Download as PDF, PPTX




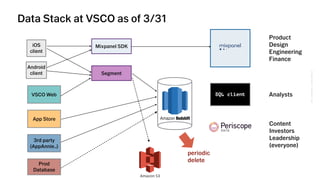
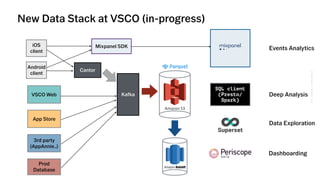


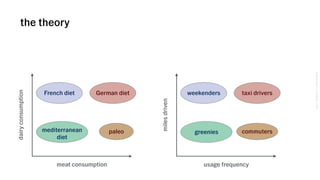
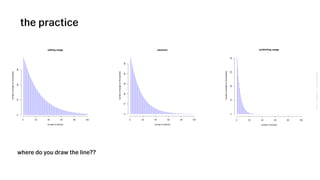


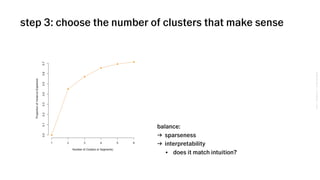


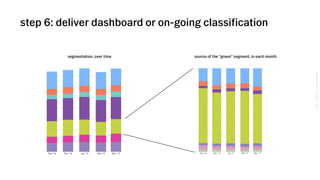




The document outlines VSCO's user segmentation strategy, highlighting their audience demographics and engagement metrics, such as their 41 million monthly users and the tools available for both marketing and design purposes. It details a six-step process for conducting clustering analysis to understand user behavior and improve targeting, including choosing inputs, log transforming data, and programmatic cohort tracking. The approach integrates insights from marketers, designers, and analysts, emphasizing the importance of behavioral data for effective segmentation.

























































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)









