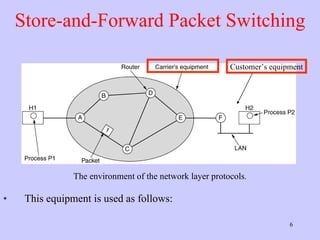
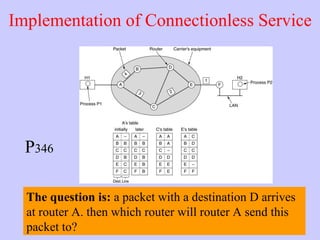
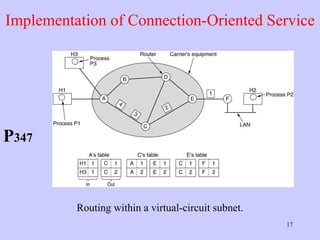
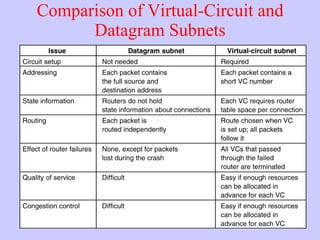
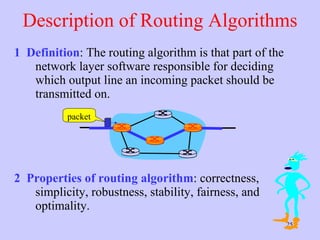
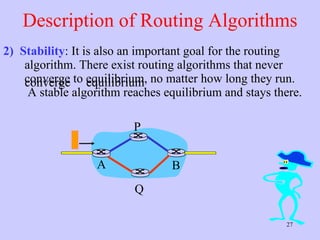
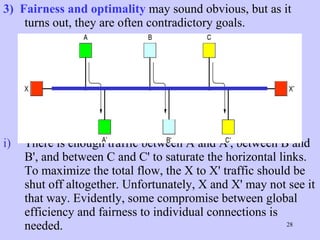
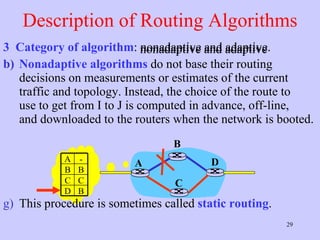
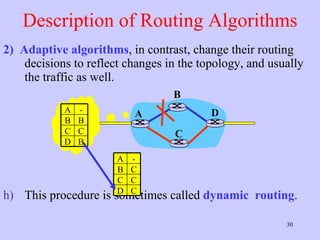
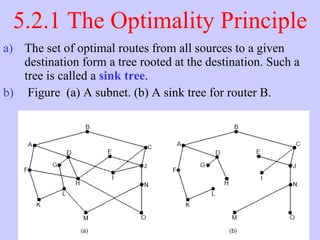
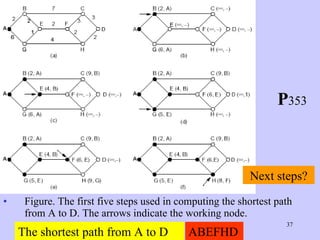
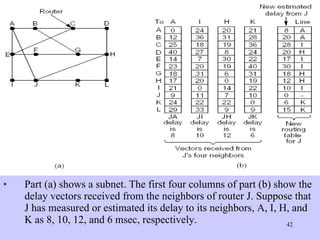
The document discusses the network layer in computer networking. It describes how the network layer is responsible for routing packets from their source to destination. It covers different routing algorithms like distance vector routing and link state routing. It also compares connectionless and connection-oriented services, as well as datagram and virtual circuit subnets. Key aspects of routing algorithms like optimality, stability, and fairness are defined.

































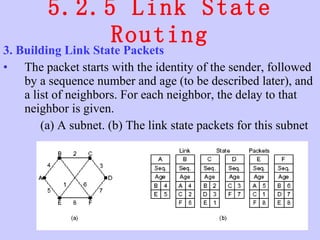




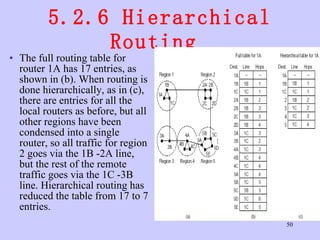





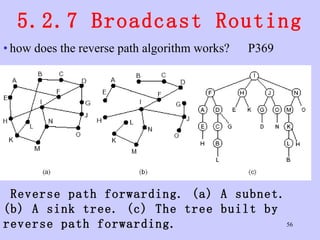


























































![Unit-3-Part-1 [Autosaved].ppt](https://cdn.slidesharecdn.com/ss_thumbnails/unit-3-part-1autosaved-230216062941-16596250-thumbnail.jpg?width=640&height=640&fit=bounds)































