Download to read offline




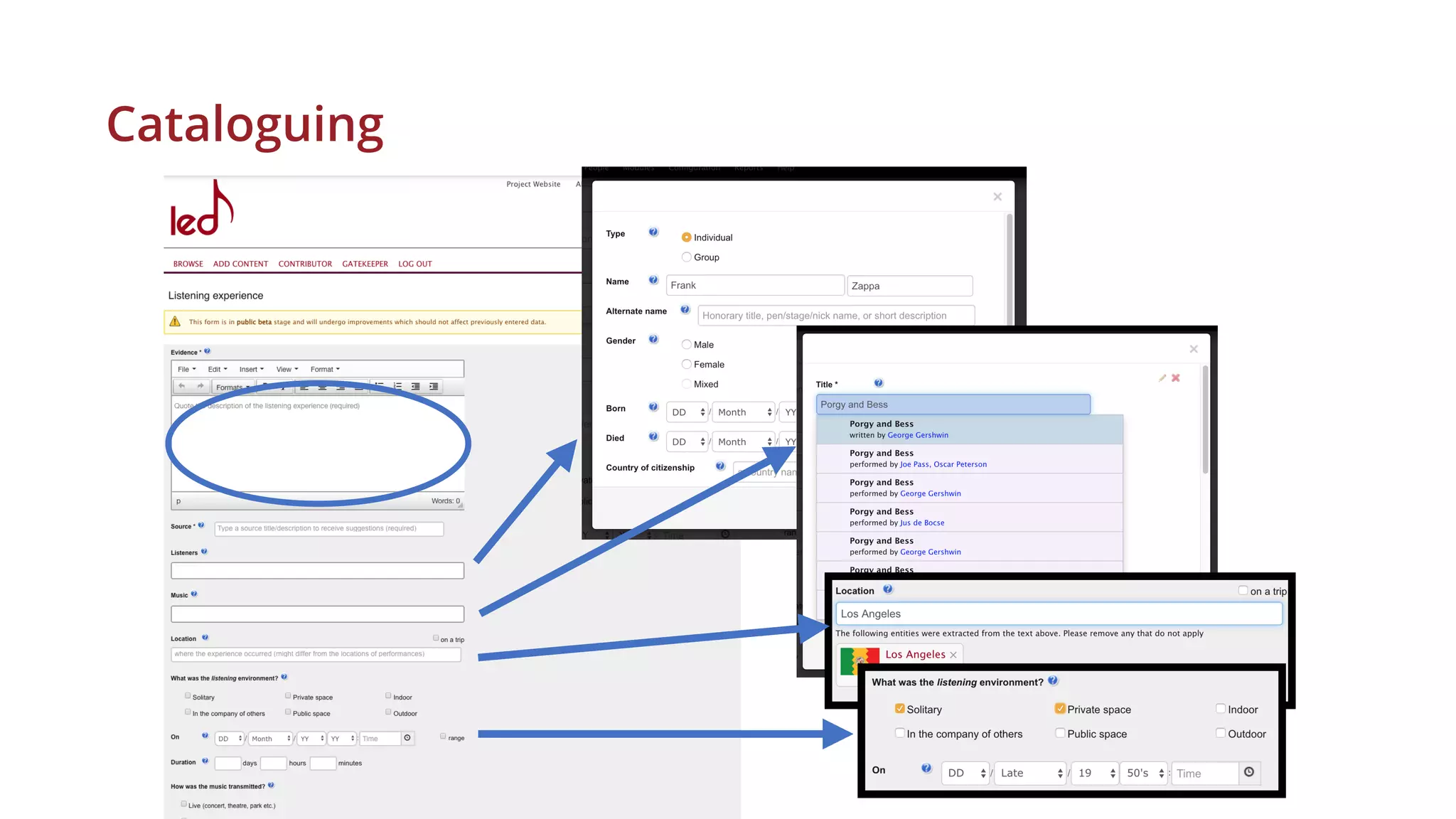
![Finding Listening Experiences (theme: music)
• RECMUS-619, positive: Introduced to the Anacreontic Society, consisting of
amateurs who perform admirably the best orchestral works. The usual supper
followed. After propitiating me with a trio from ’Cosi Fan Tutte’, they drew me to
the piano.
