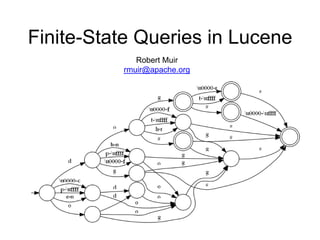
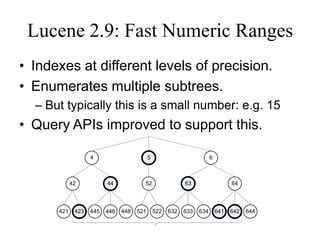
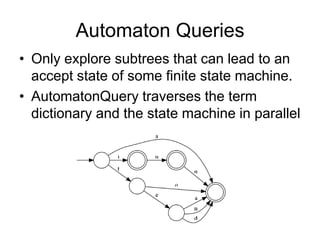
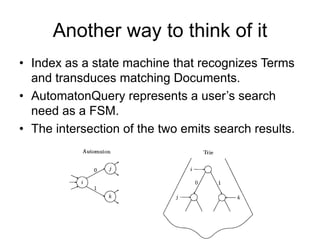
The document discusses advancements in Lucene, an open-source search engine library, focusing on improving inexact matching through automaton queries and enhancements in query APIs. It highlights the benefits of expanding queries for better language support, stemming, and spellchecking, while also noting ongoing developments in Lucene-Solr merging and indexing improvements. Additionally, it addresses enhancements in text analysis, relevance benchmarking, and spatial support.
































![[Pgday.Seoul 2017] 6. GIN vs GiST 인덱스 이야기 - 박진우](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-171106044702-thumbnail.jpg?width=640&height=640&fit=bounds)






















































