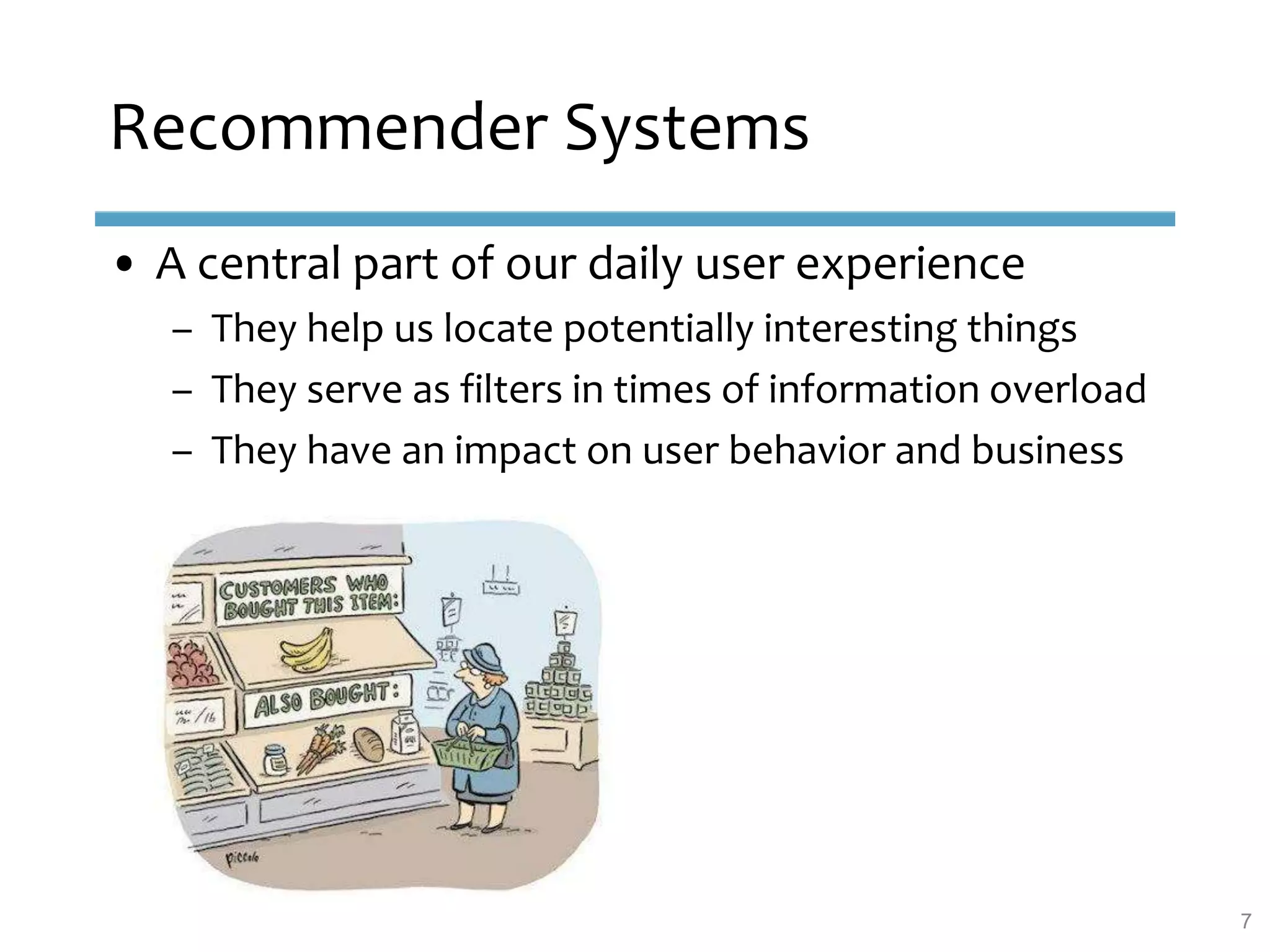
