Download as PDF, PPTX























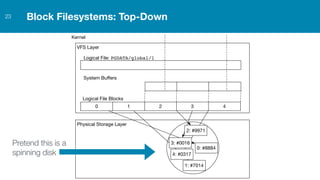





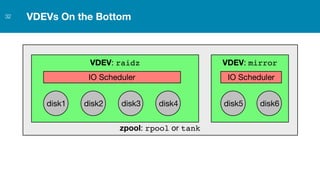
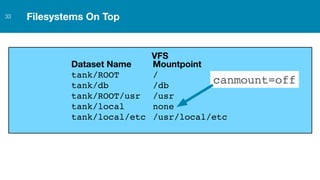
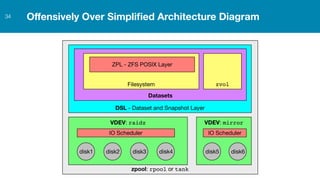


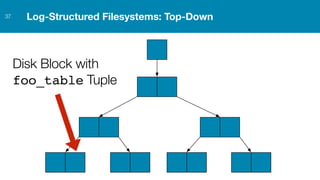
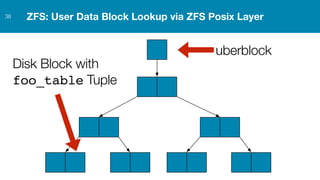
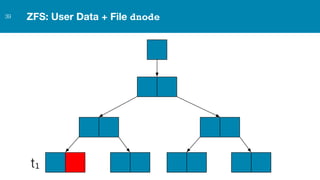
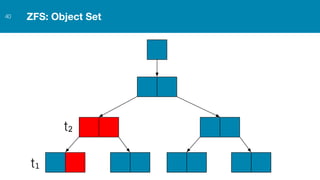
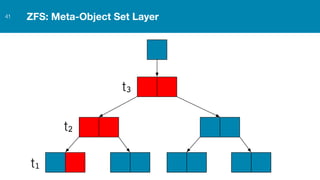
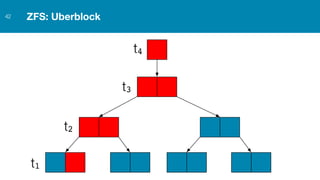
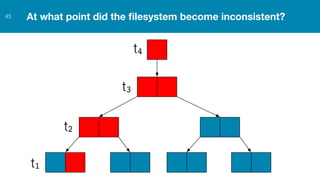



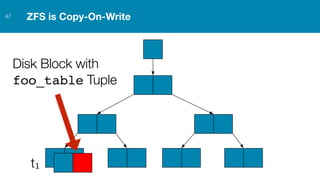
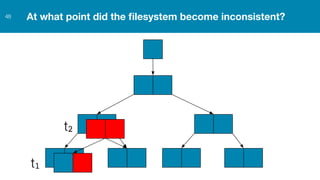
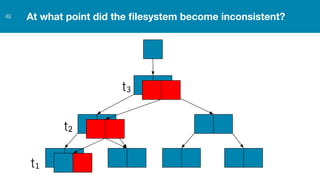
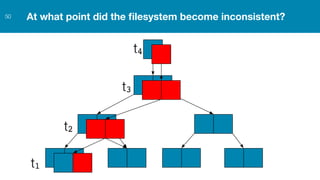




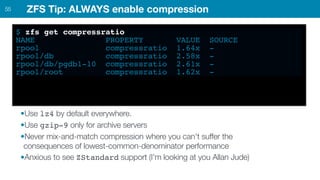
















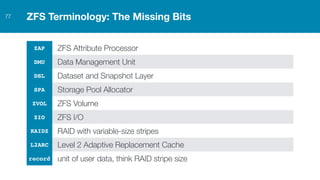
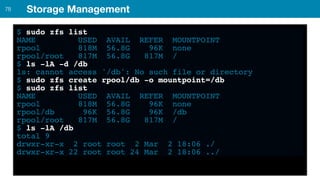


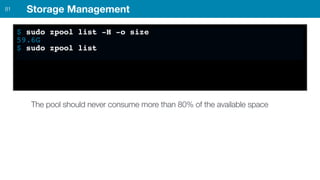
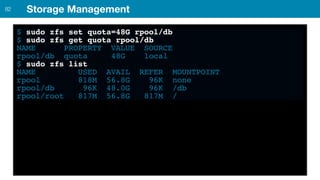

