Downloaded 113 times





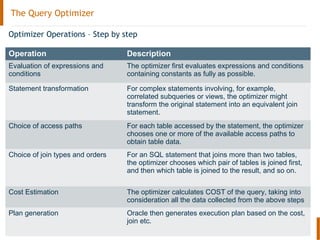
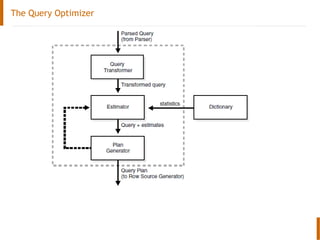









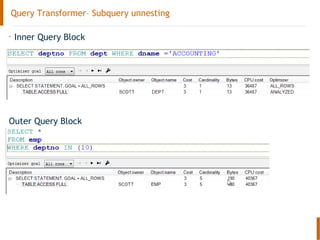
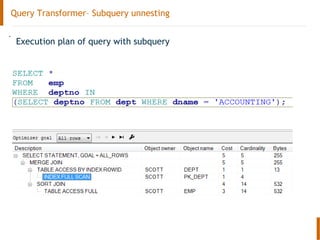
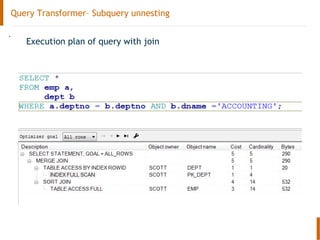










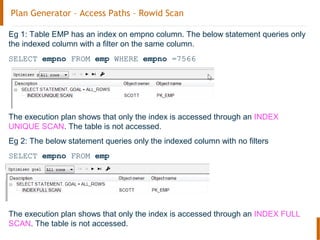
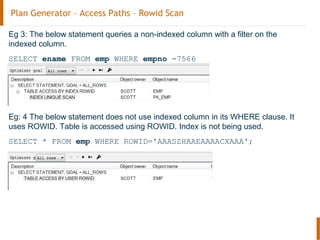


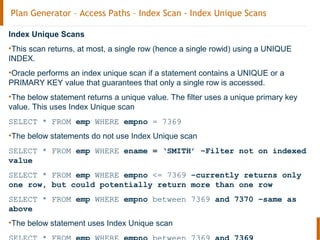



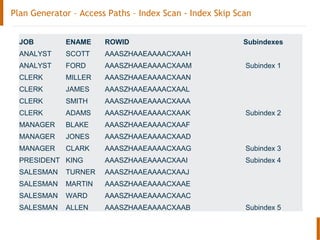
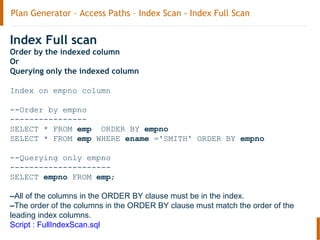
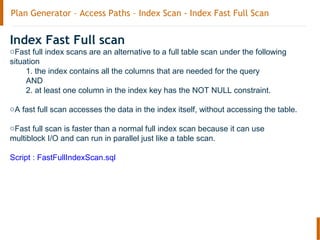



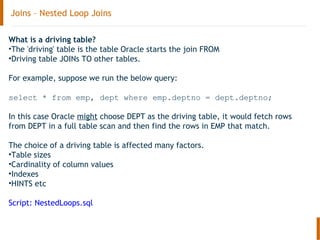
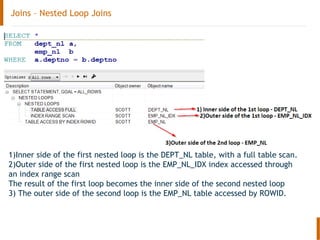




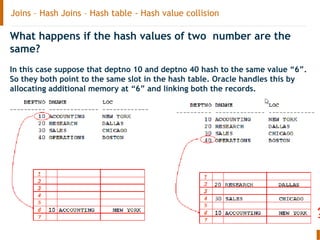
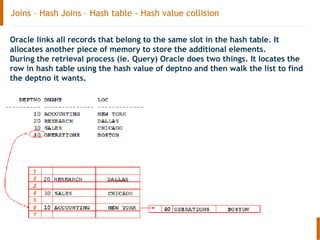
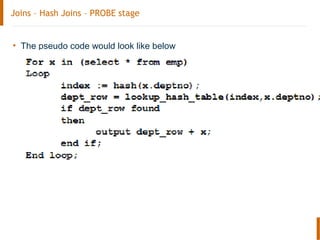

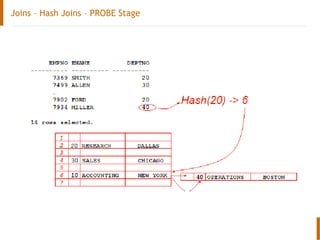




The document discusses the Oracle query optimizer. It describes the key components and steps of the optimizer including the query transformer, query estimator, and plan generator. The query transformer rewrites queries for better performance through techniques like view merging, predicate pushing, and subquery unnesting. The query estimator calculates selectivity, cardinality, and cost to determine the overall cost of execution plans. The plan generator explores access paths, join methods, and join orders to select the lowest cost plan.








































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)














