq_length + 1 = 11
input(ch) : Worl
target(ch) : World
p : 10
p + seq_length + 1 = 16
input(ch) : d. Be
target(ch) : . Bes
p : 15
p + seq_length + 1 = 21
input(ch) : st Wi
target(ch) : t Wis
p : 20
p + seq_length + 1 = 26
5글자씩만 읽으니까,
마지막 “shes.” 까지 학습하지 못하는 문제가 있다.
이 부붐은 무시할 것인지, 마지막 까지 학습할 수 있
도록 할지는 적용영역별로 결정하여 로직을 추가해야
한다
또는 word-rnn으로 해결이 가능할것 같기도..
아래 규칙에 따라 처음 loop( n == 0) 이거나,
읽을 () 사이즈가 전체보다 클 경우 상태값을 초기화 하고,
문장의 처음부터 읽도록 한다 (p=0)
if p + seq_length + 1 >= len(data) or n == 0:
hprev = np.zeros((hidden_size, 1)) # reset RNN memory
p = 0 # go from start of data
p += seq_length # p : 다음에 읽어올 input 문자의 시작 index](https://image.slidesharecdn.com/codernnv1-170222044705/85/Code-RNN-5-320.jpg)

![3) lossFun 함수 – Forward : Loss(Error) 계산 – 1
xs : [input_length][vocab_size] 배열
• xs[t][inputs[t]] = 1
hs[t] = np.tanh(np.dot(Wxh, xs[t]) + np.dot(Whh, hs[t - 1]) + bh)
(100, 14) * (14, 1) + (100, 100) * (100, 1) + (100, 1)
(100, 1) + (100, 1) + (100, 1)
Input 값과 파라미터(U, W), 이전상태값을 이용하여 현재 상태값을 계산한다.
• X (xs) : inputs[t]에 해당하는 문자(one hot encoding되어 숫자로 표현)
• 예를 들어 H의 경우 5로 표현
• U (Whx) : xs에 대한 파라미터
• 𝑺 𝒕 (hs) = U * X + W * 𝑺 𝒕#𝟏 + bh
• 현재의 상태(𝑺 𝒕 )는 이전 상태(𝑺 𝒕#𝟏)에 영향을 받도록 구성되어 있다.
S0 S1 S2 S3 S4
YS0 YS1 YS2 YS3 YS4
X0 X1 X2 X3 X4
H e l l o
U
W
Vhprev
inputs
targets
0 1 2 3 4t
e l l o ‘ ‘
PS0 PS1 PS2 PS3 PS4
E0 E1 E2 E3 E4
{0: array([[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 1.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.]])} to char : H
{0: array([[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 1.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.]]),
1: array([[ 0.],
[ 0.],
[ 1.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.]])} to char : e
t = 0 t = 1
(14, 1)
(14, 1)
{0: array([[ -8.13582810e-03],
[ -1.57227229e-03],
[ -2.00276238e-02],
[ -4.71613068e-04],
[ -1.08314518e-02],
[ 1.17515240e-02],
[ 8.16061705e-03]]),
-1: array([[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.],
[ 0.]])}
xs hs
t = 0](https://image.slidesharecdn.com/codernnv1-170222044705/85/Code-RNN-7-320.jpg)
![3) lossFun 함수 – Forward : Loss(Error) 계산 – 2
xs : [input_length][vocab_size] 배열
• xs[t][inputs[t]] = 1
hs[t] = np.tanh(np.dot(Wxh, xs[t]) + np.dot(Whh, hs[t - 1]) + bh)
ys[t] = np.dot(Why, hs[t]) + by
(14, 100) * (100, 1) + (14, 1)
(14, 1) + (14, 1)
ps[t] = np.exp(ys[t]) / np.sum(np.exp(ys[t]))
loss += -np.log(ps[t][targets[t], 0])
S0 S1 S2 S3 S4
YS0 YS1 YS2 YS3 YS4
X0 X1 X2 X3 X4
H e l l o
U
W
Vhprev
inputs
targets
0 1 2 3 4t
e l l o ‘ ‘
PS0 PS1 PS2 PS3 PS4
E0 E1 E2 E3 E4
현재 상태와 V 파라미터를 이용하여 계산한 결과를 이용하여 정답의 확률 및 Loss(Error)를 계산
• YS = V * S + bh
• 상태값(S)와 파라미터 V, bh를 이용한 선형함수 계산 값
• PS = softmax(YS)
• YS 값을 0~1 사이의 확률값으로 변환
• E = -log(PS)
• 자연로그 함수를 이용하여 정답과의 거리를 계산 (loss를 계산)
• 예를 들어 PS의 값이 1(정답)이라면 E는 0으로 loss가 없다.
• PS가 0(오답)이라면 자연상수 e로 무한대의 값을 가진다
ps[0][targets[0], 0] = 0.0714479
np.log(0.0714479) = -2.63878676622
loss += -(-2.63878676622)
- ps에는 모든 문자별로 예측한 확률이 저장되어 있음. (100%기준)
- 이 중 정답(여기서는 index 2번)의 값이 높은지 비교함.
- 값이 1과 가깝다면 잘 예측한것으로 판단할 수 있음.
- 여기서는 0.07로 예측률이 너무 낮음. 전체적으로 예측률의 차이가 없다고 보
여짐.(학습이 안되어 있음)
Log(1) = 0이므로, 이 말은 해당 값이 1에 가까우면 loss도 작아진다는 뜻.
학습을 통해 계산된 확률(ps)이 정답의 index에서 1에 가깝도록 weight를
조정해야 한다
참고로 Log(x) = a : 자연상수 e를 a승 하면, x가 된다는 의미.
모든 입력문자 (여기서는 5자)별로 loss를 계산하여 합산한다.
마이너스(-)를 곱한 이유는 log의 결과가 음수로 나오므로, 이를 양수로 변환하기 위함 (loss
를 양수로 계산하기 편함)
loss를 계산하는 부분 à
cross_entropy
http://cs231n.github.io/neural-
networks-case-study/](https://image.slidesharecdn.com/codernnv1-170222044705/85/Code-RNN-8-320.jpg)




