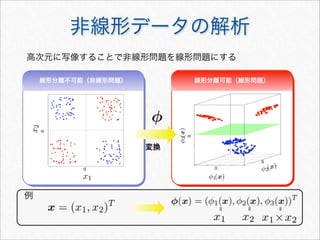
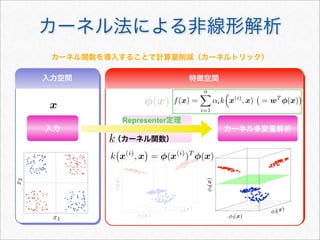
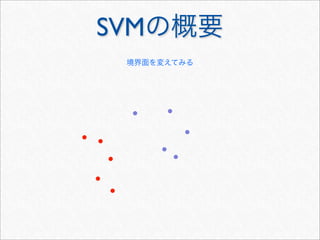
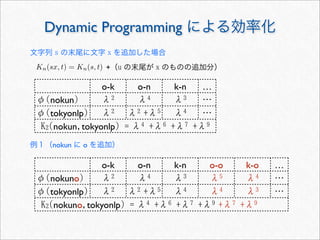
Dynamic Programming による効率化
Kn(sx,t) = Kn(s, t) +(u の末尾が x で終わるものの追加分)
文字列 s の末尾に文字 x を追加した場合
s
t
u
u x
x
x
|s| + 1i1
j1
t
x
jn−1 + 1 k
|s| + 1 − i1 + 1
u が x より手前にある t の部分文字列の集合
Kn(sx, t) = Kn(s, t) +
u∈Σn−1
i:u=s[i]
k:tk=x
j:u=t[j],jn−1k
λ|s|+1−i1+1
λk−j1+1
= Kn(s, t) +
k:tk=x
λ2
u∈Σn−1
i:u=s[i]
j:u=t[j],jn−1k
λ|s|−i1+1
λk−1−j1+1
= Kn(s, t) +
k:tk=x
λ2
K
n−1(s, t[1 : k − 1])
K
n(s, t) =
u∈Σn
i:u=s[i]
j:u=t[j]
λ|s|−i1+1
λ|t|−j1+1
※ は文字列 の長さ|s| s
36.
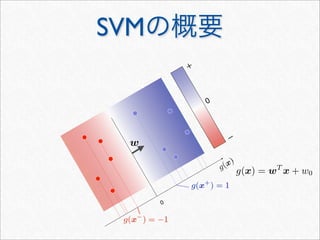
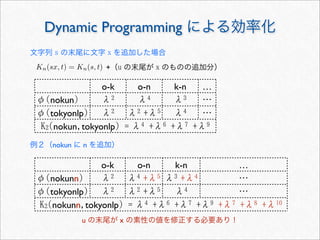
Dynamic Programming による効率化
s
x
x
x
K
n(s,t) =
u∈Σn
i:u=s[i]
j:u=t[j]
λ|s|−i1+1
λ|t|−j1+1
t[1 : k − 1]
t[1 : k − 1]
Kn(sx, t) = Kn(s, t) +
k:tk=x
λ2
K
n−1(s, t[1 : k − 1])
s
t
j1
i1
|s| + i1 + 1
|t| + j1 + 1
u
k
の意味K
n(s, t)
改めて の意味Kn(s, t)
37.
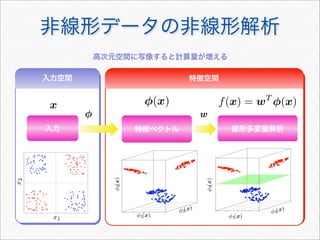
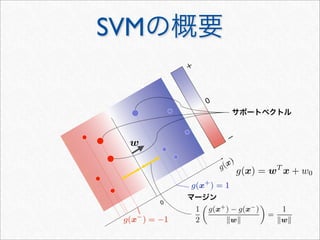
Dynamic Programming による効率化
K
n(sx,t) = λK
n(s, t) +
u∈Σn−1
i:u=s[i]
k:tk=x
j:u=t[j],jn−1k
λ|s|+1−i1+1
λ|t|−j1+1
= λK
n(s, t) +
k:tk=x
λ|t|−k+2
u∈Σn−1
i:u=s[i]
j:u=t[j],jn−1k
λ|s|−i1+1
λk−1−j1+1
= λK
n(s, t) +
k:tk=x
λ|t|−k+2
K
n−1(s, t[1 : k − 1])
= λK
n(s, t) + K
n(sx, t)
K
n(s, t) の更新式( と同様)Kn(s, t)
K
n(sx, t) =
k:tk=x
λ|t|−k+2
K
n−1(s, t[1 : k − 1])
38.
