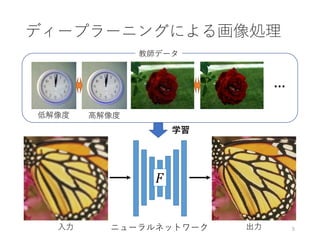
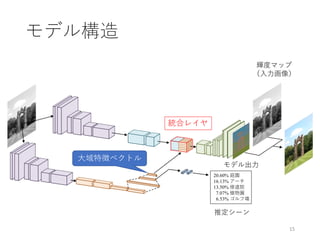
大域特徴と局所特徴による自動着色
[Iizuka and Simo-Serra+SIGGRAPH ’16]
• 大域特徴と局所特徴を同時に学習し、色付けを行う
畳み込みネットワークモデルを提案
14
入力画像
Fully CNN
(大域情報なし)
提案手法
Satoshi Iizuka*, Edgar Simo-Serra*, Hiroshi Ishikawa. "Let there be Color!: Joint End-to-end Learning of Global and Local Image
Priors for Automatic Image Colorization with Simultaneous Classification", SIGGRAPH 2016. (*equal contribution)




![画像処理で重要な技術
• Fully Convolutional Neural Network
• すべての層が畳み込み層
• 目的の画像を直接出力
• Batch Normalization
• 各層をミニバッチ毎に正規化
• 深いネットワークの学習に必須
6
Semantic Segmentation [Noh+ CVPR ’15]](https://image.slidesharecdn.com/ibis2017iizuka-171120134119/85/IBIS2017-6-320.jpg)
![なぜ画像処理にCNN?
• 複雑な画像処理には高レベル特徴が重要
• 手動設計するのが困難
• CNNは複雑な特徴を学習可能
7
1層目 2層目 3層目 4層目
コーナー、エッジ、色
(低レベル特徴)
模様
(中レベル特徴)
犬の顔、鳥の足
(高レベル特徴)
“Visualizing and UnderstandingConvolutional Networks” [Zeiler+ ECCV ’14]](https://image.slidesharecdn.com/ibis2017iizuka-171120134119/85/IBIS2017-7-320.jpg)
![CNNの特徴マップを利用した画像変換手法も
8
入力画像
スタイル画像
𝐹
学習済みCNN
(ここでは学習を行わない)
各層の特徴マップの類似度を
考慮して入力画像を更新
更新
“Image Style Transfer Using Convolutional Neural Networks” [Gatys+ CVPR ’16]
入力
入力](https://image.slidesharecdn.com/ibis2017iizuka-171120134119/85/IBIS2017-8-320.jpg)




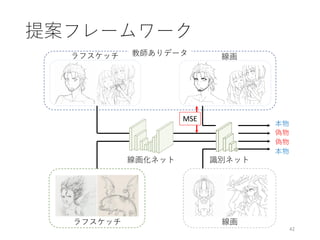
![大域特徴と局所特徴による自動着色
[Iizuka and Simo-Serra+ SIGGRAPH ’16]
• 大域特徴と局所特徴を同時に学習し、色付けを行う
畳み込みネットワークモデルを提案
14
入力画像
Fully CNN
(大域情報なし)
提案手法
Satoshi Iizuka*, Edgar Simo-Serra*, Hiroshi Ishikawa. "Let there be Color!: Joint End-to-end Learning of Global and Local Image
Priors for Automatic Image Colorization with Simultaneous Classification", SIGGRAPH 2016. (*equal contribution)](https://image.slidesharecdn.com/ibis2017iizuka-171120134119/85/IBIS2017-14-320.jpg)
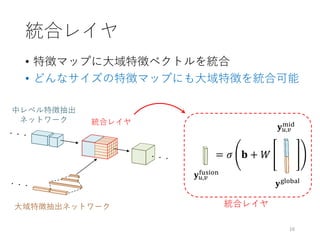

![ユーザ入力付きの着色
• ユーザが指定した色を出力に反映するように学習
• 対話的な編集が可能に
18
[Zhang+ SIGGRAPH ’17] [Sangkloy+ CVPR ’17]
グレイスケール画像
+ ユーザ入力
出力 出力スケッチ
+ ユーザ入力](https://image.slidesharecdn.com/ibis2017iizuka-171120134119/85/IBIS2017-18-320.jpg)
![ユーザ入力の学習
• 入力を「グレイスケール画像+カラー点」に
• 4チャンネル(𝐿 + 𝑎 + 𝑏 + 𝑚𝑎𝑠𝑘)
• もしくは単純にRGB
• 学習時はランダムに色をサンプリング
19
入力 出力
[Zhang+ SIGGRAPH ’17]](https://image.slidesharecdn.com/ibis2017iizuka-171120134119/85/IBIS2017-19-320.jpg)


![従来のアプローチ
• パッチベース [Criminisi+ ’04; Wexler+ ’07; Simakov+ ’08;
Barnes+ ’09; Darabi+ ’12; Huang+ ’14]
• 小さな画像パッチを合成
• 大域的な構造を考慮できない
• 新しい物体をつくれない
22
入力
パッチベースの画像補完 [Barnes+ ’09]
出力 出力入力](https://image.slidesharecdn.com/ibis2017iizuka-171120134119/85/IBIS2017-22-320.jpg)