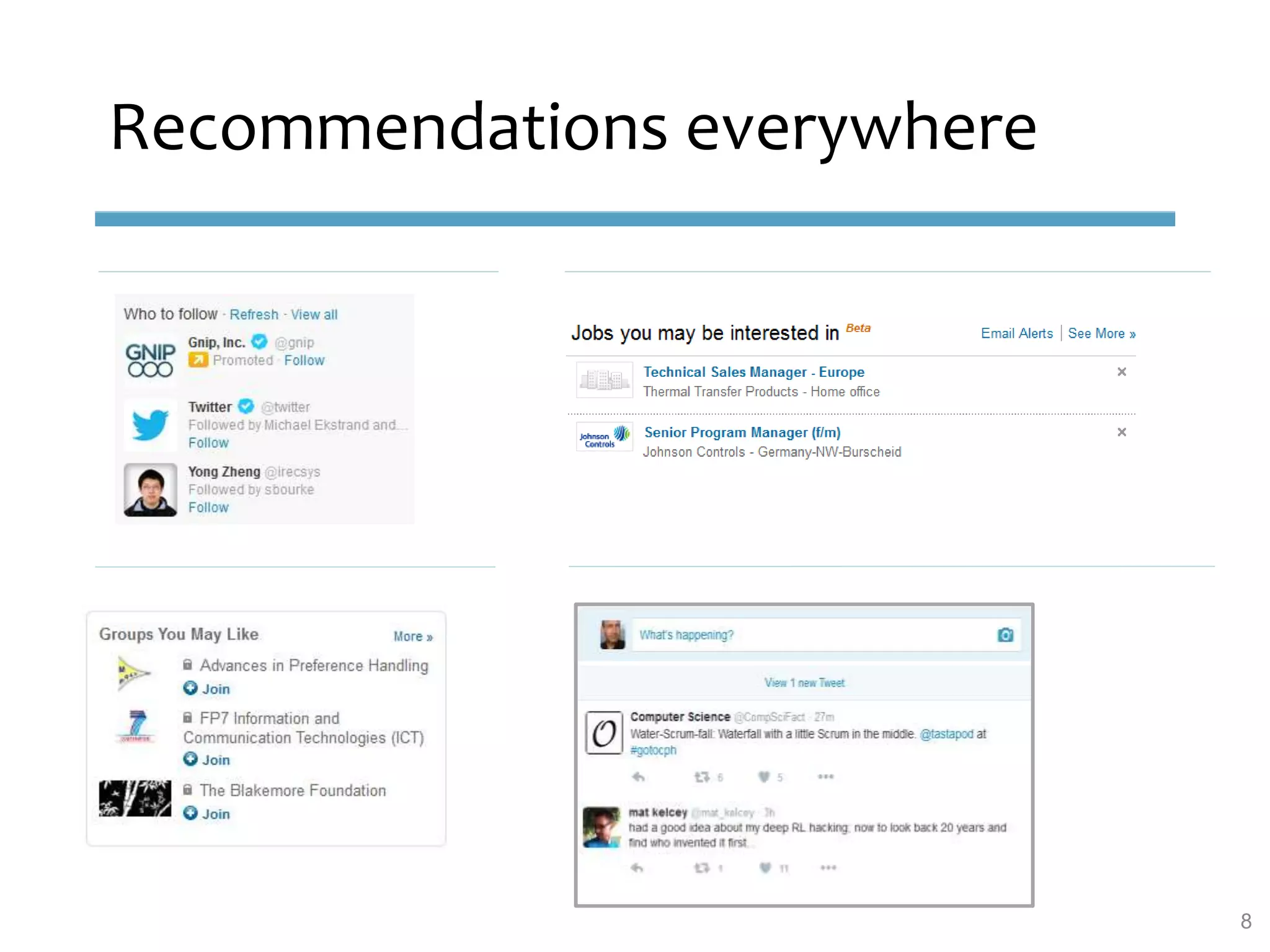