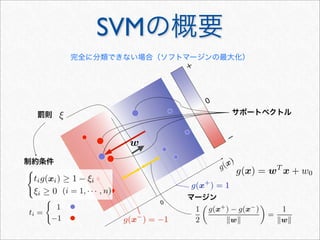
K
n(sx, ty) =
λK
n(sx,t) if x = y
λK
n(sx, t) + λ2
K
n−1(s, t) otherwise
Dynamic Programming による効率化
の更新式
単純に2つの項に分解
t
= ty とおくと
よって
K
n(s, t)
K
n(sx, t
) =
k:t
k=x
λ|t
|−k+2
K
n−1(s, t
[1 : k − 1])
= λ
k:t
k=x,k|t|
λ|t|−k+2
K
n−1(s, t[1 : k − 1]) + λ2
K
n−1(s, t)[[t
k = x, k = |t
|]]
= λK
n(sx, t) + λ2
K
n−1(s, t)[[t
k = x, k = |t
|]]
39.
K
i (sx, ty)=
λK
i (sx, t) if x = y
λK
i (sx, t) + λ2
K
i−1(s, t) otherwise
Gap-weighted String Kernel の更新式
i = 1, · · · , n − 1
K
0(s, t) = 1 ∀
s, t
K
i (s, t) = 0 if min(|s|, |t|) i
K
i(s, t) = 0 if min(|s|, |t|) i
K
i(sx, t) = λK
i(s, t) + K
i (sx, t)
Ki(s, t) = 0 if min(|s|, |t|) i
Kn(sx, t) = Kn(s, t) +
k:tk=x
λ2
K
n−1(s, t[1 : k − 1])
40.
Gap-weighted String Kernelの”擬似”コード(1)
l = 0.7 # lambda
def indices(t, x):
ret = [];
pos = -1;
while 1:
pos = t.find(x, pos + 1)
if pos != -1:
ret.append(pos)
else:
break
return ret
def K(i, s, t):
if min(len(s), len(t)) i:
return 0
return K(i, s[0:-1], t) + l ** 2 * sum([K1(i - 1, s[0:-1], t[0:j]) for j in
indices(t, s[-1])])
Ki(s, t) = 0 if min(|s|, |t|) i
Kn(sx, t) = Kn(s, t) +
k:tk=x
λ2
K
n−1(s, t[1 : k − 1])
41.
K
i (sx, ty)=
λK
i (sx, t) if x = y
λK
i (sx, t) + λ2
K
i−1(s, t) otherwise
def K1(i, s, t):
if i == 0:
return 1
if min(len(s), len(t)) i:
return 0
return l * K1(i, s[0:-1], t) + K2(i, s, t)
Gap-weighted String Kernel の”擬似”コード(2)
K
0(s, t) = 1 ∀
s, t
K
i (s, t) = 0 if min(|s|, |t|) i
K
i(s, t) = 0 if min(|s|, |t|) i
K
i(sx, t) = λK
i(s, t) + K
i (sx, t)
def K2(i, s, t):
if min(len(s), len(t)) i:
return 0
if s[-1] == t[-1]:
return l * (K2(i, s, t[0:-1]) + l * K1(i -1, s[0:-1], t[0:-1]))
else:
return l * K2(i, s, t[0:-1])
• 赤穂昭太郎, カーネル多変量解析,岩波書店, 2008
前半部分は全てこの内容
• H. Lodhi, C. Saunders, J. Shawe-Taylor, N. Cristianini, and C.Watkins.Text
Classification using String Kernels. Journal of Machine Learning Research,Vol. 2, pp.