• MASONB-31, positive: In the evening we went to Rev. Baptist Noel’s chapel,
where one is always sure of edification from the sermon if not from the psalms.
• MASONB-88, negative: Flags and pendants were suspended from the
windows, [. . . ] the colors of the German States were waving harmoniously
together, and the banners of the Fine Arts, with appropriate inscriptions,
particularly those of music, poetry and painting, were especially honored, and
floated triumphant amidst the standards of electorates, dukedoms, and
kingdoms.
Daga, Enrico, and Enrico Motta. "Capturing themed evidence, a hybrid approach."
In Proceedings of the 10th International Conference on Knowledge Capture, pp. 93-100. 2019.](https://image.slidesharecdn.com/capturingdocumentaryevidence-v2-210909122714/75/Capturing-the-semantics-of-documentary-evidence-for-humanities-research-5-2048.jpg)

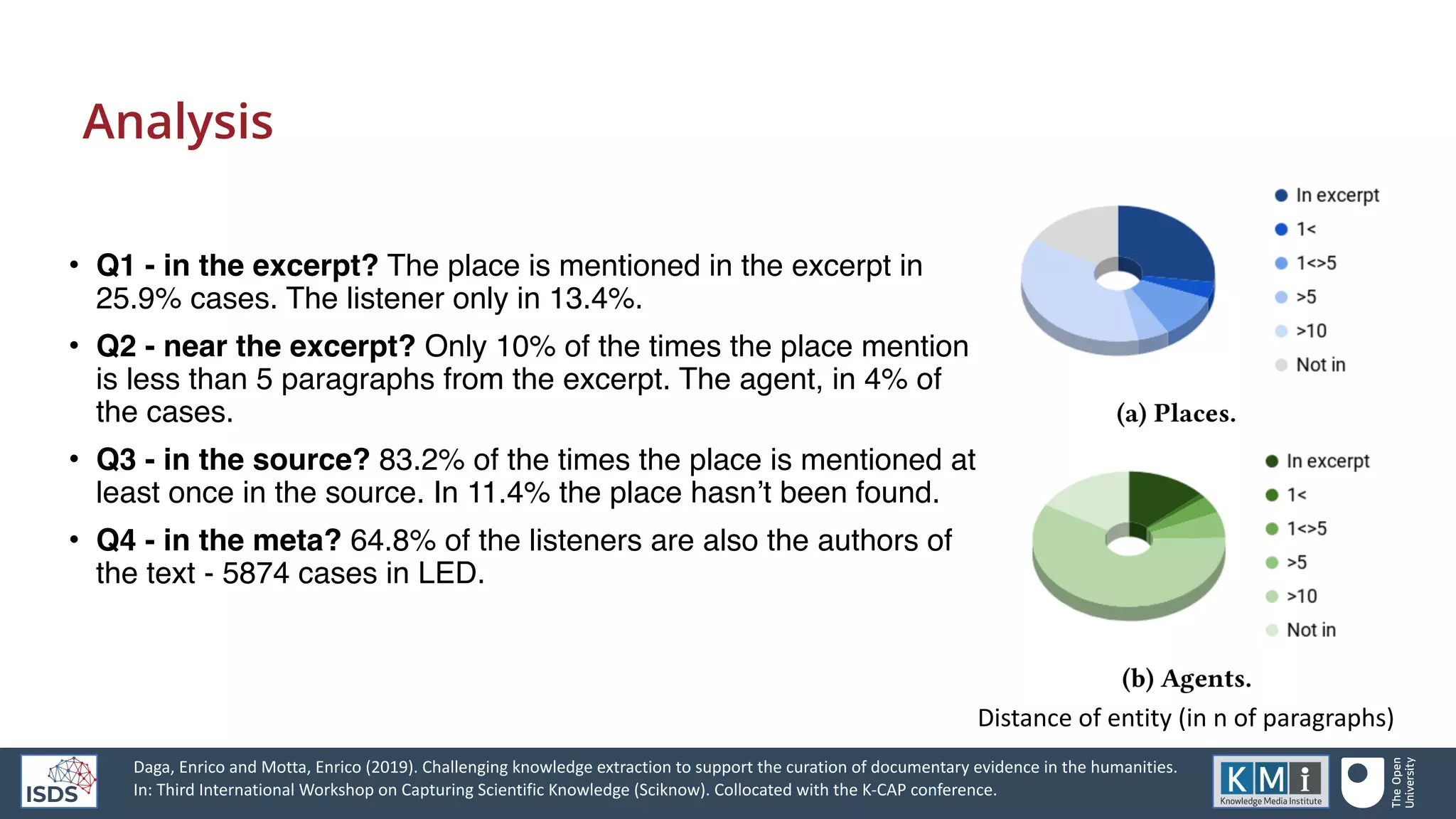
![MASONB-31, positive: In the
evening we went to Rev. Baptist
Noel's chapel, where one is
always sure of edification from the
sermon if not from the psalms.
