Download as PDF, PPTX




















![Download
&
Unpack
!
[root@Sky6
[root@Sky6
[root@Sky6
[root@Sky6
[root@Sky6
[root@Sky6
…!
[root@Sky6
…!
drwxr-xr-x
…!
[root@Sky6
total 48!
drwxr-xr-x
-rw-r--r-drwxr-xr-x
drwxr-xr-x
-rw-r--r-drwxr-xr-x
-rw-r--r--rw-r--r--
~]# cd!
~]# curl ftp://ftp.skysql.com/downloads/Dev/maxscale.preview.0.4.tar.gz > maxscale.preview.0.4.tar.gz!
~]# cd /usr/local!
local]# mkdir skysql!
local]# cd skysql!
skysql]# tar xzvf ~/maxscale.preview.0.4.tar.gz!
skysql]# ls -l!
6 10045 2000 4096 Dec 16 18:14 maxscale!
skysql]# ls -l maxscale!
2
1
2
2
1
6
1
1
10045
10045
10045
10045
10045
10045
10045
10045
2000 4096 Dec 16 15:18
2000
754 Dec 16 17:56
2000 4096 Dec 16 16:43
2000 4096 Dec 16 16:24
2000 18011 Dec 16 17:56
2000 4096 Dec 16 16:38
2000
30 Dec 16 16:26
2000 1542 Dec 16 18:13
bin!
COPYRIGHT!
Documentation!
lib!
LICENSE!
MaxScale!
my.cnf!
SETUP
Check
MaxScale
Configuraeon
And
Usage
Scenarios.pdf
23](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-23-320.jpg)
![Start
MaxScale
!
[root@Sky6 ~]# /usr/local/skysql/maxscale/bin/maxscale -h!
!
SkySQL MaxScale! Tue Dec 31 17:34:59 2013!
------------------------------------------------------!
*!
* Usage : maxscale [-h] | [-d] [-c <home directory>] [-f <config file name>]!
* where:!
* -h help!
* -d enable running in terminal process (default:disabled)!
* -c relative|absolute MaxScale home directory!
* -f relative|absolute pathname of MaxScale configuration file (default:MAXSCALE_HOME/etc/MaxScale.cnf)!
*
24](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-24-320.jpg)
![Set
the
Environment
Variables
and
Start
MaxScale
!
[root@Sky6 ~]# MAXSCALE_HOME=/usr/local/skysql/maxscale/MaxScale!
[root@Sky6 ~]# LD_LIBRARY_PATH=/usr/local/skysql/maxscale/lib!
[root@Sky6 ~]# /usr/local/skysql/maxscale/bin/maxscale!
!
!
SkySQL MaxScale! Tue Dec 31 14:59:16 2013!
------------------------------------------------------!
Info : MaxScale will be run in a daemon process.!
! See the log from the following log files :!
!
Error log
Message log
Trace log
Debug log
:!
:!
:!
:!
/usr/local/skysql/maxscale/MaxScale/log/skygw_err1.log!
/usr/local/skysql/maxscale/MaxScale/log/skygw_msg1.log!
/usr/local/skysql/maxscale/MaxScale/log/skygw_trace1.log!
/usr/local/skysql/maxscale/MaxScale/log/skygw_debug1.log!
!
Listening MySQL connections at 0.0.0.0:4004!
Listening http connections at 0.0.0.0:6444!
Listening telnet connections at 0.0.0.0:4444
…or
create
a
3
lines
script
25](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-25-320.jpg)
![Checking
MaxScale
!
[root@Sky6 ~]# telnet localhost 4444!
Trying ::1...!
telnet: connect to address ::1: Connection refused!
Trying 127.0.0.1...!
Connected to localhost.!
Escape character is '^]'.!
Welcome the SkySQL MaxScale Debug Interface (V1.0.1).!
Type help for a list of available commands.!
!
MaxScale login: admin!
Password:!
!
MaxScale>
UID/PWD:
admin
/
skysql
!
MaxScale> help!
Available commands:!
add user!
clear server!
remove user!
restart monitor!
restart service!
set server!
show dcbs!
show dcb!
show dbusers!
show epoll!
show modules!
show monitors!
show server!
show servers!
show services!
show session!
show sessions!
show users!
shutdown maxscale!
shutdown monitor!
shutdown service!
reload config!
reload dbusers!
enable log!
disable log
26](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-26-320.jpg)

![Configuration
Template
!
