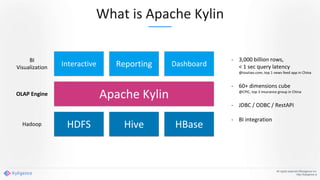
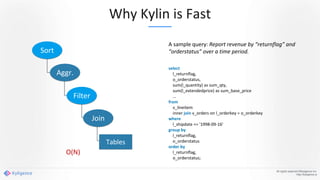
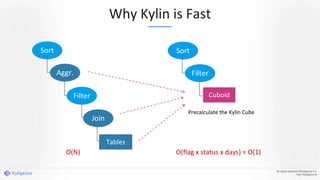
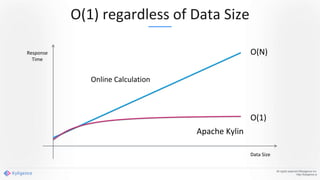
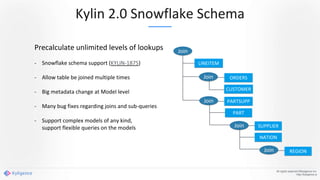
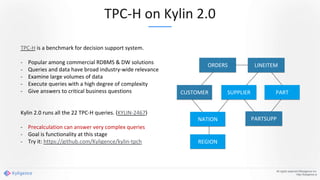
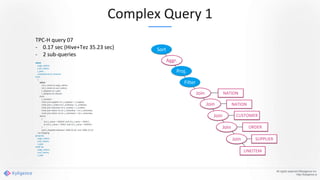
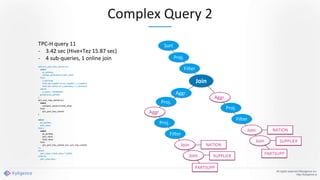
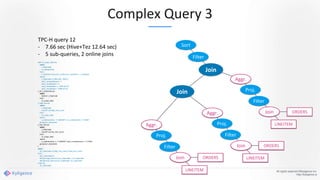
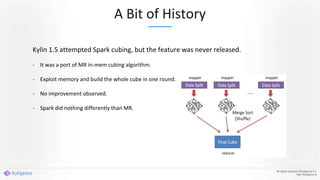
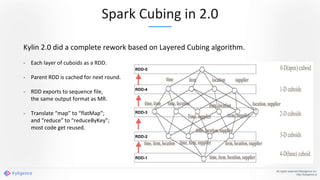
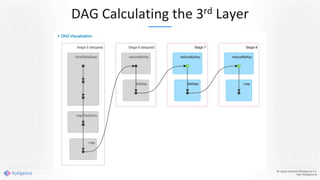
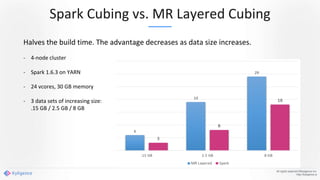
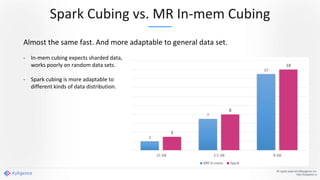
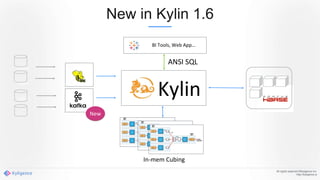
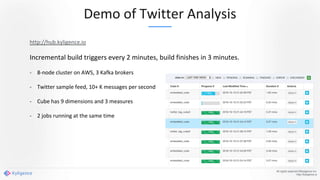
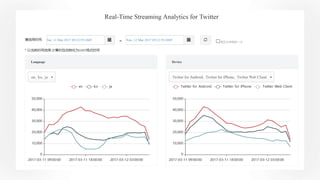
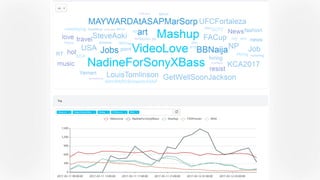
Apache Kylin 2.0 introduces enhancements for a real-time data warehouse, supporting complex queries and snowflake schemas while improving query performance through precalculation. The platform runs TPC-H benchmarks, showing significant query speed improvements compared to traditional systems. Key features include support for incremental builds, spark cubing, and the ability to process large data volumes with reduced latency.