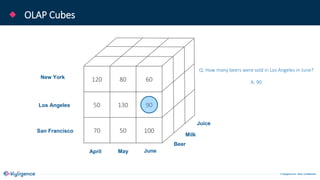
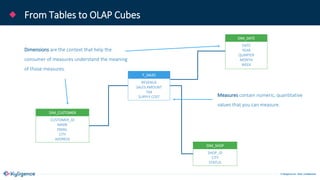
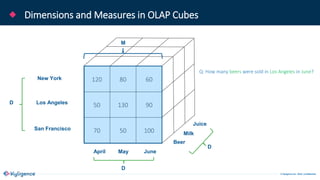
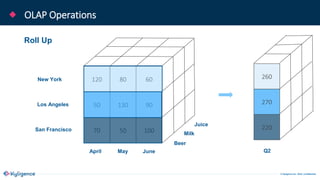
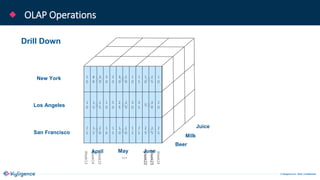
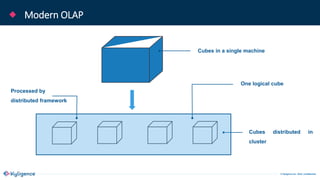
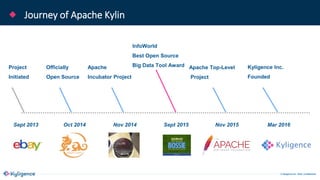
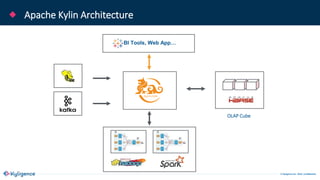
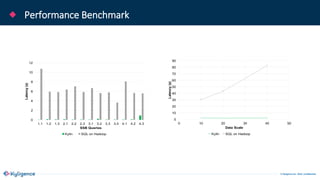
The document provides an overview of Apache Kylin, an OLAP engine designed for big data analytics, highlighting its strengths in handling massive volumes of data and quick querying capabilities. It details the differences between traditional OLAP tools and modern solutions like Apache Kylin, which addresses scalability and performance issues. Additionally, it outlines a four-step process for building a Kylin cube and mentions future enhancements planned for the platform.