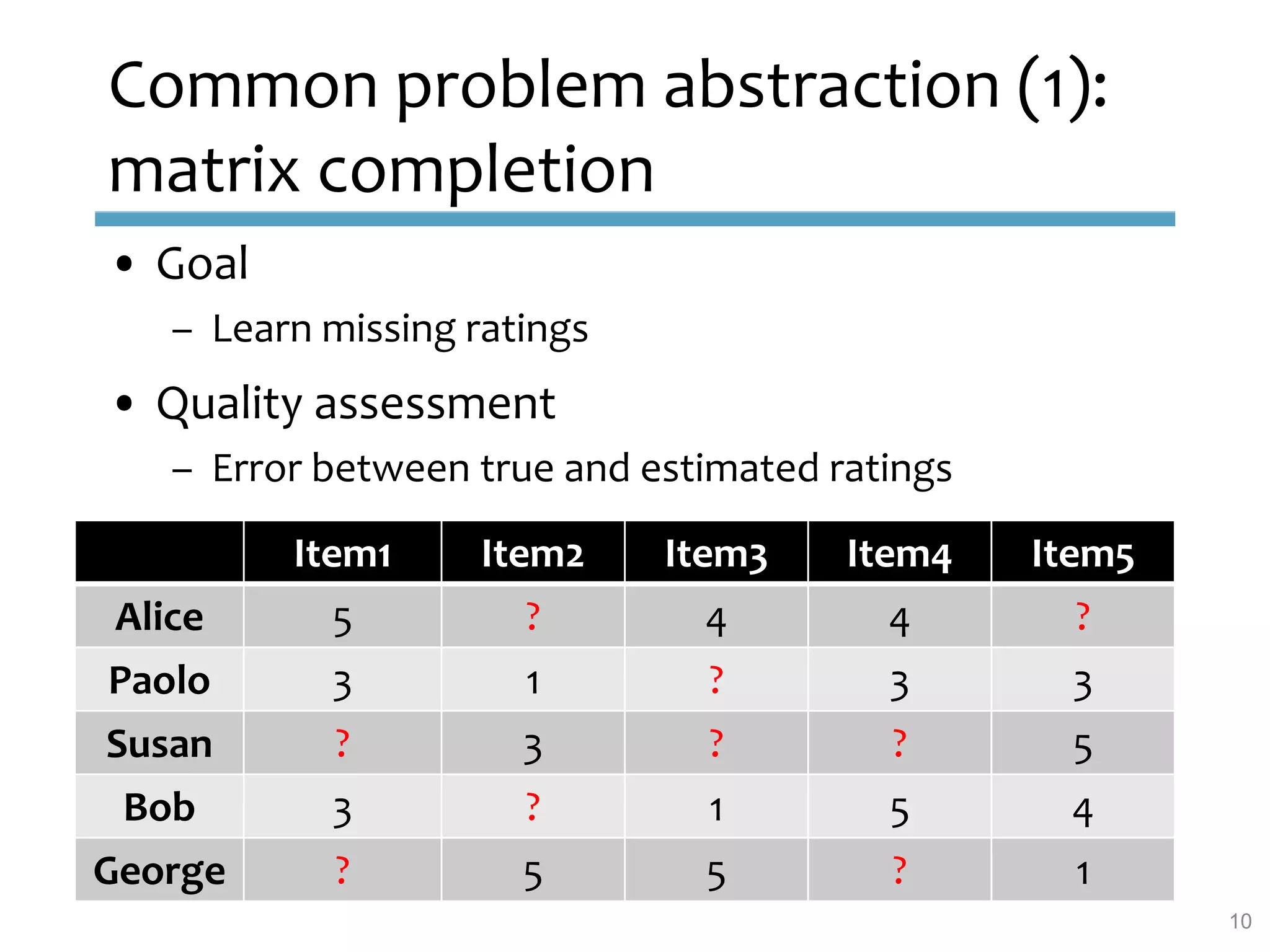
