Downloaded 20 times






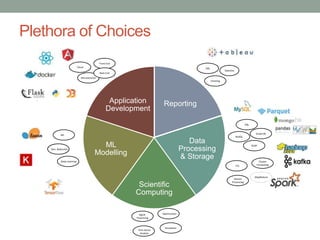
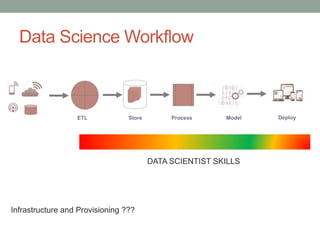
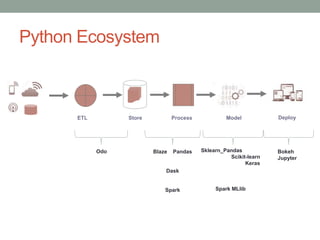







This document provides an overview of the Python ecosystem for data science. It describes how tools in the ecosystem can be used to support various data science tasks like reporting, data processing, scientific computing, machine learning modeling, and application development. The document outlines common workflows for small, medium and big data use cases. It also reviews popular Python tools, identifies strengths in the current ecosystem, and discusses some gaps from a practitioner's perspective.

















































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)
![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)
