419–444, 2002.
Gap-weighted String Kernel の元論文
• カーネル法の応用 http://www.ism.ac.jp/~fukumizu/ISM_lecture_2006/
Lecture2006_application.pdf
• 文書分類と Kernel あれこれ(仮称) http://www.ism.ac.jp/~fukumizu/
ISM_lecture_2006/Lecture2006_application.pdf
• Juho Rousu , John Shawe-Taylor. Efficient Computation of Gapped Substring
Kernels on Large Alphabets,The Journal of Machine Learning Research,Vol. 6, pp.
1323-1344, 2005.
余裕があればこっちの方を理解して紹介したかった・・・
参考文献

















![文字列カーネルとは
入力として文字列を扱い部分文字列の出現回数などで表現される
特徴空間での内積を返す
k(x, x
) = xT
x
k(x, x
) = (xT
x
+ c)p
線形カーネル
多項式カーネル
文字列カーネル
入力が数値ベクトル
入力が文字列(1次元)(例)Gap-weighted String Kernel
文字数で区切るので辞書いらず!
k(s, t) =
u∈Σn
i:u=s[i]
j:u=t[j]
λspan(i)+span(j)](https://image.slidesharecdn.com/stringkernelupload-110910001058-phpapp01/85/slide-28-320.jpg)


![Gap-weighted String Kernel
φu(s) =
i:u=s[i]
λspan(i)
tokyonlp
nokuno
tokyonlp
φon(tokyonlp) = λ5
+ λ2
φon(nokuno) = λ4
span(i1 = 2, i2 = 6) = 5
span(i1 = 5, i2 = 6) = 2
span(i1 = 2, i2 = 5) = 4
マッチしなければ空集合
部分文字列 u の素性の値(素性ベクトルの1要素)
(例)u = “on”, s = “nokuno”,“tokyonlp” の場合
si1
= u1, si2
= u2, · · · , sin
= un
span(i) = sin
− si1
+ 1
decay factor λ ∈ (0, 1)](https://image.slidesharecdn.com/stringkernelupload-110910001058-phpapp01/85/slide-31-320.jpg)
![Gap-weighted String Kernel
Kn(s, t) =
u∈Σn
φu(s)φu(t) =
u∈Σn
i:u=s[i]
λspan(i)
j:u=t[j]
λspan(j)
=
u∈Σn
i:u=s[i]
j:u=t[j]
λspan(i)+span(j)
1つの計算量が c とすると
全体の計算量は O(|Σ|n) !!
カーネル関数(パラメータは n と λ の2つ)
正規化(文字列の長さの違いを考慮)
ˆK(s, t) = ˆφ(s)T ˆφ(t) =
φ(s)T
φ(s)
φ(t)
φ(t)
=
1
φ(s)φ(t)
φ(s)T
φ(t) =
K(s, t)
K(s, s)K(t, t)
長さ1になるように正規化した素性ベクトル
長さ n の全ての
文字列の集合](https://image.slidesharecdn.com/stringkernelupload-110910001058-phpapp01/85/slide-32-320.jpg)
![Dynamic Programming による効率化
Kn(sx, t) = Kn(s, t) +(u の末尾が x で終わるものの追加分)
文字列 s の末尾に文字 x を追加した場合
s
t
u
u x
x
x
|s| + 1i1
j1
t
x
jn−1 + 1 k
|s| + 1 − i1 + 1
u が x より手前にある t の部分文字列の集合
Kn(sx, t) = Kn(s, t) +
u∈Σn−1
i:u=s[i]
k:tk=x
j:u=t[j],jn−1k
λ|s|+1−i1+1
λk−j1+1
= Kn(s, t) +
k:tk=x
λ2
u∈Σn−1
i:u=s[i]
j:u=t[j],jn−1k
λ|s|−i1+1
λk−1−j1+1
= Kn(s, t) +
k:tk=x
λ2
K
n−1(s, t[1 : k − 1])
K
n(s, t) =
u∈Σn
i:u=s[i]
j:u=t[j]
λ|s|−i1+1
λ|t|−j1+1
※ は文字列 の長さ|s| s](https://image.slidesharecdn.com/stringkernelupload-110910001058-phpapp01/85/slide-35-320.jpg)
![Dynamic Programming による効率化
s
x
x
x
K
n(s, t) =
u∈Σn
i:u=s[i]
j:u=t[j]
λ|s|−i1+1
λ|t|−j1+1
t[1 : k − 1]