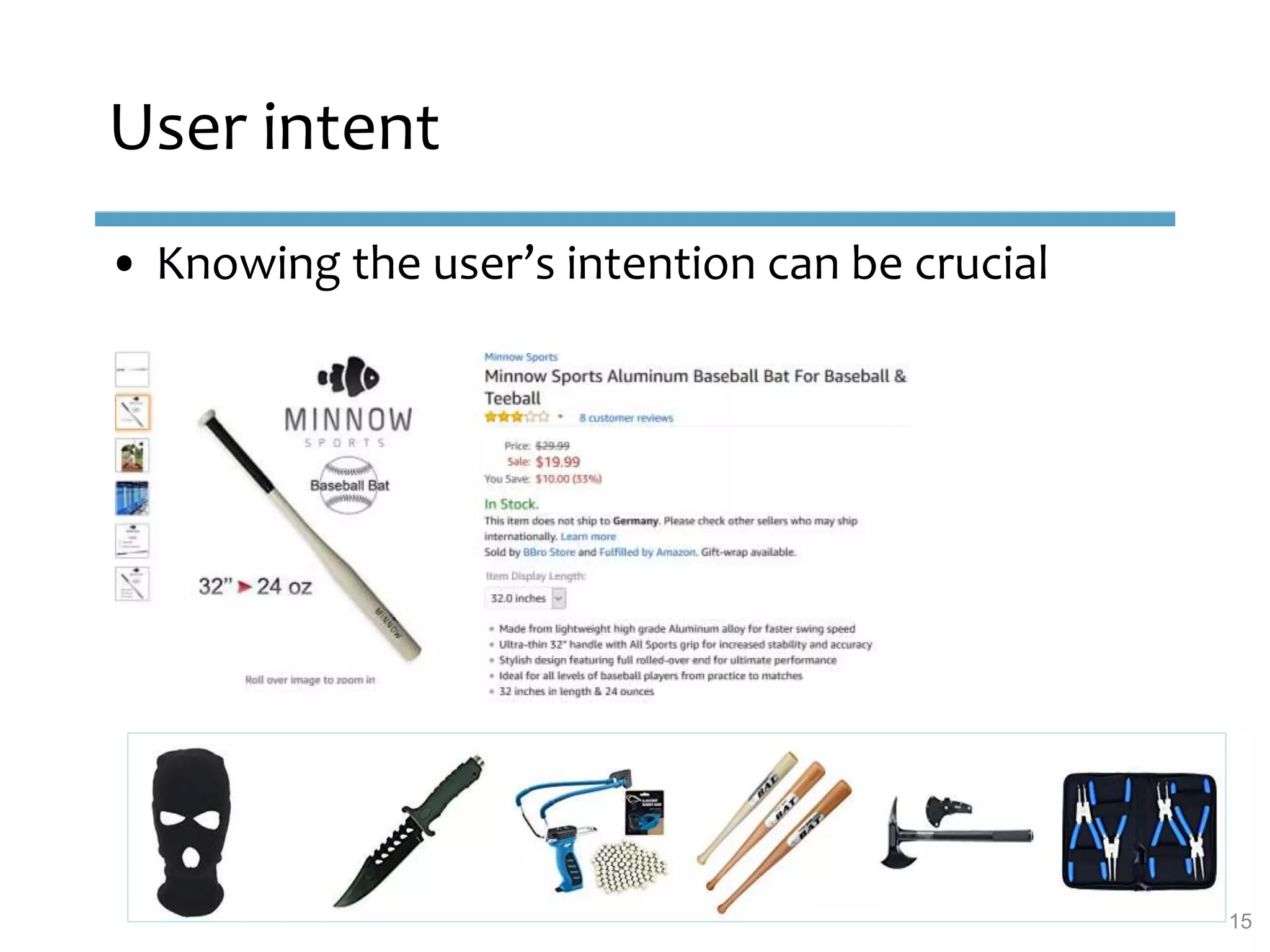
