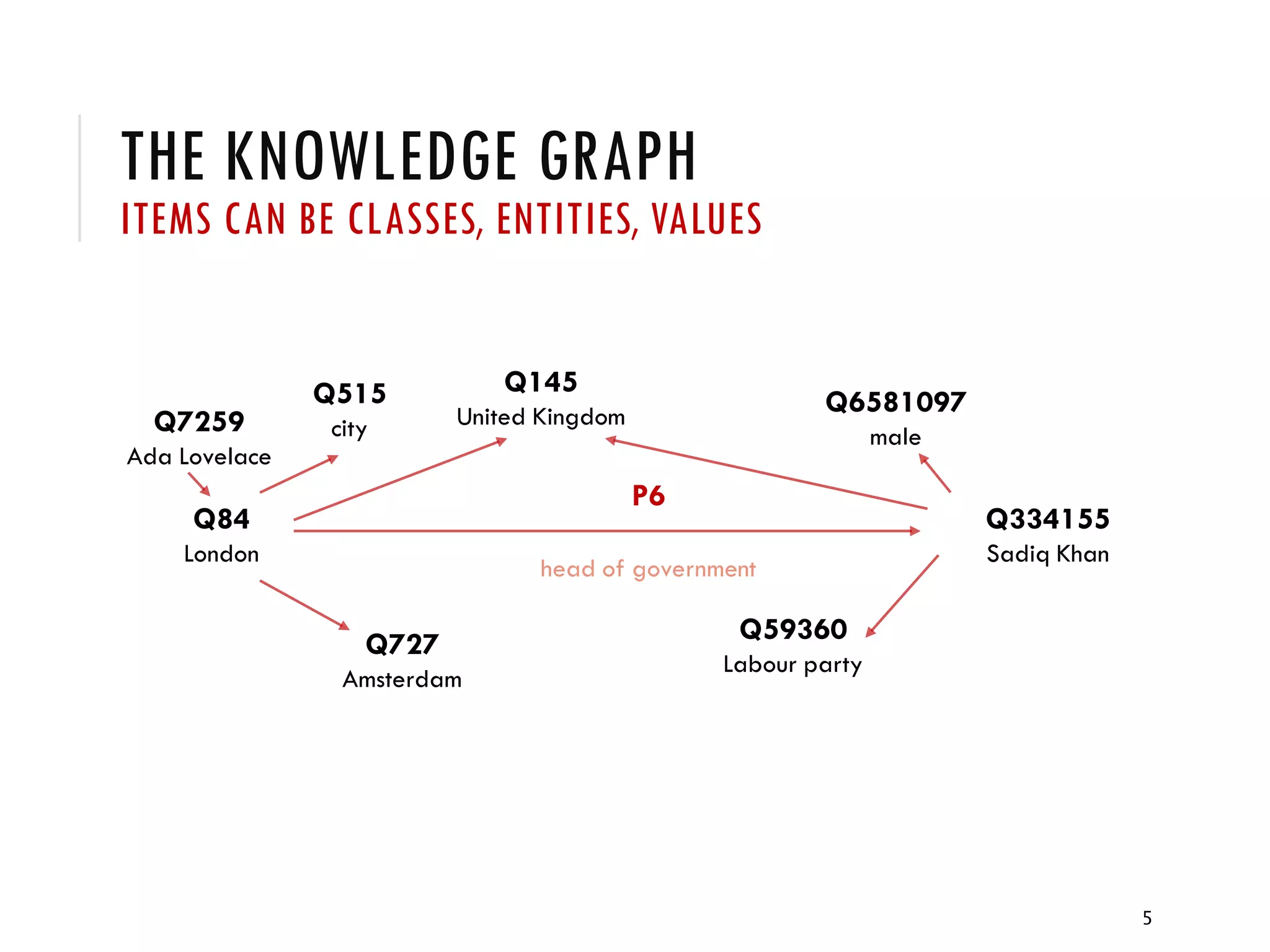
This document summarizes an expert talk about Wikidata and knowledge engineering. The key points are:
