Download to read offline



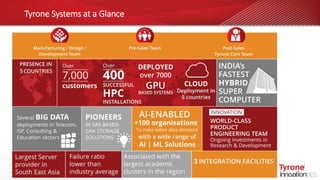














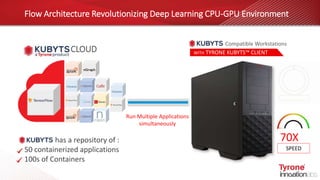




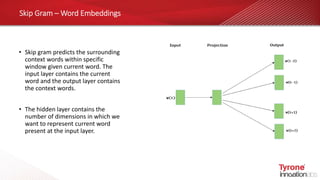
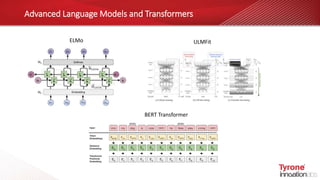
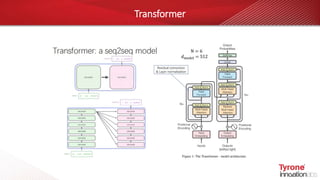





This document contains an agenda for a webinar on the age of language models in NLP. The agenda includes discussions on word embeddings, sequence modeling, advanced language models like BERT and Transformers, attention mechanisms, and case studies. It also provides overviews of Tyrone systems' high-performance AI platform using NVIDIA A100 GPUs and its Tyrone Kubyts technology for revolutionizing deep learning environments.








































![[DSC Europe 24] Thomas Kitzler - Building the Future – Unpacking the Essentia...](https://cdn.slidesharecdn.com/ss_thumbnails/thomaskitzler-241220214738-670777be-thumbnail.jpg?width=640&height=640&fit=bounds)








































