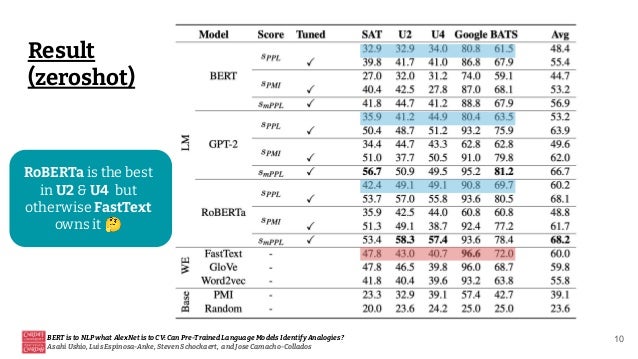
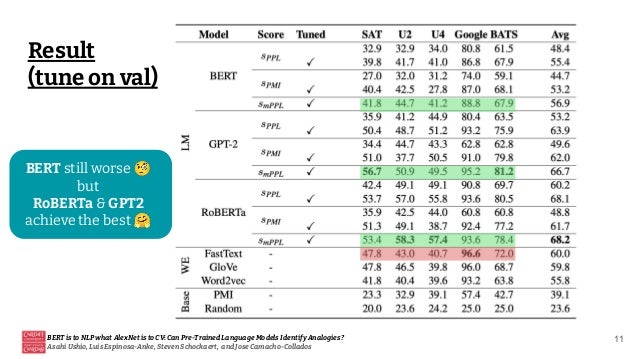
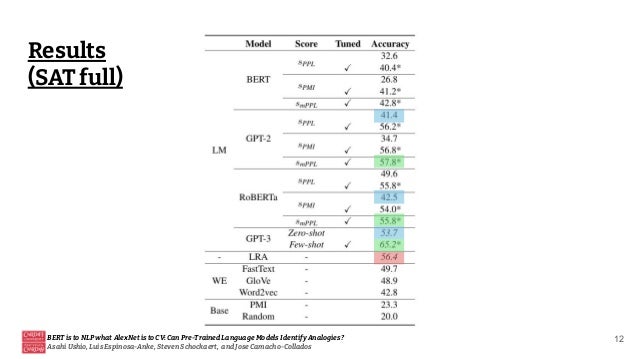
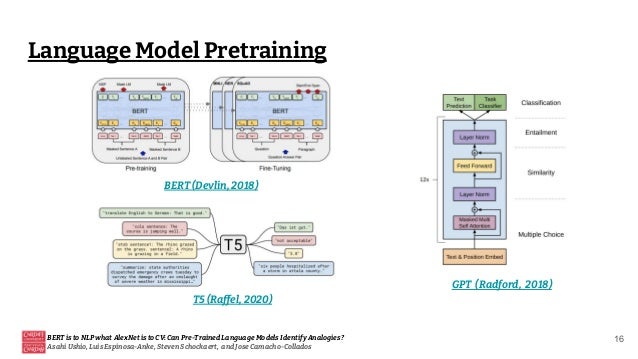
This document discusses the ability of pre-trained language models to identify analogies, drawing a parallel between their significance in natural language processing (NLP) and the role of AlexNet in computer vision (CV). It highlights the varying performance of models like RoBERTa and GPT-2 in analogy tasks, the sensitivity of these models to hyperparameter tuning, and the potential for future improvements through prompt mining and supervision during pretraining. Ultimately, it concludes that while some language models exhibit a capacity for relational knowledge, there is still considerable room for enhancement.




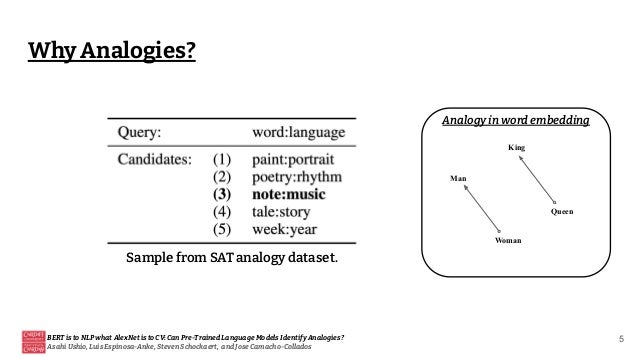
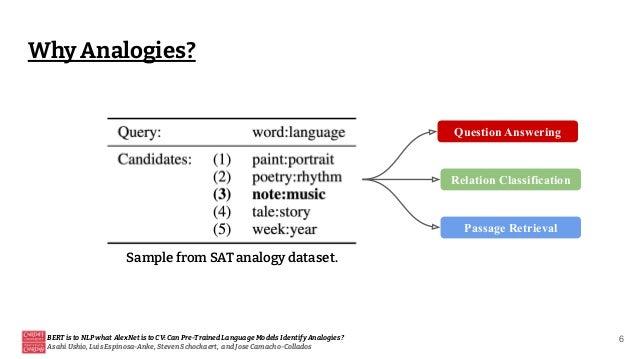
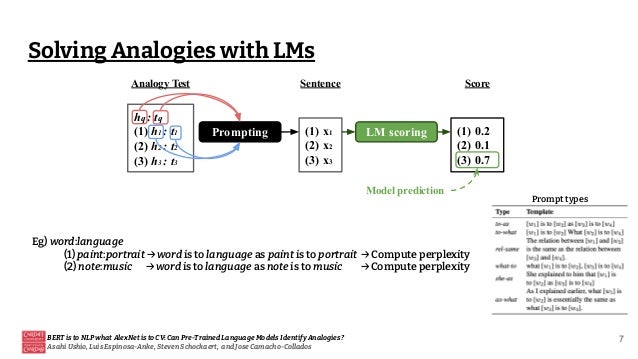

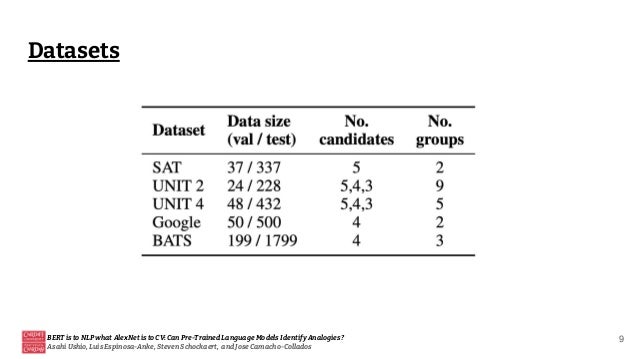






















![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)





