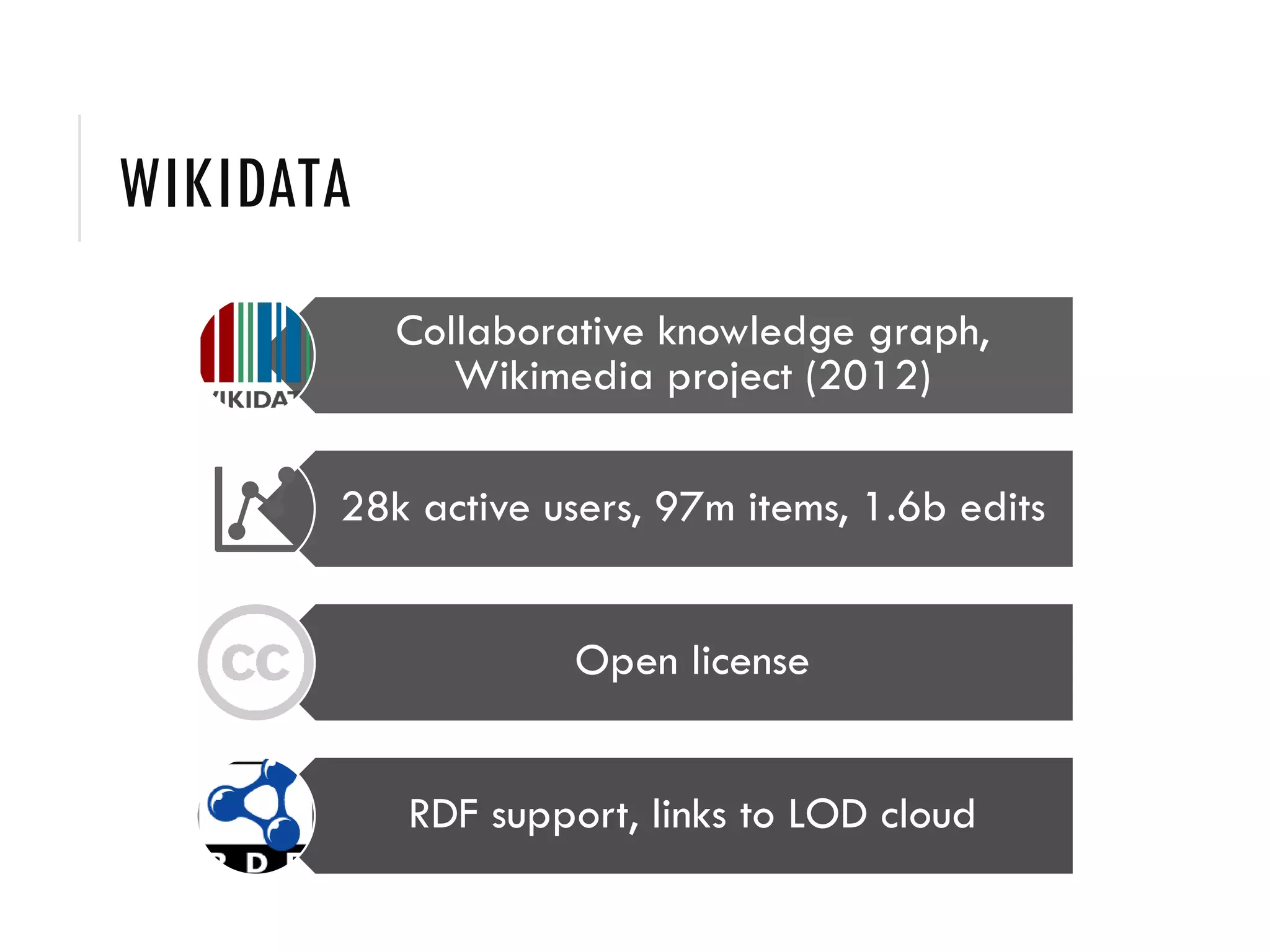
1) Wikidata is a collaborative knowledge graph with over 28,000 active users that contains over 97 million items and 