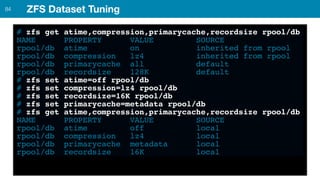



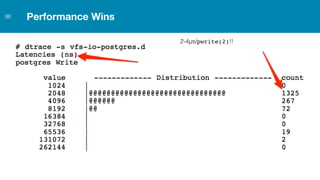
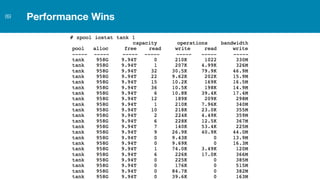
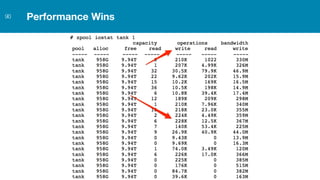
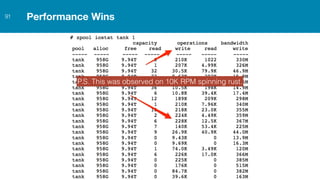

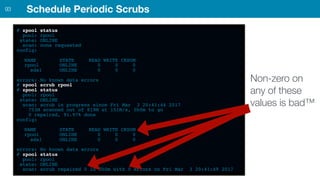

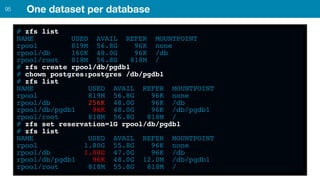
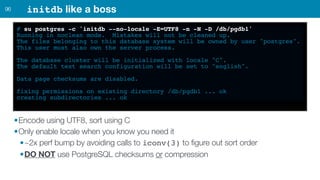
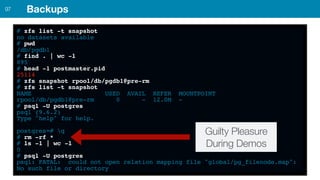
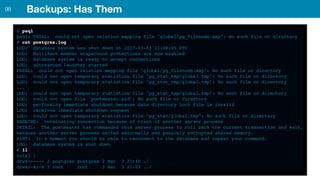
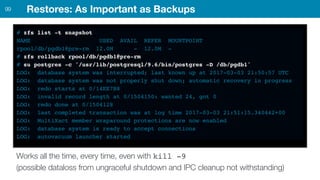
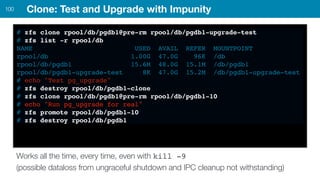


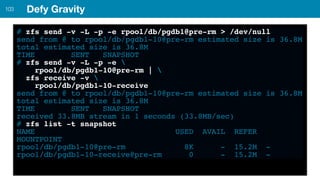

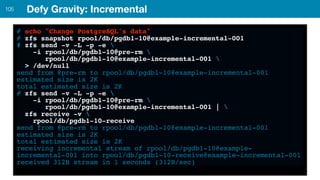
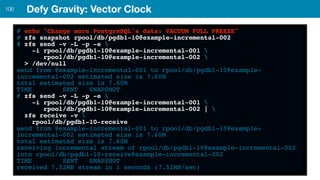
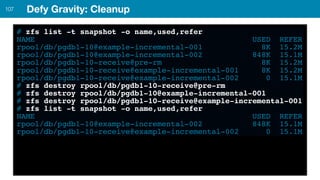

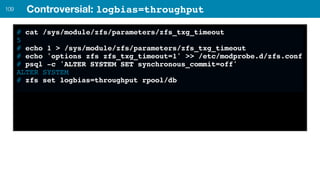


ZFS provides several advantages over traditional block-based filesystems when used with PostgreSQL, including preventing bitrot, improved compression ratios, and write locality. ZFS uses copy-on-write and transactional semantics to ensure data integrity and allow for snapshots and clones. Proper configuration such as enabling compression and using ZFS features like intent logging can optimize performance when used with PostgreSQL's workloads.




























