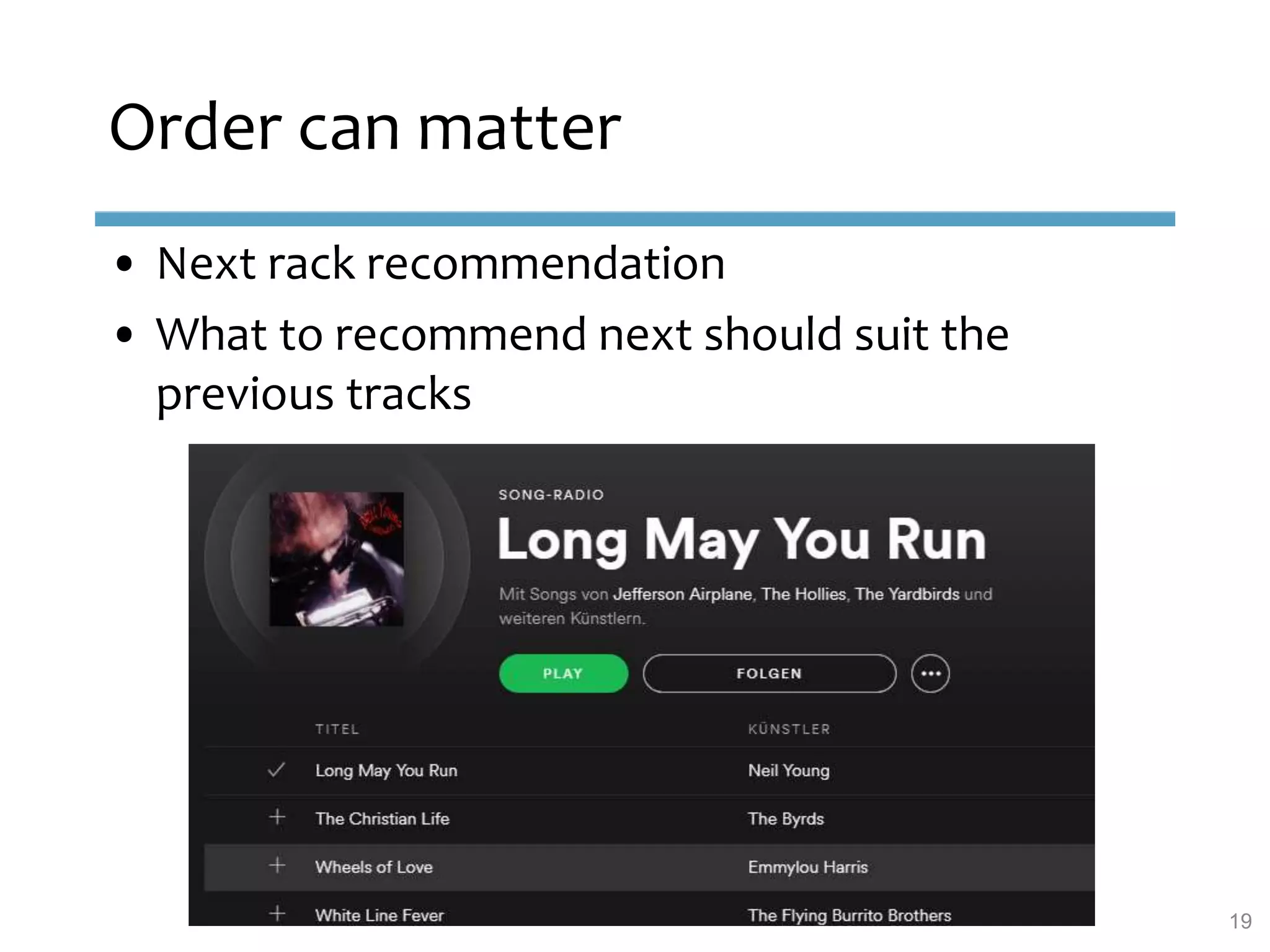