1.6 billion edits. It allows both human and bot editors.
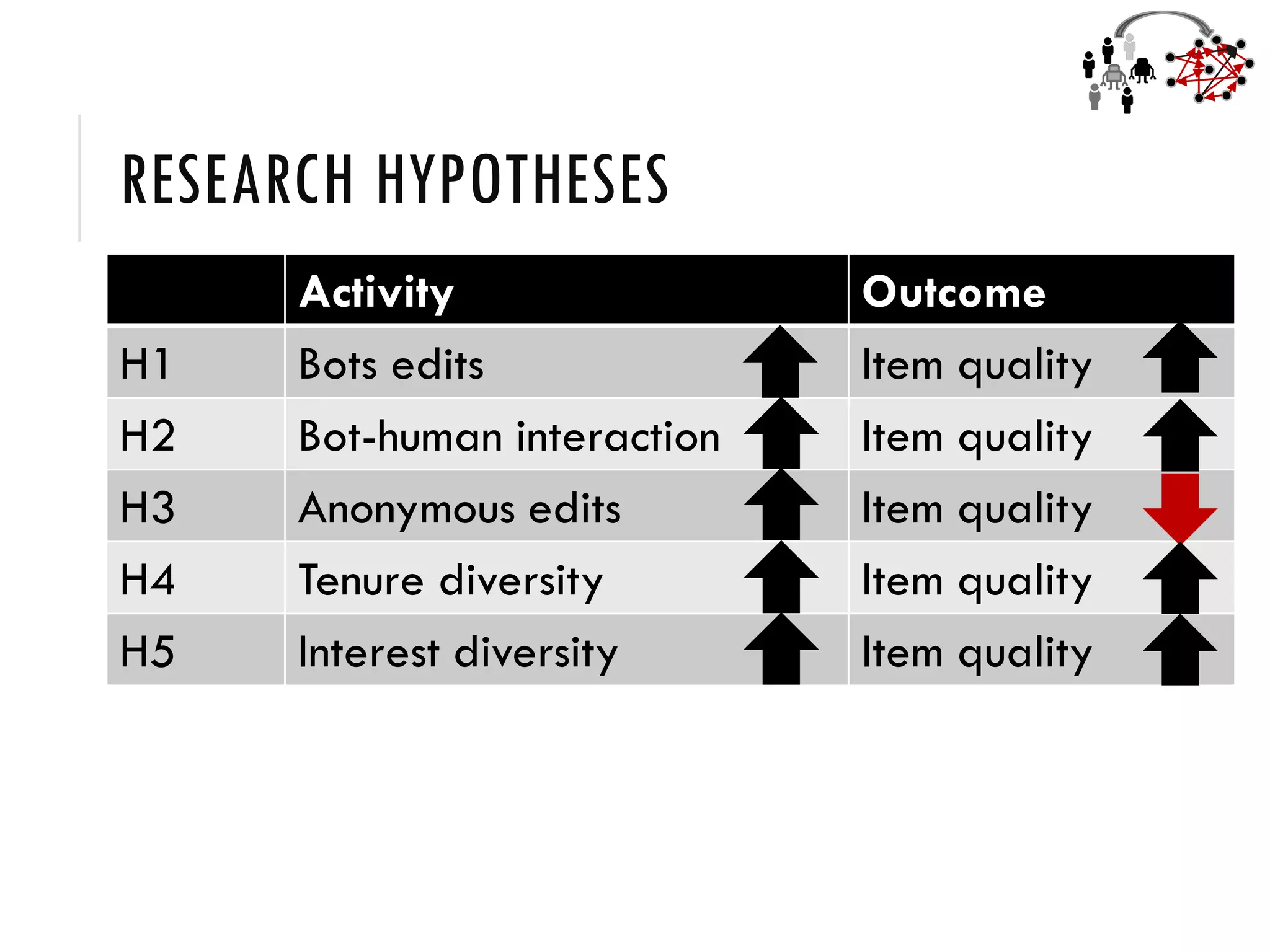
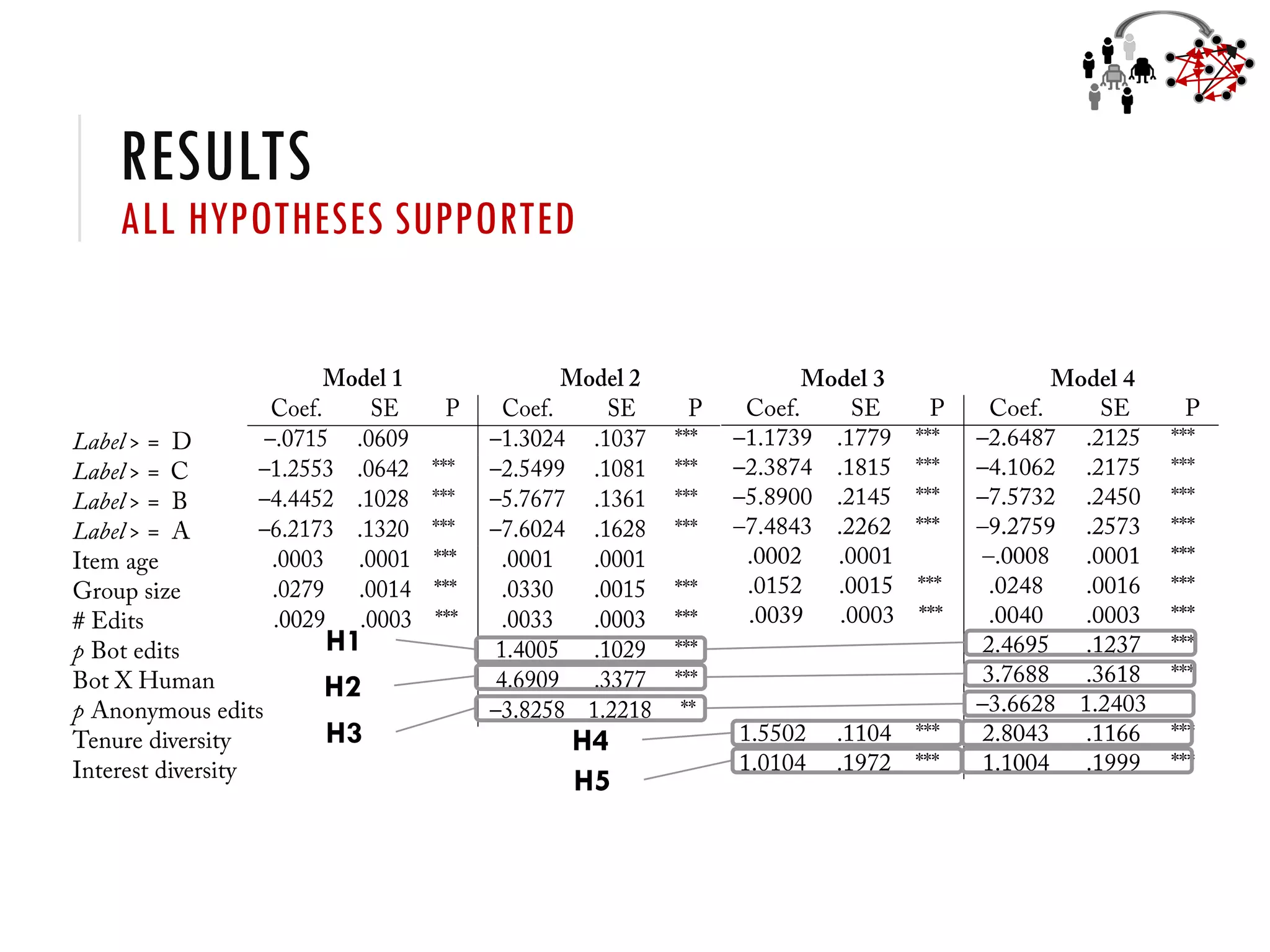
