More Related Content
![[DL輪読会]Diffusion-based Voice Conversion with Fast Maximum Likelihood Samplin...](https://cdn.slidesharecdn.com/ss_thumbnails/20220318akuzawa-220322065615-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Diffusion-based Voice Conversion with Fast Maximum Likelihood Samplin... 
PDF
環境音の特徴を活用した音響イベント検出・シーン分類 
PDF
音声感情認識の分野動向と実用化に向けたNTTの取り組み 
PDF
Neural text-to-speech and voice conversion 
PDF
クラシックな機械学習入門:付録:よく使う線形代数の公式 
PPTX
音源分離における音響モデリング(Acoustic modeling in audio source separation) 
PDF

PDF
J-KAC:日本語オーディオブック・紙芝居朗読音声コーパス What's hot

PDF
Transformerを多層にする際の勾配消失問題と解決法について 
PPTX
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料) 
PDF
![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]When Does Label Smoothing Help? 
PDF
【メタサーベイ】Video Transformer 
PDF

PDF
![[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...](https://cdn.slidesharecdn.com/ss_thumbnails/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe... 
PDF

PDF
![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて- 
PDF

PDF

PPTX

PDF

ODP

PPTX
独立性に基づくブラインド音源分離の発展と独立低ランク行列分析 History of independence-based blind source sep... 
PDF
z変換をやさしく教えて下さい (音響学入門ペディア) 
PDF
やさしく音声分析法を学ぶ: ケプストラム分析とLPC分析 
PDF
リアルタイムDNN音声変換フィードバックによるキャラクタ性の獲得手法 More from Shinnosuke Takamichi

PDF
短時間発話を用いた話者照合のための音声加工の効果に関する検討 
PDF
ここまで来た&これから来る音声合成 (明治大学 先端メディアコロキウム) 
PDF
JTubeSpeech: 音声認識と話者照合のために YouTube から構築される日本語音声コーパス 
PDF

PDF
テキスト音声合成技術と多様性への挑戦 (名古屋大学 知能システム特論) 
PDF

PDF

PDF
差分スペクトル法に基づく DNN 声質変換の計算量削減に向けたフィルタ推定 
PDF
論文紹介 Unsupervised training of neural mask-based beamforming 
PDF

PDF
P J S: 音素バランスを考慮した日本語歌声コーパス 
PDF
話者V2S攻撃: 話者認証から構築される 声質変換とその音声なりすまし可能性の評価 
PDF
Interspeech 2020 読み会 "Incremental Text to Speech for Neural Sequence-to-Sequ... 
PDF
End-to-end 韻律推定に向けた DNN 音響モデルに基づく subword 分割 
PDF
音響モデル尤度に基づくsubword分割の韻律推定精度における評価 
PDF
論文紹介 Building the Singapore English National Speech Corpus 
PDF
ユーザ歌唱のための generative moment matching network に基づく neural double-tracking 
PDF
論文紹介 SANTLR: Speech Annotation Toolkit for Low Resource Languages 
PDF
音声合成・変換の国際コンペティションへの 参加を振り返って 
PDF
サブバンドフィルタリングに基づくリアルタイム広帯域DNN声質変換の実装と評価 Recently uploaded