t[1 : k − 1]
Kn(sx, t) = Kn(s, t) +
k:tk=x
λ2
K
n−1(s, t[1 : k − 1])
s
t
j1
i1
|s| + i1 + 1
|t| + j1 + 1
u
k
の意味K
n(s, t)
改めて の意味Kn(s, t)](https://image.slidesharecdn.com/stringkernelupload-110910001058-phpapp01/85/slide-36-320.jpg)
![Dynamic Programming による効率化
K
n(sx, t) = λK
n(s, t) +
u∈Σn−1
i:u=s[i]
k:tk=x
j:u=t[j],jn−1k
λ|s|+1−i1+1
λ|t|−j1+1
= λK
n(s, t) +
k:tk=x
λ|t|−k+2
u∈Σn−1
i:u=s[i]
j:u=t[j],jn−1k
λ|s|−i1+1
λk−1−j1+1
= λK
n(s, t) +
k:tk=x
λ|t|−k+2
K
n−1(s, t[1 : k − 1])
= λK
n(s, t) + K
n(sx, t)
K
n(s, t) の更新式( と同様)Kn(s, t)
K
n(sx, t) =
k:tk=x
λ|t|−k+2
K
n−1(s, t[1 : k − 1])](https://image.slidesharecdn.com/stringkernelupload-110910001058-phpapp01/85/slide-37-320.jpg)
![K
n(sx, ty) =
λK
n(sx, t) if x = y
λK
n(sx, t) + λ2
K
n−1(s, t) otherwise
Dynamic Programming による効率化
の更新式
単純に2つの項に分解
t
= ty とおくと
よって
K
n(s, t)
K
n(sx, t
) =
k:t
k=x
λ|t
|−k+2
K
n−1(s, t
[1 : k − 1])
= λ
k:t
k=x,k|t|
λ|t|−k+2
K
n−1(s, t[1 : k − 1]) + λ2
K
n−1(s, t)[[t
k = x, k = |t
|]]
= λK
n(sx, t) + λ2
K
n−1(s, t)[[t
k = x, k = |t
|]]](https://image.slidesharecdn.com/stringkernelupload-110910001058-phpapp01/85/slide-38-320.jpg)
![K
i (sx, ty) =
λK
i (sx, t) if x = y
λK
i (sx, t) + λ2
K
i−1(s, t) otherwise
Gap-weighted String Kernel の更新式
i = 1, · · · , n − 1
K
0(s, t) = 1 ∀
s, t
K
i (s, t) = 0 if min(|s|, |t|) i
K
i(s, t) = 0 if min(|s|, |t|) i
K
i(sx, t) = λK
i(s, t) + K
i (sx, t)
Ki(s, t) = 0 if min(|s|, |t|) i
Kn(sx, t) = Kn(s, t) +
k:tk=x
λ2
K
n−1(s, t[1 : k − 1])](https://image.slidesharecdn.com/stringkernelupload-110910001058-phpapp01/85/slide-39-320.jpg)
![Gap-weighted String Kernel の”擬似”コード(1)
l = 0.7 # lambda
def indices(t, x):
ret = [];
pos = -1;
while 1:
pos = t.find(x, pos + 1)
if pos != -1:
ret.append(pos)
else:
break
return ret
def K(i, s, t):
if min(len(s), len(t)) i:
return 0
return K(i, s[0:-1], t) + l ** 2 * sum([K1(i - 1, s[0:-1], t[0:j]) for j in
indices(t, s[-1])])
Ki(s, t) = 0 if min(|s|, |t|) i
Kn(sx, t) = Kn(s, t) +
k:tk=x
λ2
K
n−1(s, t[1 : k − 1])](https://image.slidesharecdn.com/stringkernelupload-110910001058-phpapp01/85/slide-40-320.jpg)
![K
i (sx, ty) =
λK
i (sx, t) if x = y
λK
i (sx, t) + λ2
K
i−1(s, t) otherwise
def K1(i, s, t):
if i == 0:
return 1
if min(len(s), len(t)) i:
return 0
return l * K1(i, s[0:-1], t) + K2(i, s, t)
Gap-weighted String Kernel の”擬似”コード(2)
K
0(s, t) = 1 ∀
s, t
K
