Download to read offline




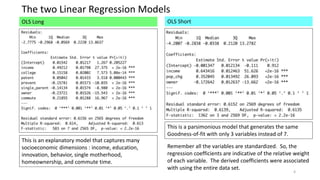
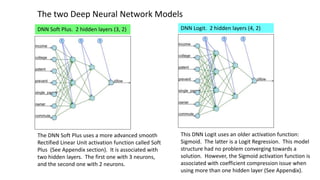


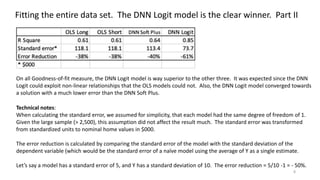
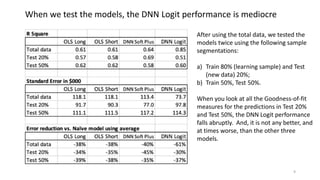


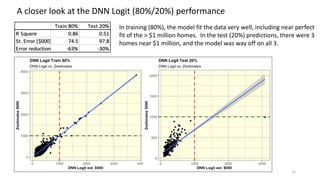
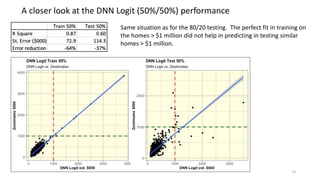
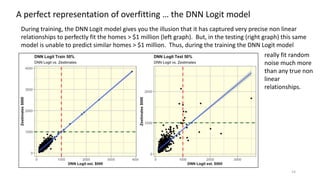
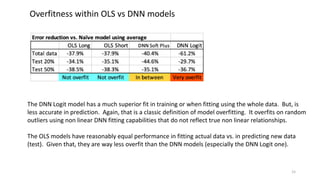
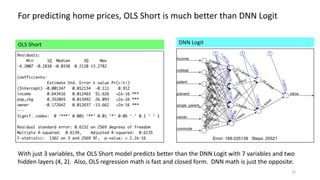
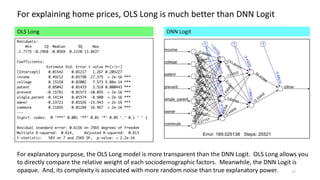



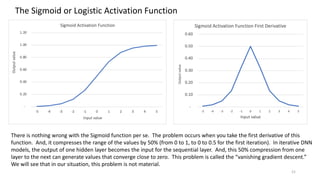
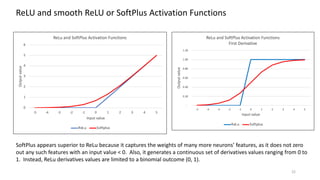

The document discusses the modeling of county-level housing prices using various demographic variables and compares four different models, including linear regression and deep neural networks (DNNs). It concludes that while the DNN logit model initially appears superior in training, it suffers from overfitting and performs poorly in prediction compared to simpler OLS models. Ultimately, OLS models are deemed more reliable for predicting and explaining home prices due to their transparency and reduced overfitting issues.



































































