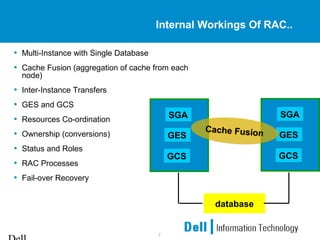
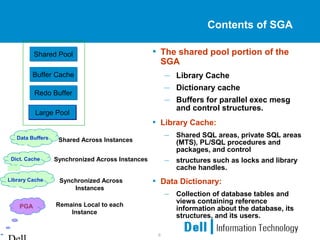
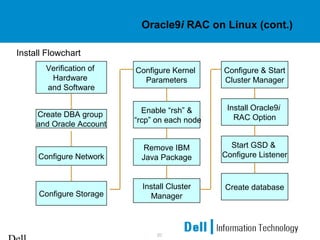
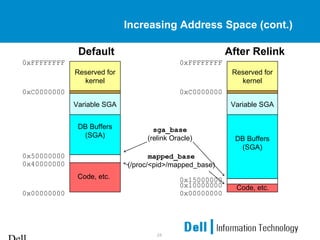
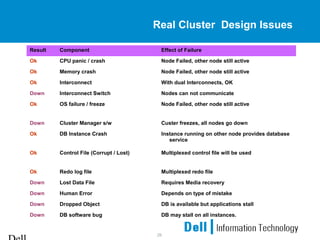
This document provides an overview of Oracle 9i Real Application Clusters (RAC) on Linux. It discusses the benefits of RAC such as scalability, high availability, and transparent expansion. Key components of RAC are described including cache fusion, global cache management, and resource coordination. Failure detection and recovery processes are also summarized. The document concludes with information on configuring Oracle 9i RAC and Linux kernel parameters on Linux systems.








































![[Hanoi-August 13] Tech Talk on Caching Solutions](https://cdn.slidesharecdn.com/ss_thumbnails/nitecocachingsolution-130826204343-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
