PDF
maisugimoto_曖昧さを含む仕様書の改善を目的としたアノテーション支援ツールの検討_HCI2025.pdf 
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研) 
PDF
20260119_VIoTLT_vol22_kitazaki_v1___.pdf 
PDF
TomokaEdakawa_職種と講義の関係推定に基づく履修支援システムの基礎検討_HCI2026 
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf 
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S... 音声合成のコーパスをつくろう
- 1.
- 2.
- 3.
- 4.
AVATAR SYMBIOTIC
SOCIETY
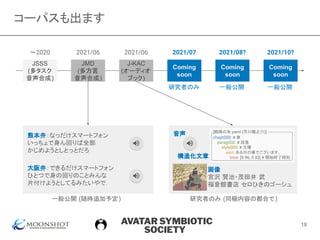
色んなコーパスを作って公開してきました
(コーパス =音声データベース)
JSUT
(音声合成)
JSUT-song
(歌声合成)
JVS
(多話者
音声変換)
JVS-MuSiC
(多歌唱者
歌声合成)
PJS
(音声歌声
変換)
JSSS
(多タスク
音声合成)
北岡 他: “フォトリアルCGエー
ジェントとの マルチモーダル対
話システムの構築,” 音響学会
春, 2021.
(事前学習に利用)
https://twitter.com/SHA
CHI_NEUTRINO/status
/127207370729745203
2?s=20
https://twitter.com/hiho_karuta
/status/122826647470951219
4?s=20
https://github.com/espnet/espnet
2017 2018 2019 2020
音声処理オープンソース
ESPnet
CGエージェント
SAYA
歌声合成エンジン
NEUTRINO
ボイスチェンジャー
Seiren Voice
4
- 5.
- 6.
- 7.
- 8.
- 9.
AVATAR SYMBIOTIC
SOCIETY
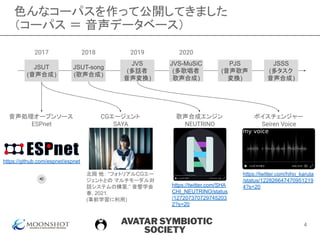
世界の音声合成コーパス事情:
最近の国際会議では
9
コーパス名 言語サイズ[時間]
LibriTTS [Zen19] 英語 585 (多話者)
Hi-Fi TTS [Bakhturina21] 英語 292 (多話者)
CSMSC [China17] 中国語 12
DiDiSpeech [Guo21] 中国語 800 (多話者)
RUSLAN [Gabdrakhmanov19] ロシア語 31
IndicSpeech [Srivastava20] ベンガル語など 22
KSS dataset [Park20] 韓国語 12
この2~3年で,主要言語の音声合成コーパスがだいぶ整備されてきた
- 10.
- 11.
- 12.
- 13.
AVATAR SYMBIOTIC
SOCIETY
音声コーパスを作ろう
• タスクによってコーパスの条件が違う(将来的には共通になる)
• 音声認識 … 少人数より多人数,クリーン環境より実環境
• 音声合成 … 多人数より少人数,実環境よりクリーン環境
•
• 必要な役割
• 前準備:設計者
• 音声収録:話者,音響エンジニア,音響監督
• 後処理:アノテータ
•
• 音声収録は,基本的にプロに依頼したほうが良いです
• プロはすごい.自分でやると質の悪さに絶望する.
• 音声収録の基本技術は本を参考にして下さい
• アナウンス教本やPA技術書など
13
- 14.
AVATAR SYMBIOTIC
SOCIETY
朗読内容を決めよう
• 設計者として
•誰がどんなスタイルで読む?
• ある意味で一番大事
• 一昔前より,話者の声色と音声技術の相性問題はだいぶ緩和
•
• 何のテキストをどれくらい読む?
• 10分前後 … ちょっと少なめ (すごい転移学習が必要)
• 1時間 … いい感じ (ふつうの転移学習が必要)
• 10時間 … すごい (転移学習なしでもイケる)
•
• 既存のテキスト (多いほど良い)
• 声優統計コーパス100文 … 15分前後
• ITAコーパス330文 … 30分前後
• JSUTコーパス basic5000 … 6時間
● 参考:日本語の話速はひらがな 5~7文字/秒
● JSUTコーパスなどでモデルを事前学習する前提
14
- 15.
AVATAR SYMBIOTIC
SOCIETY
録音しよう
• 話者として
•求められている内容に即して発話することが大事
• リップノイズ,ポップノイズ,椅子の音などを避ける
•
• 音響エンジニアとして
• コンデンサマイク (1~3万円で十分),オーディオインターフェース
• 騒音源の除去,遮音材の設置
• 動作させると騒音源になるものもあるので注意 (PCとか)
•
• 音響監督として
• 発音やアクセントは正しい?
• NHKアクセント新辞典は必需品
• 1日4時間収録,1時間に10分休憩,録れ高は収録時間の⅛ ~ ¼前後
• 例: JSUT (素人10時間) を週2.5日ペースで収録すると8週間
15
- 16.
- 17.
- 18.
- 19.
- 20.



![AVATAR SYMBIOTIC
SOCIETY
最近は,人間と音声合成技術の融合が好き
自然に間違う音声・歌声合成 [Tamaru20]
“自分で聞く自分の声 ”をキャラに変えると
そのキャラの演技がうまくなる [Kurata21]
人間を騙して学習される “人間GAN” [Ueda21]
リアルタイムなりきり
ボイスチェンジャー [Arakawa19]
* 演出の都合上,意図的に遅延させています.
最新版[Saeki21]は48kHz, 20msec遅延で変換
3](https://image.slidesharecdn.com/takamichi21tokyobishbashcorpus1-210623143749/85/slide-3-320.jpg)




![AVATAR SYMBIOTIC
SOCIETY
世界の音声合成コーパス事情:
最近の国際会議では
9
コーパス名 言語 サイズ[時間]
LibriTTS [Zen19] 英語 585 (多話者)
Hi-Fi TTS [Bakhturina21] 英語 292 (多話者)
CSMSC [China17] 中国語 12
DiDiSpeech [Guo21] 中国語 800 (多話者)
RUSLAN [Gabdrakhmanov19] ロシア語 31
IndicSpeech [Srivastava20] ベンガル語など 22
KSS dataset [Park20] 韓国語 12
この2~3年で,主要言語の音声合成コーパスがだいぶ整備されてきた](https://image.slidesharecdn.com/takamichi21tokyobishbashcorpus1-210623143749/85/slide-9-320.jpg)

![AVATAR SYMBIOTIC
SOCIETY
日本のコーパス事情
最近の国内会議では
11
コーパス名 ドメイン サイズ[時間]
JSUT [Sonobe17] 話声 10
JVS [Takamichi19] 話声 30 (多話者)
ITA [Koguchi21] 話声 0.5
JSUT-song [Takamichi18] 歌声 0.5
LJSong [Fujimura21] 歌声 5
PJS [Koguchi20] 歌声 0.5
国内だと,東京大学,東北大学,明治大学あたりが頑張っている](https://image.slidesharecdn.com/takamichi21tokyobishbashcorpus1-210623143749/85/slide-11-320.jpg)