[root@Sky6 etc]# cat MaxScale_template.cnf!
#!
# Example MaxScale.cnf configuration file!
#!
# Number of server threads!
# Valid options are:!
# ! hreads=<number of threads>!
t
!
[maxscale]!
threads=1!
…!
!
[Monitor Module]!
…!
!
[R/W Split Module]!
…!
!
[Read Connection Router]!
…!
!
[HTTPD Router]!
…!
!
[Debug Interface]!
…
!
# Listener definitions for the services!
#!
# Valid options are:!
#!
# ! ervice=<name of service defined elsewhere>!
s
# ! rotocol=<name of protocol module with which to listen>!
p
# ! ort=<Listening port>!
p
!
[RW Split Listener]!
…!
!
[Read Connection Listener]!
…!
!
[Debug Listener]!
…!
!
[HTTPD Listener]!
…!
!
# Definition of the servers!
!
[server1]!
…!
!
[serverN]!
…
28](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-28-320.jpg)
![Database
Settings
•Create
a
valid
MaxScale
user
•Allow
access
from
the
MaxScale
node
!
MariaDB [test]> create user maxuser identified by 'maxpwd';!
Query OK, 0 rows affected (0.01 sec)!
!
MariaDB [test]> grant all on *.* to maxuser@‘192.168.0.26’;!
Query OK, 0 rows affected (0.00 sec)
29](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-29-320.jpg)
![Global
Settings
!
•Settings
used
to
configure
the
core
of
MaxScale
[maxscale]!
threads=1!
•Options:
•threads
-‐
number
of
user
threads
that
poll
for
network
traffic
• Start
with
the
smallest
number
and
try
to
increase
to
check
the
impact
on
high
workload
• This
parameter
does
not
include
the
number
of
“internal
threads”
30](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-30-320.jpg)
![Server
Settings
•Settings
used
to
configure
the
backend
•type
-‐
the
server
type
•Options:
•address
-‐
The
IP
address
used
by
MaxScale
to
connect
to
the
server
•port
-‐
The
TCP
port
used
by
MaxScale
to
connect
to
the
server
•Protocol
-‐
The
DB
protocol.
• MySQLBackend
is
the
native
MySQL
protocol
•MonitorUser
-‐
The
DB
user
used
by
MaxScale
to
connect
with
the
Monitoring
module
• When
MonitorUser
is
not
present,
MaxScale
uses
the
credentials
set
in
the
Monitor
section
•MonitorPW
-‐
The
DB
user
password
!
[max1]!
type=server!
address=192.168.0.21!
port=3006!
protocol=MySQLBackend!
!
[max2]!
type=server!
address=192.168.0.22!
port=3006!
protocol=MySQLBackend!
!
…!
!
[max5]!
type=server!
address=192.168.0.25!
port=3006!
protocol=MySQLBackend
31](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-31-320.jpg)
![Monitor
Settings
•Settings
used
to
configure
the
monitor
module
for
MySQL/MariaDB
•type
-‐
the
monitor
type
•Options:
•module
-‐
The
loadable
module,
mysqlmon
for
MySQL/
MariaDB
•servers
-‐
Comma
separated
list
of
the
servers
to
monitor
• Servers
must
be
of
the
same
type
(e.g.
MySQL/MariaDB
servers)
•user
-‐
DB
user
used
to
connect
to
the
server
• Used
when
the
credentials
are
not
available
in
the
server
section
•passwd
-‐
DB
user
password
!
[MariaDB10 Monitor]!
type=monitor!
module=mysqlmon!
servers=max1,!
max2,!
max3,!
max4,!
max5!
user=maxuser!
passwd=maxpwd
32](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-32-320.jpg)
![SLB
with
Read/Write
Split
Service
Settings
•Settings
used
to
configure
the
service
module
for
statement-‐based
load
balancing
(with
read/write
splitting)
•type
-‐
the
service
type
•Options:
•router
-‐
The
loadable
module,
readwritesplit
for
MySQL/
MariaDB
R/W
splitting
with
MySQL
Replication
•servers
-‐
Comma
separated
list
of
the
servers
to
monitor
•user
-‐
DB
user
used
to
connect
to
the
server
to
extract
the
list
of
the
database
users
to
allow
local
authentication
•passwd
-‐
DB
user
password
!