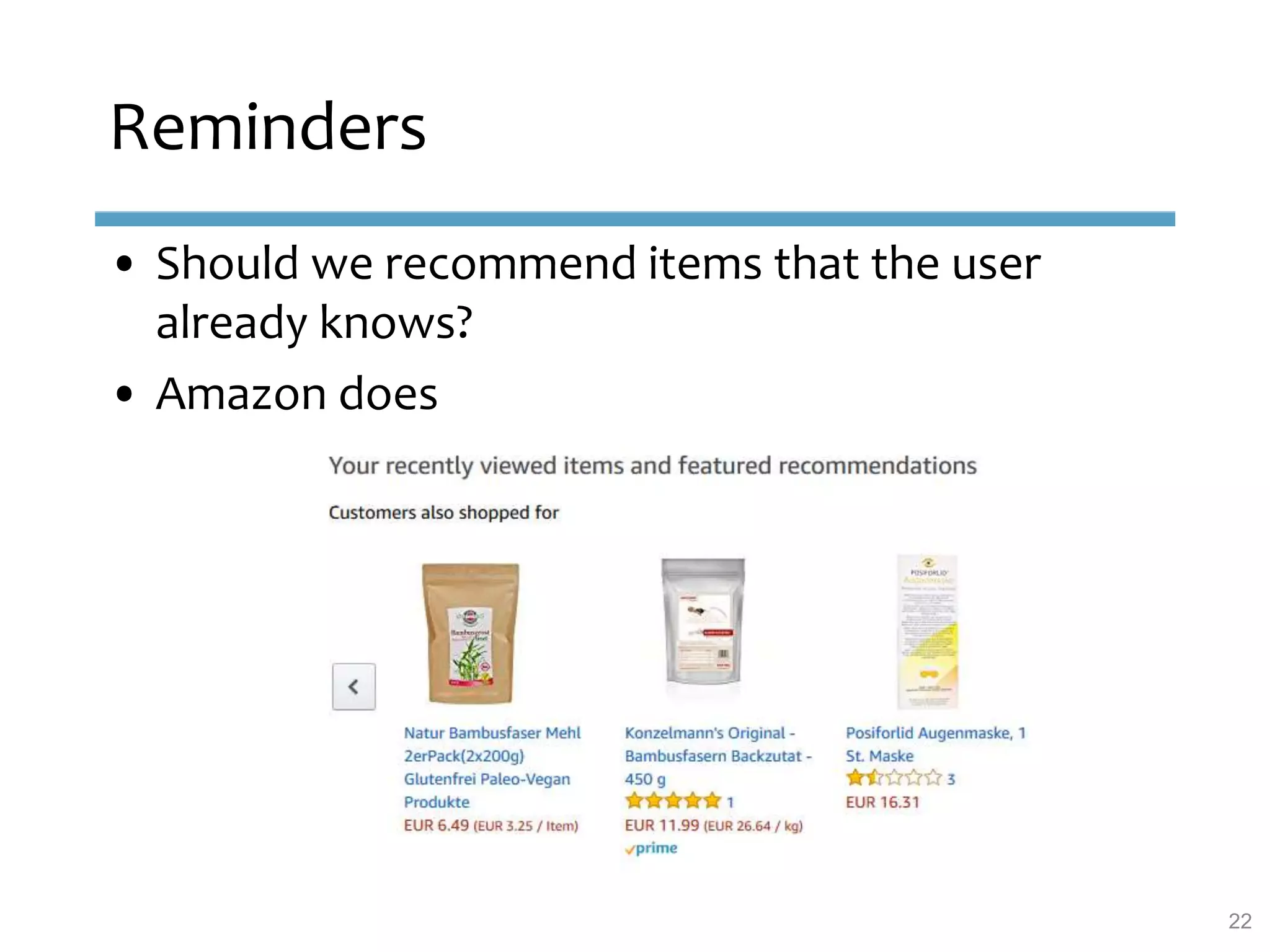
