Downloaded 13 times













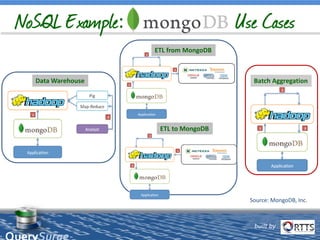



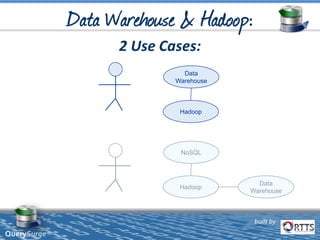

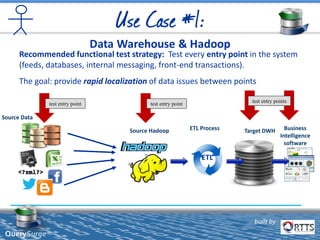
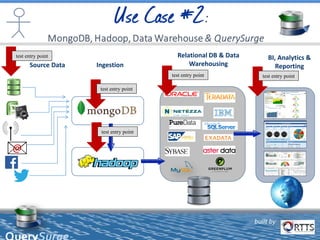




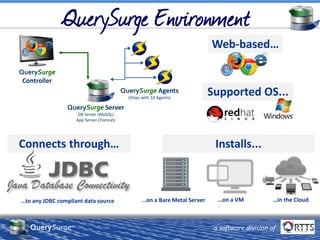
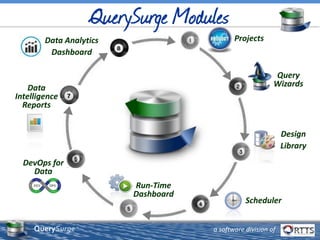


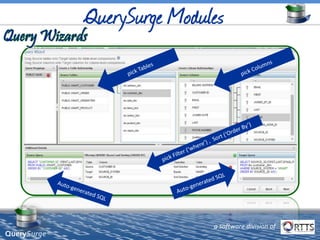
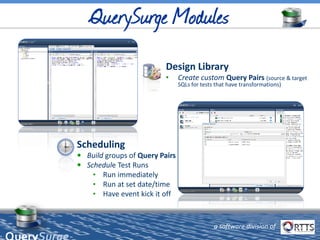



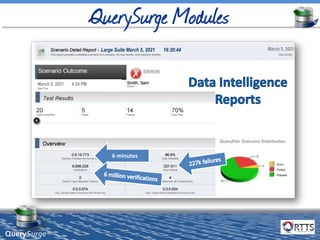


The document discusses automated ETL testing for big data using QuerySurge, a software by RTTS, highlighting its capabilities in handling Hadoop and NoSQL technologies. It outlines the complexities of big data and advocates for the need for effective testing solutions to ensure data quality and reliability. The content also includes details on the functionalities of QuerySurge, its development history, and its integration with various platforms for continuous testing.



![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)