http://dbpedia.org/resource/
Evening_Prayer_(Anglican)
http://dbpedia.org/resource/Psalms
Daga, Enrico, and Enrico Motta. "Capturing themed evidence, a hybrid approach."
In Proceedings of the 10th International Conference on Knowledge Capture, pp. 93-100. 2019.
MASONB-88, negative: Flags and
pendants were suspended from the
windows, [...] the colours of the
German States were waving
harmoniously together, and the
banners of the Fine Arts, with
appropriate inscriptions, particularly
those of music, poetry and painting,
were especially honored, and ︎oated
triumphant amidst the standards of
electorates, dukedoms, and
kingdoms.
http://dbpedia.org/resource/Music](https://image.slidesharecdn.com/capturingdocumentaryevidence-v2-210909122714/75/Capturing-the-semantics-of-documentary-evidence-for-humanities-research-8-2048.jpg)
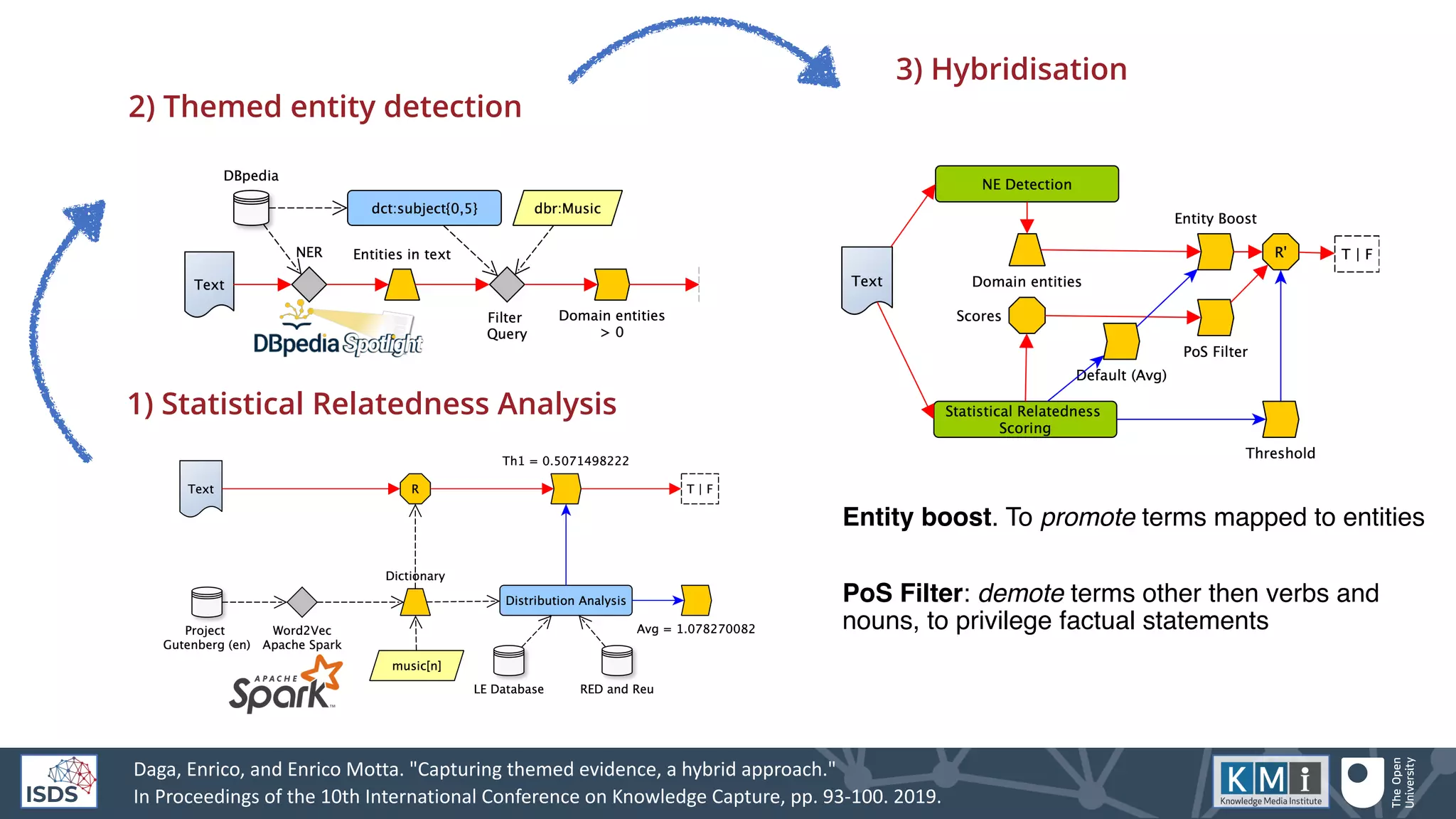
![Evaluation
The results are very good: 87% F-Measure & Accuracy
Baseline methods:
• Fo: Random Forest Classifier high precision, low recall, accuracy slightly
above random (on training/test, it performed 80% accuracy:: robust GS!!!)
• ST: Statistical // a dictionary from Gutenberg’s Music shelf // AVG TF/IDF
Variants on our method:
• Em: Statistical relatedness component only (Embeddings)
• En: Themed entity detection component (Entity) slightly above random:
gold standard is pessimistic / robust!!!
• Em+F: Statistical relatedness + PoS Filter (Embeddings - Filtered)
• Hy-F: No filter, only entity boost (Hybrid - Unfiltered) Without applying
noise correction (POS filter), precision is generally lower; shows the impact
of entity detection on recall
• Hy: best of both worlds. Substantial agreement with annotators (Cohen’s
K)
Our method on an alternative case study:
• Hy/R: Our Hybrid approach on the Reading Experience Database (to
test portability). Core concept: book[n] and core entity: dbc:Literature .
The approach is applicable to other domains with small configuration
Daga, Enrico, and Enrico Motta. "Capturing themed evidence, a hybrid approach."
In Proceedings of the 10th International Conference on Knowledge Capture, pp. 93-100. 2019.](https://image.slidesharecdn.com/capturingdocumentaryevidence-v2-210909122714/75/Capturing-the-semantics-of-documentary-evidence-for-humanities-research-9-2048.jpg)







The document discusses the identification and cataloguing of documentary evidence in humanities research, emphasizing the need for systematic methods to extract and curate this evidence from textual corpora. It introduces a hybrid approach for capturing 'themed evidence,' integrating topical text classification and event retrieval, and evaluates its application in projects such as the Listening Experience Database. Additionally, it highlights challenges in knowledge extraction, emphasizing the domain-specific nature of the humanities and the importance of contextual knowledge for accurate identification of entities.














































![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)
