Download as PDF, PPTX






















































![56
Scio
Ecclesiastical Latin IPA: /ˈʃi.o/, [ˈʃiː.o], [ˈʃi.i̯o]
Verb: I can, know, understand, have knowledge.
Core API similar to spark-core, some ideas from scalding
github.com/spotify/scio](https://image.slidesharecdn.com/fromstreamtorecommendationusingapachebeamwithcloudpubsubandclouddataflow-160406203151/85/From-stream-to-recommendation-using-apache-beam-with-cloud-pubsub-and-cloud-dataflow-56-320.jpg)
![57
WordCount
Almost identical to Spark version
val sc = ScioContext()
sc.textFile("shakespeare.txt")
.flatMap(_.split("[^a-zA-Z']+").filter(_.nonEmpty))
.countByValue()
.saveAsTextFile("wordcount.txt")](https://image.slidesharecdn.com/fromstreamtorecommendationusingapachebeamwithcloudpubsubandclouddataflow-160406203151/85/From-stream-to-recommendation-using-apache-beam-with-cloud-pubsub-and-cloud-dataflow-57-320.jpg)
![58
PageRank in 13 lines
def pageRank(in: SCollection[(String, String)]) = {
val links = in.groupByKey()
var ranks = links.mapValues(_ => 1.0)
for (i <- 1 to 10) {
val contribs = links.join(ranks).values
.flatMap { case (urls, rank) =>
val size = urls.size
urls.map((_, rank / size))
}
ranks = contribs.sumByKey.mapValues((1 - 0.85) + 0.85 * _)
}
ranks
}](https://image.slidesharecdn.com/fromstreamtorecommendationusingapachebeamwithcloudpubsubandclouddataflow-160406203151/85/From-stream-to-recommendation-using-apache-beam-with-cloud-pubsub-and-cloud-dataflow-58-320.jpg)


![61
JSON vs Type Safe BigQuery
JSON approach, a.k.a. everything is Object
sc.bigQuerySelect("...").map { r =>
(r.get("track").asInstanceOf[TableRow]
.get("name").asInstanceOf[String],
r.get("audio").asInstanceOf[TableRow]
.get("tempo").toString.toInt
)
}
Compile
Run job
Wait
NullPointerException or ClassCastException
Repeat
Type safe approach
@BigQueryType.fromQuery("...")
class TrackTempo
sc.typedBigQuery[TrackTempo]().map { t =>
(t.track.name, t.audio.tempo.getOrElse(-1))
}
Compile
Run
Profit](https://image.slidesharecdn.com/fromstreamtorecommendationusingapachebeamwithcloudpubsubandclouddataflow-160406203151/85/From-stream-to-recommendation-using-apache-beam-with-cloud-pubsub-and-cloud-dataflow-61-320.jpg)










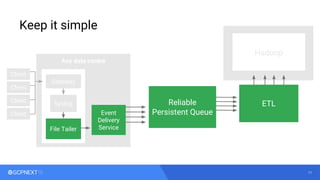
The document discusses Spotify's event delivery system utilizing Cloud Pub/Sub and Cloud Dataflow, emphasizing their architecture for managing real-time data and analytics. It outlines the advantages of using Kafka for reliable event delivery and the transition to Cloud Pub/Sub for simplified operations and scalability. Additionally, it touches on the use of Dataflow for streaming ETL jobs, the challenges of interactive processing, and the integration with BigQuery for data analysis.


































































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)
