【補足】RUNSTATSコマンド(統計情報の更新)
RUNSTATSコマンドで統計情報を更新する
多くの場合、この
基本形でOK
RUNSTATS ON TABLEスキーマ名.表名
RUNSTATS ON TABLE スキーマ名.表名 AND INDEXES ALL
(※DB2 10.1からスキーマ名が省略可能になっています)
RUNSTATS実行中でも表に読み書きアクセス可能
少し進んだ使い方
データに「偏り」がある場合、分散統計
を試してください。こちらもお勧め
①分散統計で収集する
RUNSTATS ON TABLE スキーマ名.表名 WITH DISTRIBUTION
RUNSTATS ON TABLE スキーマ名.表名 WITH DISTRIBUTION AND INDEXES ALL
②サンプリングでRUNSTATSの実行時間を短くする
RUNSTATS ON TABLE SIM.DEPARTMENTS WITH DISTRIBTION TABLESAMPLE
BERNOULLI (5)
35
表を5%サンプリングする例(大
規模環境用)
36.
【補足】分散統計とインデックス
表の分散統計 (WITH DISTRIBUTION)
表データに「偏り」があり、その表がパフォーマンス上重要な場合はRUNSTATS… WITH
DISTRIBUTIONで表データの偏り(分散状況)を含めた統計情報を取得することで、より精度
の高いアクセスプランが作成可能になります
巨大な表で分散統計を取得すると、実行時間が長くなりすぎる場合があります。その場合は
TABLESAMPLEオプションでサンプリングを設定することで時間を調整可能です
インデックスの分散統計
RUNSTATSで"… AND DETAILED INDEXES ALL"を指定することで、インデックスの分散
統計を取得できますが、インデックスの分散統計を取得することでアクセスプランが改善出来
るケースは(表の分散統計と比較すると)少ない傾向にあります
DB2 9.7までと10.1ではインデックスの分散統計の挙動が変更されています
9.7まで: デフォルトでインデックス全体の分散情報を取得。SAMPLED DETAILEDと指定すると、サン
プリングを実施
10.1から:デフォルトでは、インデックスをサンプリングして部分的な分散統計を取得。UNSAMPLED
DETAILEDと指定すると、サンプリングせずに全体の分散統計を取得
インデックスの分散統計取得の例)
RUNSTATS ON TABLE スキーマ名.表名 WITH DISTRIBUTION AND SAMPLED DETAILED
INDEXES ALL
36





![アクセスプランを人が決定するのは困難 (1/2)
最適なアクセスプランを選択するには?
平均処理時間
表スキャン
0
10
取得したいデータ量 [%] 100](https://image.slidesharecdn.com/db2-140131101603-phpapp02/85/slide-10-320.jpg)
![アクセスプランを人が決定するのは困難 (2/2)
最適なアクセスプランは常に変わる
平均処理時間
インデックス・スキャン
表スキャン
ここで、インデックス・スキャンから表ス
キャンに切り替わるのが理想
0
11
取得したいデータ量 [%] 100](https://image.slidesharecdn.com/db2-140131101603-phpapp02/85/slide-11-320.jpg)





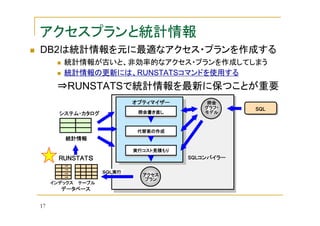




![アクセスプランの基
本的な読み方
例)SELECT * FROM MEMBER WHERE JOB IN
('MANAGER','OPERATOR','SALES')
()内はオペレーション番号
下から上へ読む
下から上へ
どのオブジェクト(表やインデッ
クス)を使っているか
表スキャンで13,312行
を戻している
演算子の種類と、戻す行数
戻す行数
演算子
コスト:304.324
演算子のコスト [timeron]
コスト
時間ではない
累積値
DB2INST1.MEMBER
表にアクセス。この表は
43,008行を保持
(※「Q3」は自動的に付けら
れた相関名)
22](https://image.slidesharecdn.com/db2-140131101603-phpapp02/85/slide-22-320.jpg)



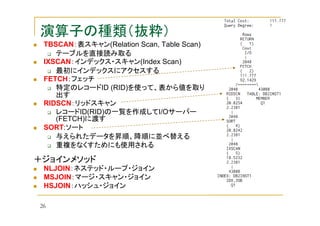

![NLJOIN:ネステッド・ループ・ジョイン
[Q] 3枚のトランプが左にあり、2枚のトランプを右手にあって、右と左で
番号が同じものを選ぶ時、どうしますか?
⇒左の3枚をそれぞれ総当たりで右と比べて、3×2 = 6回の比較
2
2
2重のFORループのようなイメージ
片方の表が小さい場合に向く
4
小さいとオンメモリで処理可能
4
A
A
少メモリ
枚数が多いと遅くなる
2
2
4
4
28](https://image.slidesharecdn.com/db2-140131101603-phpapp02/85/slide-28-320.jpg)
![MSJOIN:マージ・スキャン・ジョイン
[Q] 30枚のトランプが左に山積みで、20枚のトランプが右に山積みで、
右と左で番号が同じものを選ぶ時、どうしますか?
1. 左の30枚のトランプを、あらかじめ小さい順にソート
2. 右の20枚のトランプも、あらかじめ小さい順にソート
3. 比較して、同じか小さい値は捨てていく
3
4
比較(めくり)回数は左枚数+右枚数 = 50回
2
3
7
3
4
ソートが必要だが、枚数が多い場合にも速い
4
6
7
29](https://image.slidesharecdn.com/db2-140131101603-phpapp02/85/slide-29-320.jpg)
![HSJOIN:ハッシュ・ジョイン
[Q] 3000枚のはがき束と20枚のはがき束で郵便番号 桁が一致するも
郵便番号7桁
郵便番号
のを選ぶならどうしますか?
1.
郵便番号3桁で区分けする棚を用意する
2.
先に20枚のはがきを、全て郵便番号3桁の棚へ分ける
3.
次に3000枚のはがきの束を郵便番号3桁の棚へ振り分ける
この時、先のはがきが入っていない棚には振り分けずに捨てる
4.
それぞれの棚の中で、つき合わせをする(NLJOINなど)
ハッシュ計算が高速なら、非常に速度が出る
CPU負荷は高く、メモリ使用量も大きめ
1 2 7
1 2 7
1 1 1 1
1 2 7
1 2 7
2 1 1
1 1 1 1
1 2 7
30
3 3 3 3
1 1 1 1
127の棚
1 1 1 1
9 9 9 9
2 1 1
1 1 1 1
1 2 7
9 9 9 9
2 1 1
3 3 3 3
2 1 1
1 1 1 1
211の棚](https://image.slidesharecdn.com/db2-140131101603-phpapp02/85/slide-30-320.jpg)































































![[B15] HiRDBのSQL実行プランはどのように決定しているのか?by Masaaki Narita](https://cdn.slidesharecdn.com/ss_thumbnails/b15-140626195700-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