![5) Sample함수로 다음 단어 예측 - 1
Sample 함수의 파라미터
• sample_ix = sample(hprev, inputs[0], 25)
• hprev : state (100, 1) 정보 (문장의 처음에 0으로 초기화) à xavier로 초기화 하면 좋아질까?
• Input[0] : input문장(5글자)의 첫번째 문자의 index (Hello à H à 5) (char_to_ix 에 저장된 index)
• 25 : input[0]를 입력으로 25번 loop를 돌면서 25개의 output 문자를 예측한다.
• 반환값 : 예측한 문자열의 index 배열 (1, 25)
• “[2, 6, 6, 7, 0, 12, 7, 10, 6, 3, 8, 0, 1, 2, 9, 11, 0, 12, 4, 9, 6, 8, 8, 0, 1]”
• ello World. Best Wisl.. B
Input[0] = 5
n = 0
= np.tanh(np.dot(Wxh, x) + np.dot(Whh, h) + bh)
y = np.dot(Why, ) + by
p = np.exp(y) / np.sum(np.exp(y))
(14, 1)
(14, 1)
(100, 1)
ix = np.random.choice(range(vocab_size), p=p.ravel())
H
x
h
y
p
1
2
3
ix4 [[ 0.19226331]
[-3.09023869]
[ 9.50352706]
[-2.42361632]
[-3.56830588]
[-4.5526632 ]
[-0.37720546]
[-1.39742306]
[-2.69937816]
[-0.43220833]
[-1.83925515]
[-1.69037687]
[-1.92273072]
[-4.32781988]]
y
[[ 9.03763871e-05]
[ 3.39220797e-06]
[ 9.99736255e-01]
[ 6.60682628e-06]
[ 2.10310292e-06]
[ 7.85886037e-07]
[ 5.11373042e-05]
[ 1.84358410e-05]
[ 5.01453928e-06]
[ 4.84005598e-05]
[ 1.18516200e-05]
[ 1.37541809e-05]
[ 1.09024659e-05]
[ 9.84028744e-07]]
p
Input[0]인 ‘H’를 입력으로 hidden layer에서 상태값
(0)를 적용한 결과 y를 계산하고
이를 확률로 변환한 p를 추출한다.
여기서 p는 각 단어별로 정답일 확률을 의미한다.
이 예제에서는 3번째 index 2가 가장 높으므로 ‘e’를
예측하였다.
무작위로 1개의 index를 선택하는데,
p에서 비율이 높은 것에 가중치를 많이
부여해서 선택될 확률이 놀게한다.
여기서는 예상대로 2(‘e’)를 선택하였다.
2
- P를 계산하는 과정 :
- Y에서 계산된 값을 지수적으로 확장하여 비정규
화된 값으로 만든다. (np.exp(y))
- 그리고 이 값을 다시 0~1 사이의 정규화된 값으
로 변경하여 확률로 변경한다.
e
2 3
4](https://image.slidesharecdn.com/codernnv1-170222044705/85/Code-RNN-13-320.jpg)
![Input[0] = 2
n = 0
H
x
h
y
p
ix
e
n = 1
e
x
h
y
p
ix
l
n = 2
l
x
h
y
p
ix
l
n = 3
l
x
h
y
p
ix
o
n = 4
o
x
h
y
p
ix
‘ ‘
n = 5
‘ ‘
x
h
y
p
ix
W
n = 24
.
x
h
y
p
ix
‘ ‘
ello World. Best Wisrld.
‘H’ 문자를 입력으로 나머지 25개의 문자
열을 예측한 결과
5) Sample함수로 다음 단어 예측 - 2](https://image.slidesharecdn.com/codernnv1-170222044705/85/Code-RNN-14-320.jpg)































![[GomGuard] 뉴런부터 YOLO 까지 - 딥러닝 전반에 대한 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/part1mlp2cnn-slidesharev-180308015531-thumbnail.jpg?width=640&height=640&fit=bounds)