![“Globally and Locally Consistent Image
Completion” [Iizuka+ SIGGRAPH ’17]
• 2つの補助ネットワークを用いた敵対的学習による
補完ネットワークを提案
• 大域的・局所的に自然な画像補完
• 新しい物体を生成することも可能
25
入力画像 補完結果 入力画像 補完結果
Satoshi Iizuka, Edgar Simo-Serra, Hiroshi Ishikawa. "Globally and Locally Consistent Image Completion", SIGGRAPH 2017.](https://image.slidesharecdn.com/ibis2017iizuka-171120134119/85/IBIS2017-25-320.jpg)

![• Generative Adversarial Nets (GAN) [Goodfellow+ NIPS ’15]
• データの分布を推定
• 生成器𝐺と識別器𝐷を戦わせるようにして交互に更新
• 鮮明な画像を生成可能
27
敵対的学習
ランダム
ベクトル
生成器
𝐺
識別器
𝐷
本物
or
偽物
データ](https://image.slidesharecdn.com/ibis2017iizuka-171120134119/85/IBIS2017-27-320.jpg)
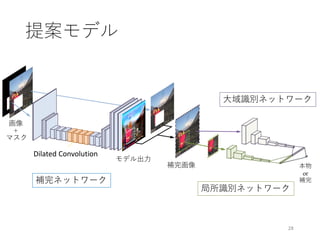
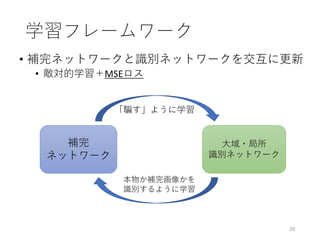




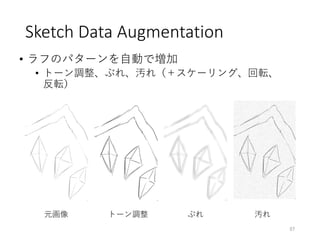
![• ラフスケッチを自動できれいな線画に
• ラフと線画の複雑な対応関係をFully CNNで学習
34
ラフスケッチの自動線画化
[Simo-Serra and Iizuka+ SIGGRAPH ’16]
・・・
ラフ 線画
対応関係の学習
Edgar Simo-Serra*, Satoshi Iizuka*, Kazuma Sasaki, Hiroshi Ishikawa. "Learning to Simplify: Fully Convolutional Networks
for Rough Sketch Cleanup", SIGGRAPH 2016. (*equal contribution)](https://image.slidesharecdn.com/ibis2017iizuka-171120134119/85/IBIS2017-34-320.jpg)
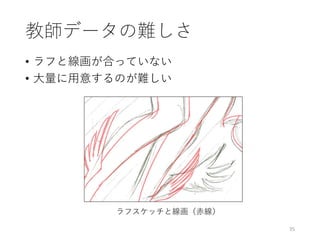
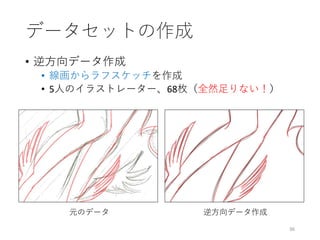

![39
結果
入力画像 Potrace Adobe Live Trace [Simo-Serra+ ‘16]](https://image.slidesharecdn.com/ibis2017iizuka-171120134119/85/IBIS2017-39-320.jpg)

![Adversarial Augmentation
[Simo-Serra and Iizuka+ TOG ’17]
• 敵対的学習を使って線画化の精度を向上
• 鮮明な線画を出力
• 教師ありデータと教師なしデータを同時に学習
41
入力画像 [Simo-Serra and Iizuka+ ’16] 提案手法
Edgar Simo-Serra*, Satoshi Iizuka*, Hiroshi Ishikawa. "Mastering Sketching: Adversarial Augmentation for Structured Prediction",
ACM Transaction on Graphics, 2017. (*equal contribution)](https://image.slidesharecdn.com/ibis2017iizuka-171120134119/85/IBIS2017-41-320.jpg)
![結果(後処理なし)
43入力画像 [Simo-Serra and Iizuka+ ’16] 提案手法](https://image.slidesharecdn.com/ibis2017iizuka-171120134119/85/IBIS2017-43-320.jpg)


![[DL輪読会]Learning to Generalize: Meta-Learning for Domain Generalization](https://cdn.slidesharecdn.com/ss_thumbnails/20180208-180209000942-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]SOM-VAE: Interpretable Discrete Representation Learning on Time Series](https://cdn.slidesharecdn.com/ss_thumbnails/190118nonakadlhacks-190118005053-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)


![[論文紹介] Convolutional Neural Network(CNN)による超解像](https://cdn.slidesharecdn.com/ss_thumbnails/cnn-presen-161218113749-thumbnail.jpg?width=640&height=640&fit=bounds)