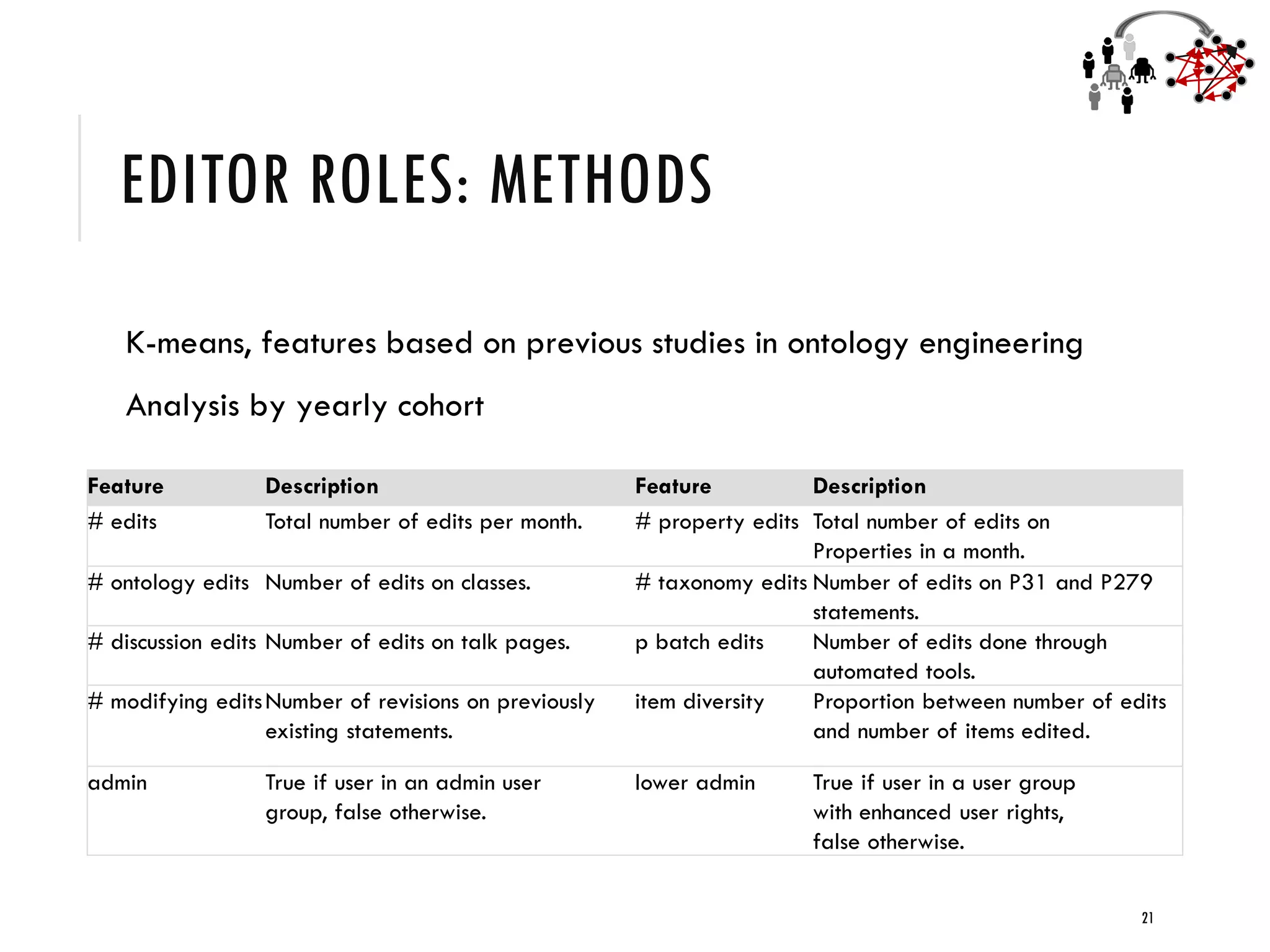
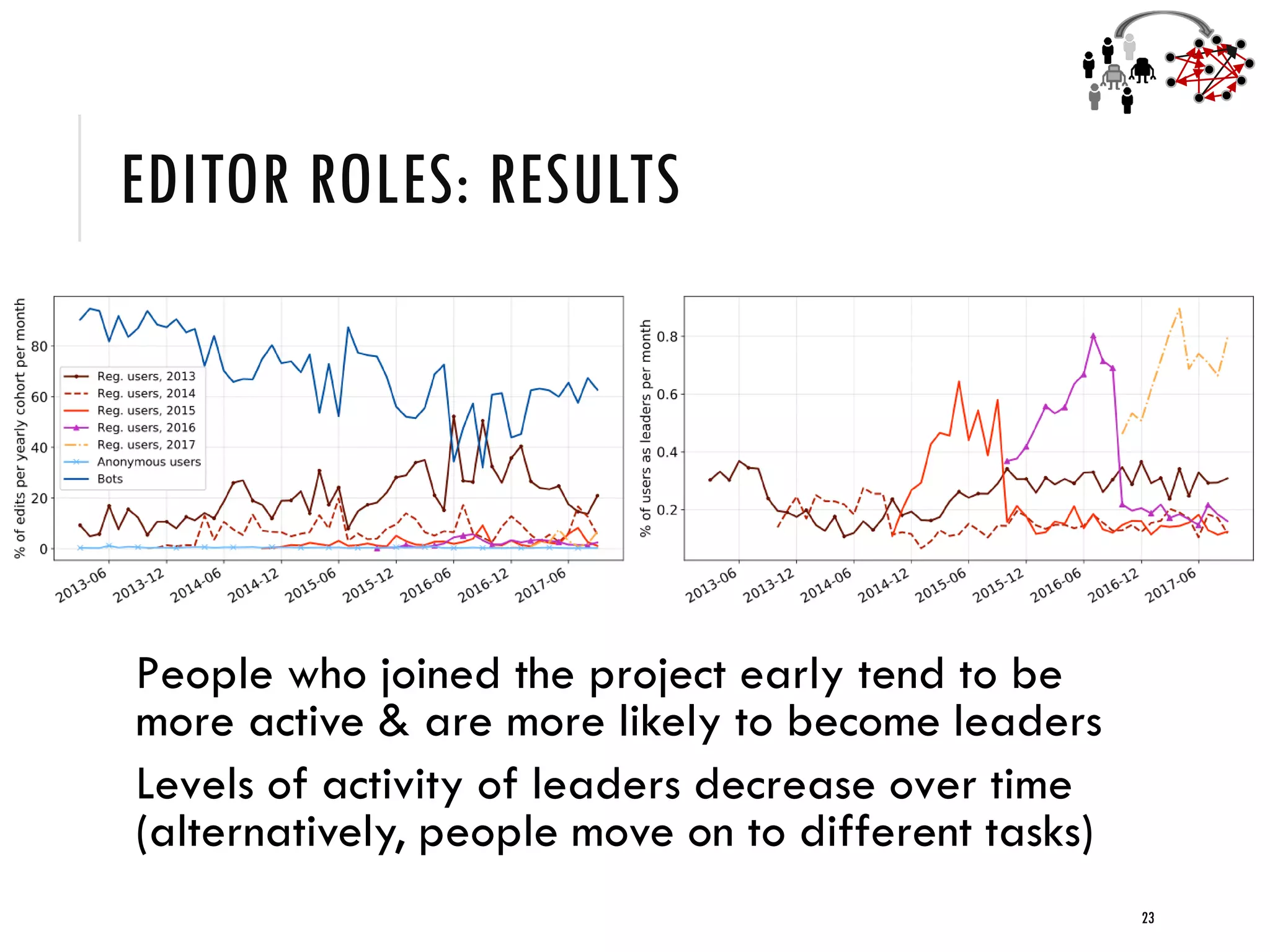
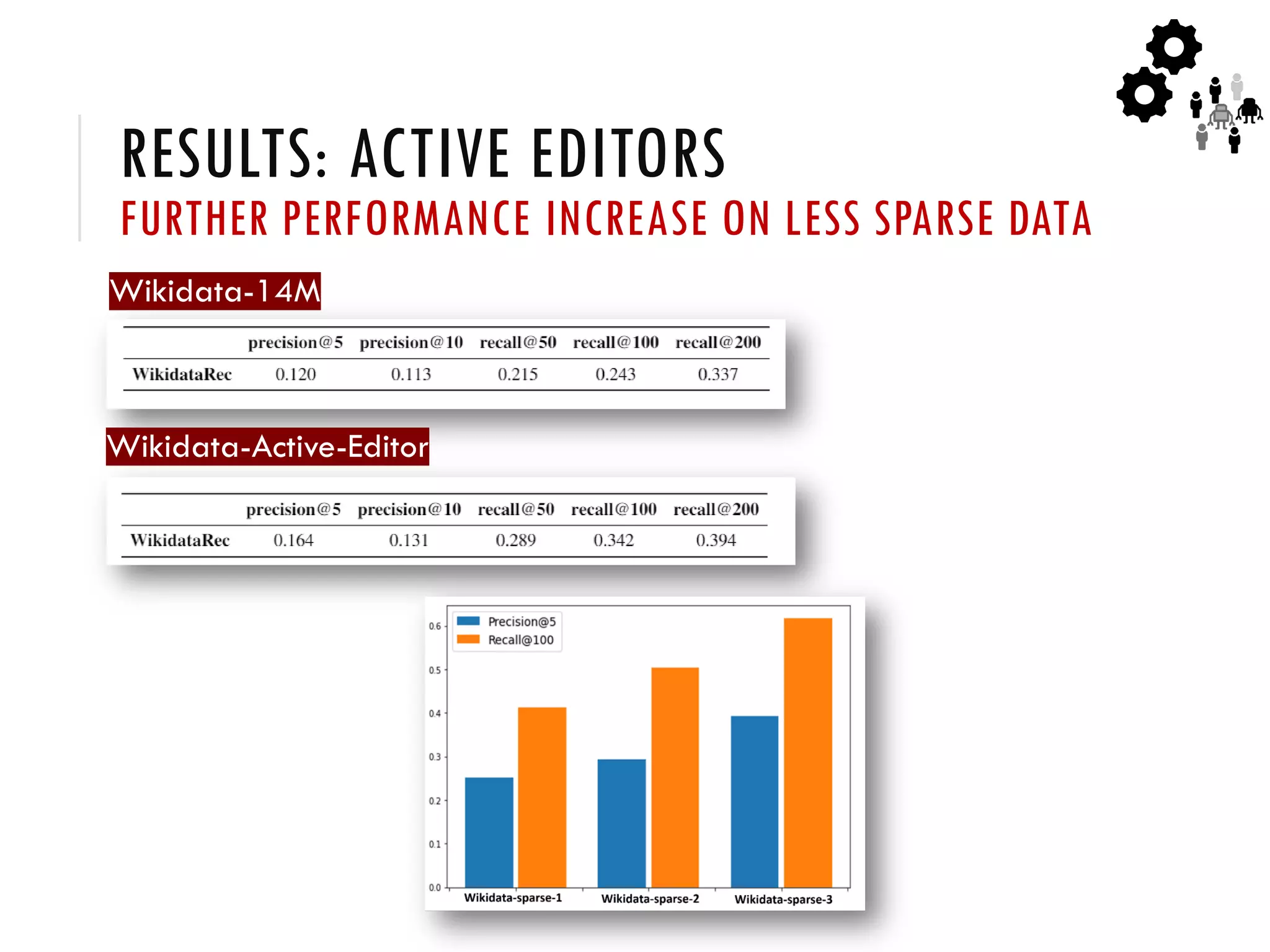
2) Studies of Wikidata show that a balanced mix of bot and human editors, as well as diversity in editor tenure and interests, leads to higher quality knowledge graph items and ontology.
