Download as PDF, PPTX



























![[
{
"@id":"http://example.com/a0",
"http://example.com/follows":[
{
"@id":"http://example.com/c0"
},
{
"@id":"http://example.com/b0"
}
],
"http://example.com/name":[
{
"@value":"Adam"
}
]
},
{
"@id":"http://example.com/b0",
"http://example.com/follows":[
{
"@id":"http://example.com/a0"
}
],
"http://example.com/name":[
Real RDF serialisations - JSON-LD
"@value":"Bill"
}
]
},
{
"@id":"http://example.com/b1",
"http://example.com/name":[
{
"@value":"Bill"
}
]
},
{
"@id":"http://example.com/c0",
"http://example.com/name":[
{
"@value":"Cindy"
}
],
"http://example.com/follows":[
{
"@id":"http://example.com/b1"
}
]
}
]](https://image.slidesharecdn.com/introductiontographdatabases-200616094849/85/Introduction-to-Graph-Databases-27-320.jpg)





























![RDF triples are often shown in Turtle syntax (https://www.w3.org/TR/turtle/).
Turtle syntax contains more legible abbreviations for blank nodes.
In this example, _:b is a blank node.
ex:a0 ex:hasAddress _:b .
_:b ex:town “London” .
_:b ex:street “Baker Street” .
_:b ex:postCode “ W1U 6TL” .
These four triples can be formatted in a more legible way as follows:
ex:a0 ex:hasAddress [
ex:town “London” ;
ex:street “Baker Street” ;
ex:postCode “ W1U 6TL” ] .
The RDF Turtle Syntax](https://image.slidesharecdn.com/introductiontographdatabases-200616094849/85/Introduction-to-Graph-Databases-58-320.jpg)



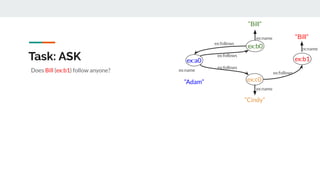

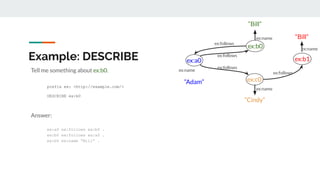







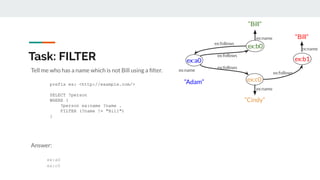











































This document serves as a tutorial on graph databases, focusing on the RDF data model and SPARQL query language. It introduces essential concepts, installation instructions for required software, and explanations of graph representations, including nodes, edges, and IRIs. The tutorial emphasizes the advantages of using RDF for data integration and representation in comparison to relational databases.



































































