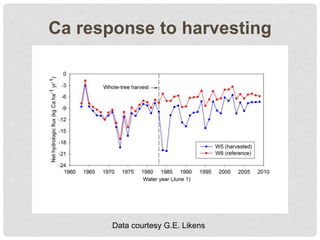
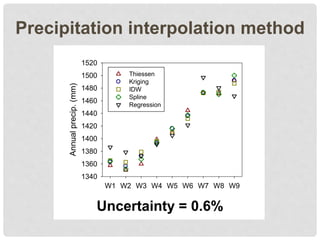
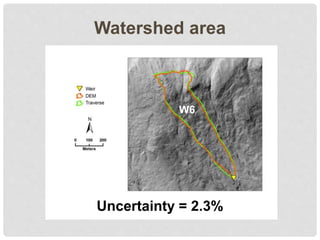
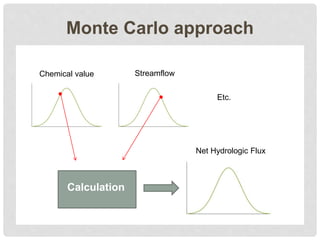
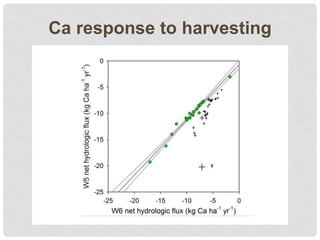
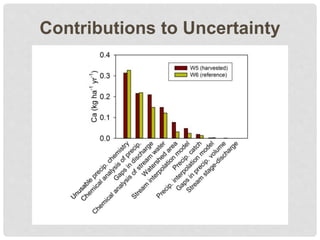
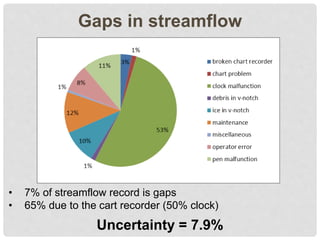
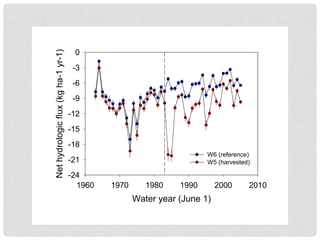
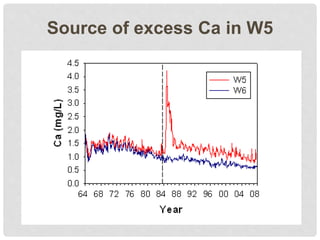
The document discusses uncertainty in the net hydrologic flux of calcium in a paired-watershed harvesting study conducted in Estes Park, Colorado. It highlights challenges in finding suitable replicates for watersheds and details various sources of uncertainty related to precipitation, streamflow, and chemical analysis. The study emphasizes the complexity of quantifying uncertainty in hydrologic data and its implications for understanding calcium flux in harvested versus reference watersheds.