












![--wsrep-recover
MySQL stores last committed GTID in InnoDB data
header, transactionally
●
This GTID can be read by starting mysqld with
–wsrep-recover option
●
<path to bin>/mysqld
–wsrep-recover –defaults- le=<path to my.cnf>
●
Mysqld will read InnoDB header les and shutdown immediately
●
Last wsrep position is printed in mysql error le
130514 18:39:13 [Note] WSREP: Recovered position: 5ee99582-bb8d-11e2-b8e3-23de375c1d30:8204503945771
www.codership.com
21](https://image.slidesharecdn.com/galeranoderecoverywebinarslides-140121055603-phpapp02/85/Galera-Cluster-Node-Recovery-Webinar-slides-21-320.jpg)



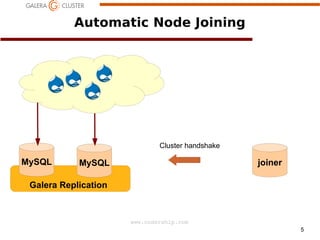
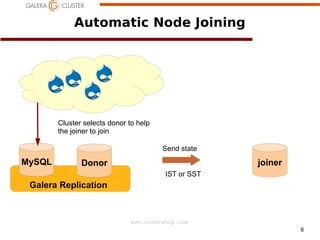
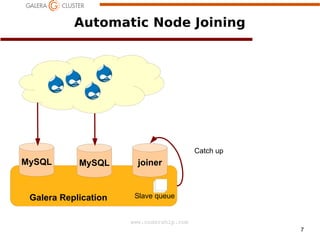
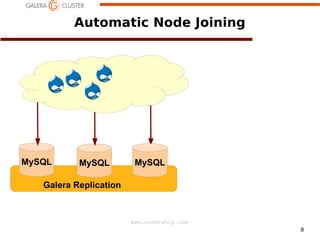
The document discusses node recovery scenarios in a Galera cluster, covering methods like Incremental State Transfer (IST) and State Snapshot Transfer (SST). It outlines procedures for both node recovery after crashes and full cluster recovery, including identifying the latest node changes and bootstrapping a new cluster. Key technical specifications, such as gcache parameters and wsrep recovery options, are highlighted to optimize the recovery process.






![[135] 오픈소스 데이터베이스, 은행 서비스에 첫발을 내밀다.](https://cdn.slidesharecdn.com/ss_thumbnails/35-171016061446-thumbnail.jpg?width=640&height=640&fit=bounds)
















































