[RW Split Router]!
type=service!
router=readwritesplit!
servers=max1,!
max2,!
max3,!
max4,!
max5 !
user=maxuser!
passwd=maxpwd
33](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-33-320.jpg)
![CLB
Service
Settings
•Settings
used
to
configure
the
service
module
for
statement-‐
based
load
balancing
(with
read/write
splitting)
•type
-‐
the
service
type
•Options:
•router
-‐
The
loadable
module,
readconnroute
for
connection
load
balancing
with
MySQL
Replication
•router_options
-‐
options
passed
to
the
module.
• slave
means
that
the
load
balancing
is
applied
only
to
the
slave
servers
• master,slave
means
that
the
load
balancing
is
applied
master
and
slave
servers
•servers
-‐
Comma
separated
list
of
the
servers
to
monitor
•user
-‐
DB
user
used
to
connect
to
the
server
to
extract
the
list
of
the
database
users
to
allow
local
authentication
•passwd
-‐
DB
user
password
!
[Read Connection Router]!
type=service!
router=readconnroute!
router_options=slave!
servers=max1,!
max2,!
max3,!
max4,!
max5!
user=maxuser!
passwd=maxpwd
34](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-34-320.jpg)
![Listener
Settings
-‐
SLB
!
•Set
the
Protocol
and
Service
pair.
This
is
used
to
offer
the
SLB
with
Read/Write
Splitting
•type
-‐
the
listener
type
[RW Split Listener]!
type=listener!
service=RW Split Router!
protocol=MySQLClient!
port=4006!
•Options:
•service
-‐
The
service
associated
to
the
listener
(e.g.
RW
Split
Router)
•protocol
-‐
The
protocol
paired
to
the
service
(e.g.
MySQLClient)
•port
-‐
The
TCP
port
used
to
listen
to
the
client
requests
35](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-35-320.jpg)
![Listener
Settings
-‐
Debug
&
HTTP
!
•These
listeners
are
used
to
offer
a
debug
and
a
HTTP
interface
to
MaxScale
•type
-‐
the
listener
type
•Options:
•service
-‐
DBAs
can
connect
to
MaxScale
using
telnet
or
via
a
restful
API
•protocol
-‐
The
protocol
paired
to
the
service
(e.g.
telnetd
and
httpd
)
•port
-‐
The
TCP
port
used
to
listen
to
the
client
requests
[Debug Listener]!
type=listener!
service=Debug Interface!
protocol=telnetd!
port=4444!
!
[HTTPD Listener]!
type=listener!
service=HTTPD Router!
protocol=HTTPD!
port=6444
36](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-36-320.jpg)
![Final
Configuration
!
[root@Sky6 etc]# cat MaxScale.cnf!
#!
# Number of server threads!
# Valid options are:!
# !
threads=<number of threads>!
[maxscale]!
threads=1!
!
#!
# Define a monitor that can be used to determine the state!
# and role of the servers.!
#!
# Valid options are:!
#!
# !
module=<name of module to load>!
# !
servers=<server name>,<server name>,...!
# !
user =<user name - must have slave replication and!
#
slave client privileges>!
# !
passwd=<password of the above user,
#
plain text currently>!
[MariaDB10 Monitor]!
type=monitor!
module=mysqlmon!
servers=max1,max2,max3,max4,max5!
user=maxuser!
passwd=maxpwd
!
#!
# A series of service definition!
#!
# Valid options are:!
#!
# !
router=<name of router module>!
# !
servers=<server name>,<server name>,...!
# !
user=<User to fetch password inforamtion with>!
# !
passwd=<Password of the user, plain text currently>!
#!
# Valid router modules currently are:!
# !
readwritesplit, readconnroute and debugcli!
[RW Split Router]!
type=service!
router=readwritesplit!
servers=max1,max2,max3,max4,max5!
user=maxuser!
passwd=maxpwd!
!
[HTTPD Router]!
type=service!
router=testroute!
servers=max1,max2,max3,max4,max5!
!
[Debug Interface]!
type=service!
router=debugcli
37](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-37-320.jpg)
![Final
Configuration
!
#!
# Listener definitions for the services!
#!
# Valid options are:!
#!
# !
service=<name of service defined elsewhere>!
# !
protocol=<name of protocol module with which to listen>!
# !
port=<Listening port>!
[RW Split Listener]!
type=listener!
service=RW Split Router!
protocol=MySQLClient!
port=4004!
!
[Debug Listener]!
type=listener!
service=Debug Interface!
protocol=telnetd!
port=4444!
!