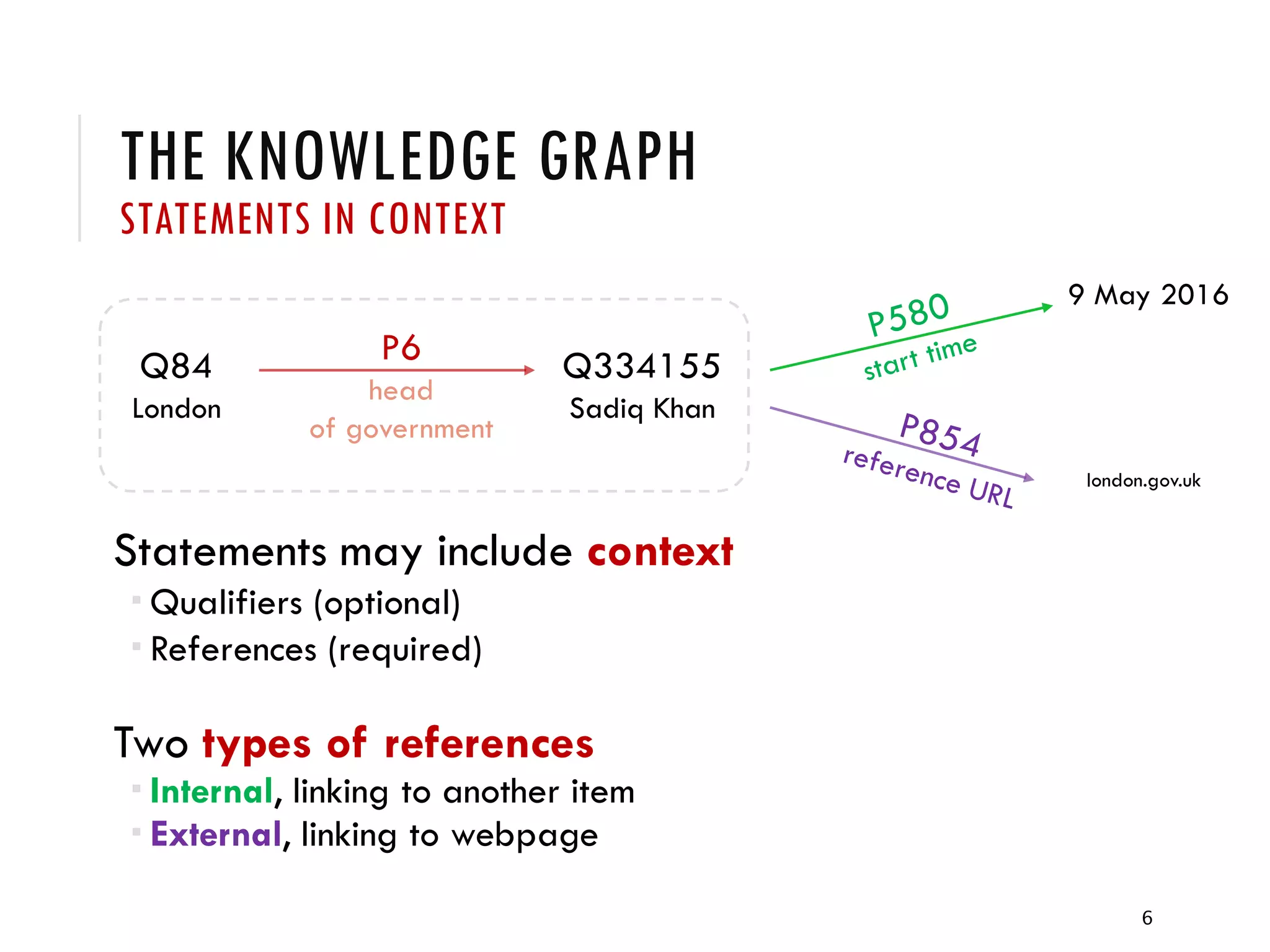
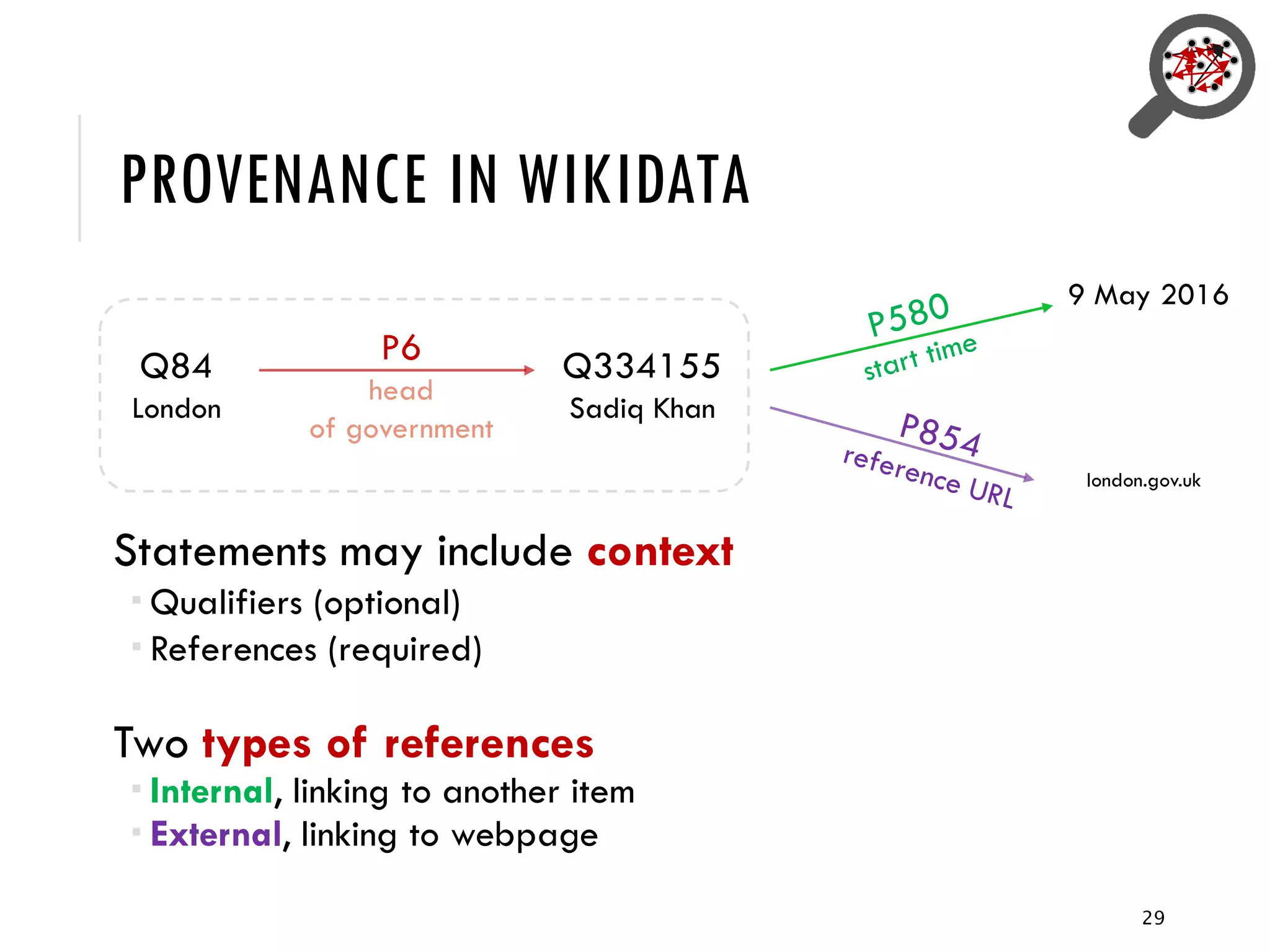
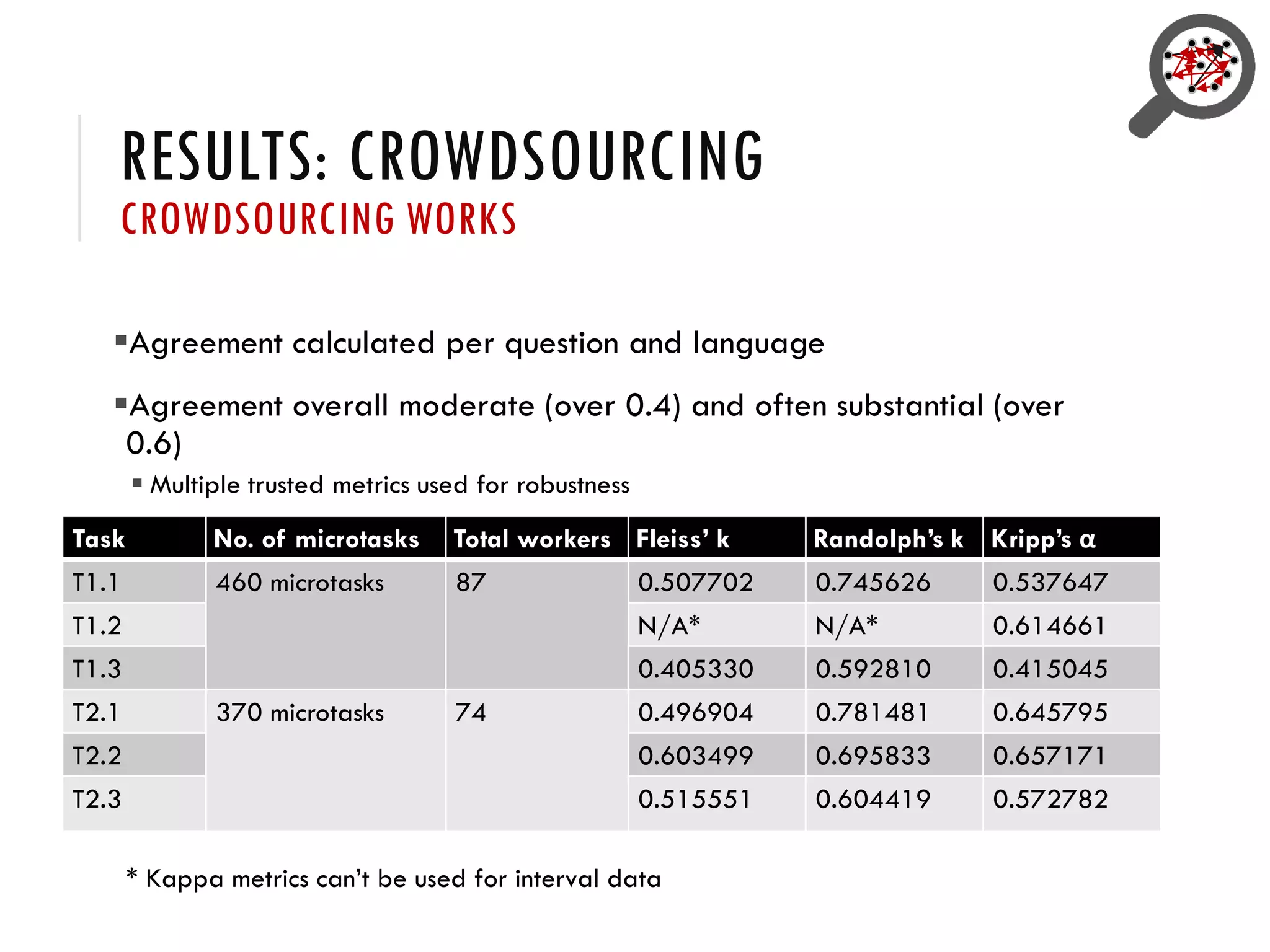
