Download as PDF, PPTX
































![Dropout12
•
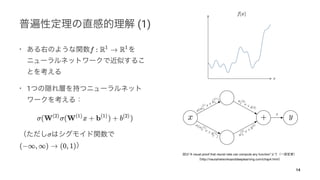
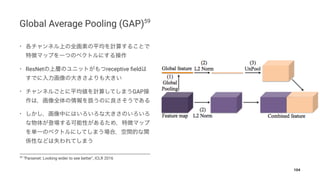
[13] Figure 1 13
13
N. Srivastava, G. E. Hinton, A. Krizhevsky, I. Sutskever, and R.
Salakhutdinov, "Dropout: A Simple Way to Prevent Neural Networks from
Overfitting", Journal of Machine Learning Research (2014)
12
G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R.
Salakhutdinov, "Improving neural networks by preventing co-adaptation
of feature detectors", On arxiv (2012)
36](https://image.slidesharecdn.com/presentationslideshare-170919153832/85/Deep-Learning-Chainer-36-320.jpg)
![[14]
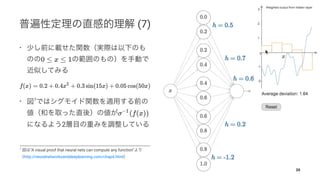
Residual learning 14
•
•
14
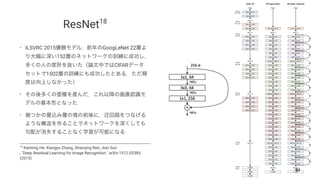
K. He, X. Zhang, S. Ren, and J. Sun, "Deep Residual Learning for Image
Recognition", CVPR (2016)
37](https://image.slidesharecdn.com/presentationslideshare-170919153832/85/Deep-Learning-Chainer-37-320.jpg)




















![• MNIST scikit-learn
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original', data_home='./')
x, t = mnist['data'] / 255, mnist['target']
t = numpy.array([t == i for i in range(10)]).T
train_x, train_t = x[:60000], t[:60000]
val_x, val_t = x[60000:], t[60000:]
• 1
• 150
58](https://image.slidesharecdn.com/presentationslideshare-170919153832/85/Deep-Learning-Chainer-58-320.jpg)














![•
• convolutional layer
• pooling
[A. Krizhevsky, 2016]15
**
15
A. Krizhevsky, I. Sutskever, G. E. Hinton, "ImageNet Classification with
Deep Convolutional Neural Networks", NIPS (2012)
73](https://image.slidesharecdn.com/presentationslideshare-170919153832/85/Deep-Learning-Chainer-73-320.jpg)









































![[37] D. Xu, Y. Zhu, C. B. Choy, L. Fei-Fei, “Scene Graph
Generation by Iterative Message Passing”, CVPR (2017)
•
Faster R-CNN Region
Proposal network (RPN)
• RPN
…
•
118](https://image.slidesharecdn.com/presentationslideshare-170919153832/85/Deep-Learning-Chainer-118-320.jpg)
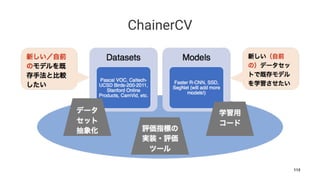
![ChainerCV
• Chainer
• public
•
from chainercv.datasets import VOCDetectionDataset
dataset = VOCDetectionDatset(split='trainval', year='2007')
# "trainval" 34
img, bbox, label = dataset[34]
119](https://image.slidesharecdn.com/presentationslideshare-170919153832/85/Deep-Learning-Chainer-119-320.jpg)

![ChainerCV transforms
TransformDataset Chainer
from chainercv import transforms
def transform(in_data):
img, bbox, label = in_data
img, param = transforms.random_flip(img, x_flip=True, return_param=True)
bbox = transforms.flip_bbox(bbox, x_flip=param['x_flip'])
return img, bbox, label
dataset = TransformDataset(dataset, transform)
bounding box
121](https://image.slidesharecdn.com/presentationslideshare-170919153832/85/Deep-Learning-Chainer-121-320.jpg)

![ChainerCV
mean Intersection over Union (mIoU) mean
Average Precision (mAP)
Chainer Trainer Extension
# mAP Trainer Extension
evaluator = chainercv.extension.DetectionVOCEvaluator(iterator, model)
#
# e.g., result['main/map']
result = evaluator()
123](https://image.slidesharecdn.com/presentationslideshare-170919153832/85/Deep-Learning-Chainer-123-320.jpg)




























































The document covers various aspects of deep learning, particularly focusing on the Chainer framework and its applications, such as Convolutional Neural Networks (CNN) and Generative Adversarial Networks (GAN). It outlines concepts like activation functions, optimization algorithms, and architectures like AlexNet and ResNet, along with their contributions to advancements in image recognition. Additionally, it touches on techniques for semantic segmentation and highlights various datasets and challenges in the field.



![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[Dl輪読会]dl hacks輪読](https://cdn.slidesharecdn.com/ss_thumbnails/dldlhacks-161125051944-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DLHacks 実装]Network Dissection: Quantifying Interpretability of Deep Visual R...](https://cdn.slidesharecdn.com/ss_thumbnails/171030netdissectimple1-171030120240-thumbnail.jpg?width=640&height=640&fit=bounds)


![[unofficial] Pyramid Scene Parsing Network (CVPR 2017)](https://cdn.slidesharecdn.com/ss_thumbnails/pyramidsceneparsingnetwork-170815035025-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Adversarial Feature Matching for Text Generation](https://cdn.slidesharecdn.com/ss_thumbnails/dljp170707-170707035929-thumbnail.jpg?width=640&height=640&fit=bounds)









![第35回 強化学習勉強会・論文紹介 [Lantao Yu : 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/seqgan-161005155821-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[5 minutes LT] Brief Introduction to Recent Image Recognition Methods and Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/fashion-tech-2017-06-06-170626055616-thumbnail.jpg?width=640&height=640&fit=bounds)













![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)