[HTTPD Listener]!
type=listener!
service=HTTPD Router!
protocol=HTTPD!
port=6444!
!
# Servers Definition!
[max1]!
type=server!
address=192.168.0.21!
port=3306!
protocol=MySQLBackend!
!
[max2]!
type=server!
address=192.168.0.22!
port=3306!
protocol=MySQLBackend!
!
[max3]!
type=server!
address=192.168.0.23!
port=3306!
protocol=MySQLBackend!
!
[max4]!
type=server!
address=192.168.0.24!
port=3306!
protocol=MySQLBackend!
!
[max5]!
type=server!
address=192.168.0.25!
port=3306!
protocol=MySQLBackend
38](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-38-320.jpg)
![Password
Encryption
•Used
to
remove
plain
password
from
the
config
file
•Passwords
are
stored
in
a
readonly
file
(default
$MAXSCALE_HOME/etc/.secrets)
•Plain
passwords
in
the
config
file
can
be
replaced
with
the
encrypted
password
!
[root@Sky6 ~]# /usr/local/skysql/maxscale/bin/
maxkeys /usr/local/skysql/maxscale/MaxScale/
etc/.secrets!
!
[root@Sky6 ~]# MAXSCALE_HOME=/usr/local/skysql/
maxscale/MaxScale!
[root@Sky6 ~]# /usr/local/skysql/maxscale/bin/
maxpasswd maxpwd!
14AE17C29AE7E6DB94EA5E6068D9833D!
!
[root@Sky6 ~]# vi /usr/local/skysql/maxscale/
MaxScale/etc/MaxScale.cnf!
!
…!
[MariaDB10 Monitor]!
type=monitor!
module=mysqlmon!
servers=max1,max2,max3,max4,max5!
user=maxuser!
passwd=14AE17C29AE7E6DB94EA5E6068D9833D!
…
39](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-39-320.jpg)
![Troubleshooting
!
2013 12/31 17:47:24 Error : access for secrets file [/usr/local/skysql/maxscale/MaxScale/etc/.secrets]
failed. Error 2, No such file or directory.
MaxScale
cannot
fine
the
encrypted
password
file
!
[root@Sky6 bin]# /usr/local/skysql/maxscale/MaxScale/bin/maxkeys /usr/local/skysql/maxscale/MaxScale/
etc/.secrets!
41](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-41-320.jpg)
![Troubleshooting
!
[root@Sky0 ~]# mysql -uroot -h 192.168.0.26 -P4004 -p!
Enter password:!
ERROR 1045 (2800): Authorization failed!
[root@Sky0 ~]#
root
is
not
loaded
to
the
available
users
to
connect
via
MaxScale
!
<<<< User [root] was not found!
<<< CLIENT AUTH FAILED for user [root]!
!
[root@Sky0 ~]# mysql -umaxuser -h 192.168.0.26 -P4004 -pmaxpwd!
Welcome to the MariaDB monitor. Commands end with ; or g.!
Your MySQL connection id is 1535!
Server version: 5.5.22-SKYSQL-0.1.0 MariaDB Server!
!
Copyright (c) 2000, 2013, Oracle, Monty Program Ab and others.!
!
Careful
with
this!
Type 'help;' or 'h' for help. Type 'c' to clear the current
input statement.!
!
MySQL [(none)]>
42](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-42-320.jpg)
![Troubleshooting
From
MaxScale
You
see
the
Max1
process
list
!
MySQL [(none)]> show processlist;!
+-----+---------+-------------------+------+-------------+-------+----------------------------------------+------------------+----------+!
| Id | User
| Host
| db
| Command
| Time | State
| Info
| Progress |!
+-----+---------+-------------------+------+-------------+-------+----------------------------------------+------------------+----------+!
|
5 | root
| skycluster3:33830 | NULL | Binlog Dump | 82453 | Master has sent all binlog to slave; … | NULL
|
0.000 |!
|
6 | root
| skycluster4:43403 | NULL | Binlog Dump | 82389 | Master has sent all binlog to slave; … | NULL
|
0.000 |!
|
7 | root
| skycluster5:46878 | NULL | Binlog Dump | 82382 | Master has sent all binlog to slave; … | NULL
|
0.000 |!
|
8 | root
| skycluster2:54912 | NULL | Binlog Dump | 82376 | Master has sent all binlog to slave; … | NULL
|
0.000 |!
| 100 | root
| skycluster0:41977 | NULL | Sleep
|
0 |
| NULL
|
0.000 |!
| 101 | root
| skycluster0:41997 | NULL | Sleep
|
60 |
| NULL
|
0.000 |!
| 129 | maxuser | skycluster6:55557 | NULL | Sleep
|
5 |
| NULL
|
0.000 |!
| 132 | maxuser | skycluster6:55565 | NULL | Query
|
0 | init
| show processlist |
0.000 |!
| 135 | maxuser | skycluster6:55571 | NULL | Sleep
|
41 |
| NULL
|
0.000 |!