i (s, t) = 0 if min(|s|, |t|) i
K
i(s, t) = 0 if min(|s|, |t|) i
K
i(sx, t) = λK
i(s, t) + K
i (sx, t)
def K2(i, s, t):
if min(len(s), len(t)) i:
return 0
if s[-1] == t[-1]:
return l * (K2(i, s, t[0:-1]) + l * K1(i -1, s[0:-1], t[0:-1]))
else:
return l * K2(i, s, t[0:-1])](https://image.slidesharecdn.com/stringkernelupload-110910001058-phpapp01/85/slide-41-320.jpg)


![データの取得
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import tweepy
import re
import codecs
def format_tweet(tweet):
tweet = re.sub(r'[rn]', ' ', tweet) # remove CR and LF
tweet = re.sub(r's*https?://[-w.#%@/?=]*s*', ' ', tweet) # remove URL
tweet = re.sub(r'(^|s+)#[^s]+s*', ' ', tweet) # remove hash tags
tweet = re.sub(r's*(?!w)@w+(?!@)s*', ' ', tweet) # remove user names
return tweet
api = tweepy.API()
f = open('tweets.dat', 'w')
f = codecs.lookup('utf_8')[-1](f)
for c, user in zip((-1, 1), ('a_bicky', 'midoisan')):
print user
for i in range(1, 4):
while True:
print i
try:
statuses = api.user_timeline(user, count = 200, page = i)
break
except:
print ’Try again...’
for tweet in map(lambda s:format_tweet(s.text), statuses):
f.write('%s #%sn' % (c, tweet))
f.close()
# 1人あたり約500ツイート取得
# SVMlightで使えるデータ形式で保存](https://image.slidesharecdn.com/stringkernelupload-110910001058-phpapp01/85/slide-44-320.jpg)





![SVMlight で文字列カーネル
double custom_kernel(KERNEL_PARM *kernel_parm, SVECTOR *a, SVECTOR *b)
{
char* s = a-userdefined;
char* t = b-userdefined;
char param[BUFSIZE];
strcpy(param, kernel_parm-custom);
...
}
SVMlight で文字列カーネルを実装してみたい!
-1 #おぉ、SVMlightのデータ形式のうち、コメントの情報が格納されるのか!
-1 #こんなこと書くぐらいならspectrum kernelぐらい組み込んどいてほしい。
kernel.h ( kernel.c として Makefile をいじってもいい)
# コマンド引数で -u “parameters” と指定した内容が格納されている
データサンプル ハッシュ以下の内容が SVECTOR-userdefined に格納される](https://image.slidesharecdn.com/stringkernelupload-110910001058-phpapp01/85/slide-53-320.jpg)








![[DL輪読会]Deep Learning 第2章 線形代数](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearningchapter2-180601014406-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Attention Is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks170714-170714005330-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)



![[論文紹介] LSTM (LONG SHORT-TERM MEMORY)](https://cdn.slidesharecdn.com/ss_thumbnails/2018-181019021803-thumbnail.jpg?width=640&height=640&fit=bounds)










