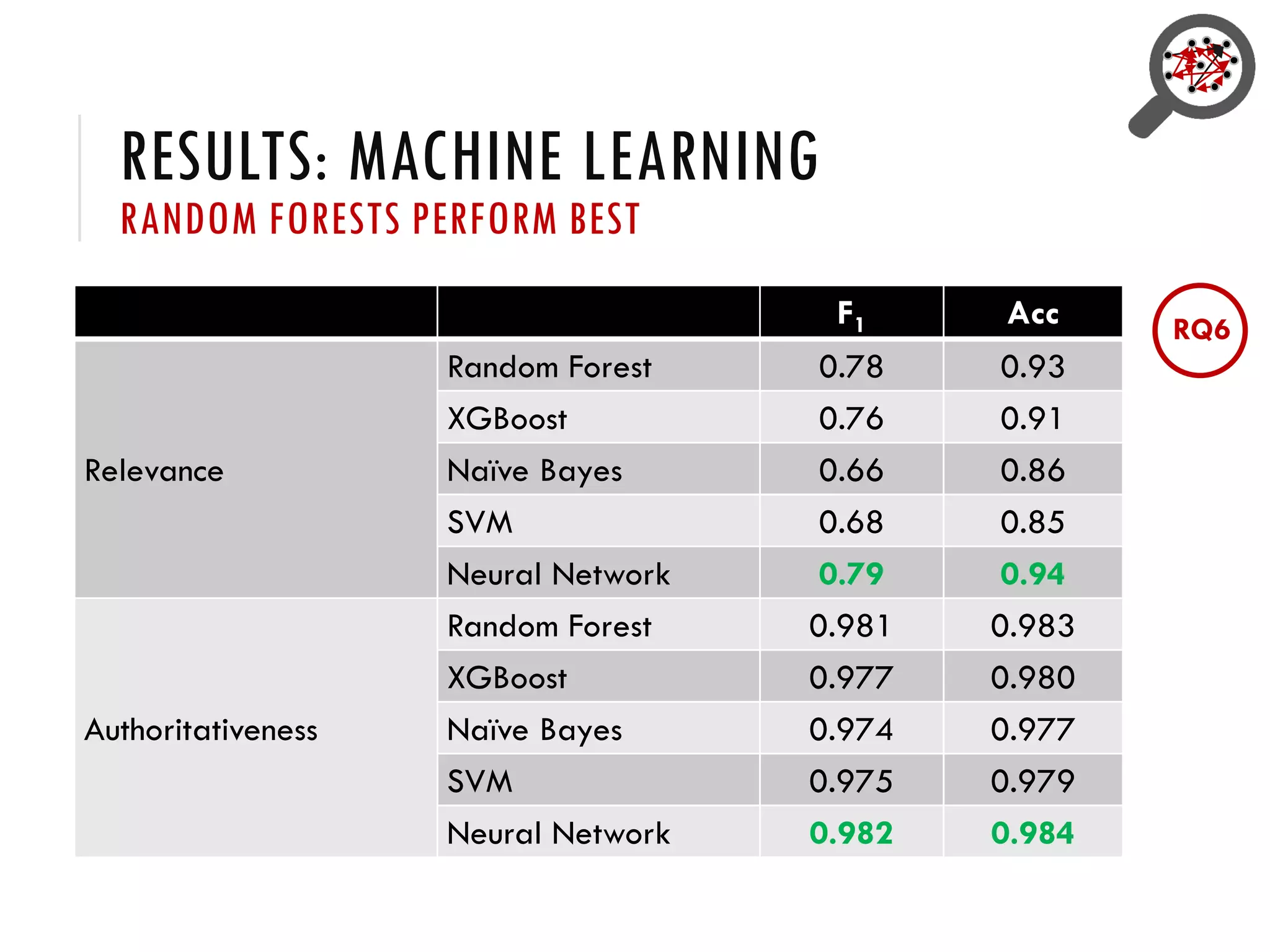
3) Provenance or references are important for trust in Wikidata statements, but the quality of these references is not well understood and varies across languages. Further research is exploring how to better evaluate reference quality.