+-----+---------+-------------------+------+-------------+-------+----------------------------------------+------------------+----------+!
9 rows in set (0.00 sec)
This
is
directly
from
Max2
!
MariaDB [(none)]> show processlist;!
+----+-------------+-------------------+------+---------+-------+----------------------------------+------------------+----------+!
| Id | User
| Host
| db
| Command | Time | State
| Info
| Progress |!
+----+-------------+-------------------+------+---------+-------+----------------------------------+------------------+----------+!
| 4 | system user |
| NULL | Connect | 82804 | Waiting for master to send event | NULL
|
0.000 |!
| 5 | system user |
| NULL | Connect | 73387 | Slave has read all relay log; wa…| NULL
|
0.000 |!
| 14 | root
| skycluster0:35933 | NULL | Sleep
|
0 |
| NULL
|
0.000 |!
| 15 | root
| skycluster0:35936 | NULL | Sleep
|
216 |
| NULL
|
0.000 |!
| 44 | maxuser
| skycluster6:46518 | NULL | Sleep
|
3 |
| NULL
|
0.000 |!
| 46 | root
| localhost
| NULL | Query
|
0 | init
| show processlist |
0.000 |!
+----+-------------+-------------------+------+---------+-------+----------------------------------+------------------+----------+!
6 rows in set (0.00 sec)
43](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-43-320.jpg)
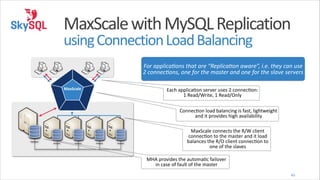
![MaxScale
with
MySQL
Replication
using
Connection
Load
Balancing
[Write Listener]
type=listener
service=Write Service
protocol=MySQLClient
port=4007
[Read Listener]
type=listener
service=Read Service
protocol=MySQLClient
port=4006
MaxScale
[Write Service]
type=service
router=readconnroute
router_options=master
servers=s1,s2,s3,s4,s5
user=maxuser
auth=maxpwd
[Read Service]
type=service
router=readconnroute
router_options=slave
servers=s1,s2,s3,s4,s5
user=maxuser
auth=maxpwd
Database
Database
Database
Database
Database
46](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-46-320.jpg)
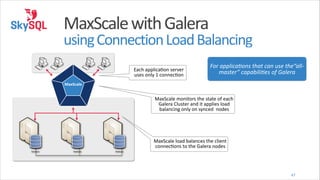
![MaxScale
with
Galera
using
Connection
Load
Balancing
[Read Listener]
type=listener
service=Read Service
protocol=MySQLClient
port=4006
MaxScale
[Galera Service]
type=service
router=readconnroute
router_options=synced
servers=s1,s2,s3,s4,s5
user=maxuser
auth=maxpwd
Database
Database
Database
48](https://image.slidesharecdn.com/140116-maxscaleformadridmeetup-140130015936-phpapp02/85/140116-max-scale-for_madrid_meetup-48-320.jpg)






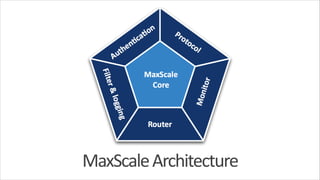
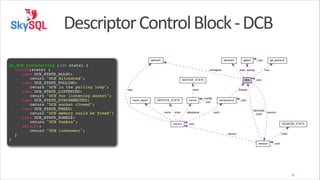
The document outlines MaxScale's architecture, focusing on its scalable, lightweight event-driven design that handles network I/O processing and utilizes descriptor control blocks (DCBs) for event management. It details various modules and their functionalities, such as monitoring, routing, and connection management, alongside installation instructions and command usage examples. Overall, it serves as a comprehensive guide for understanding and implementing MaxScale for MySQL database management.

























































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)