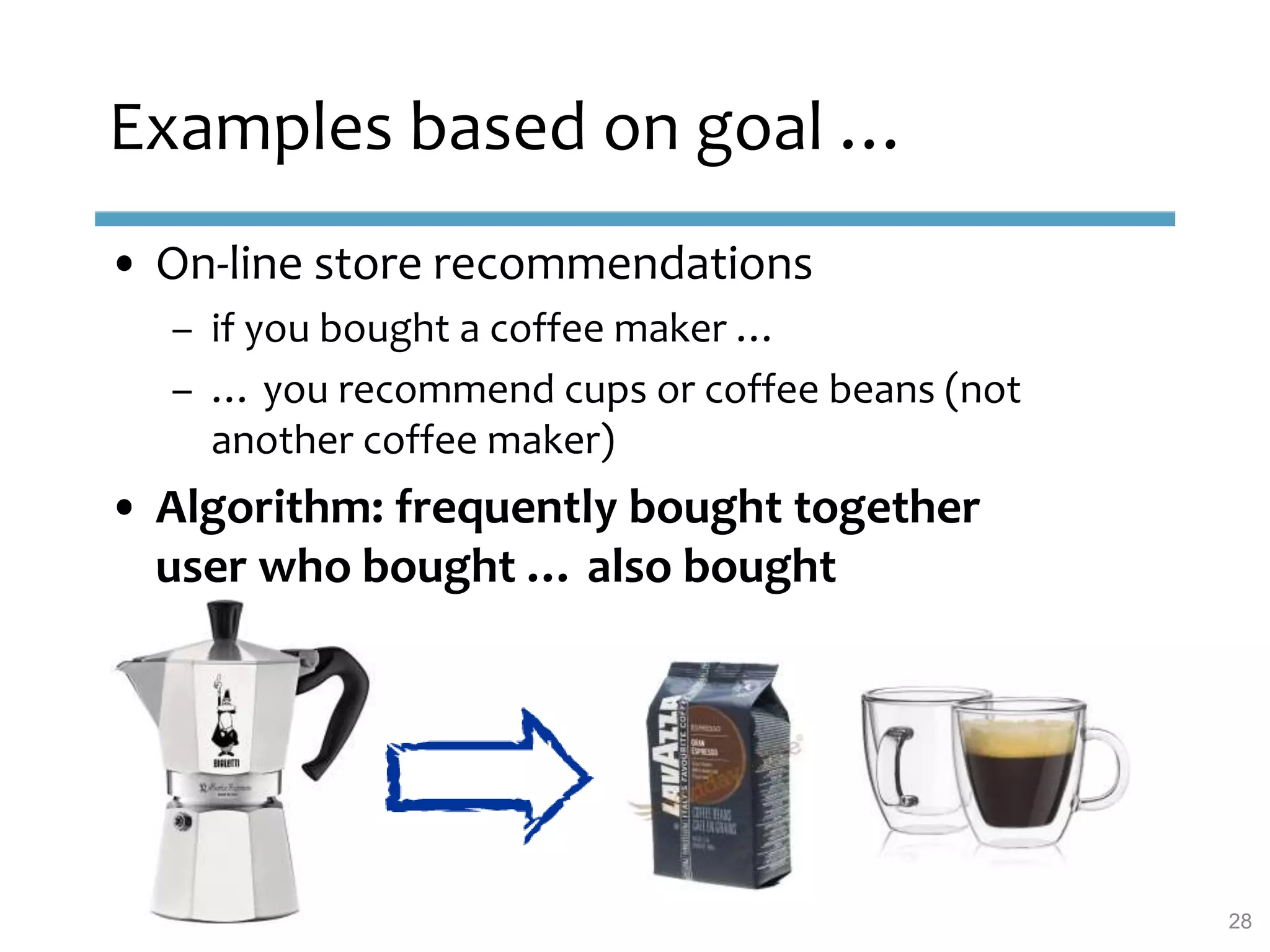
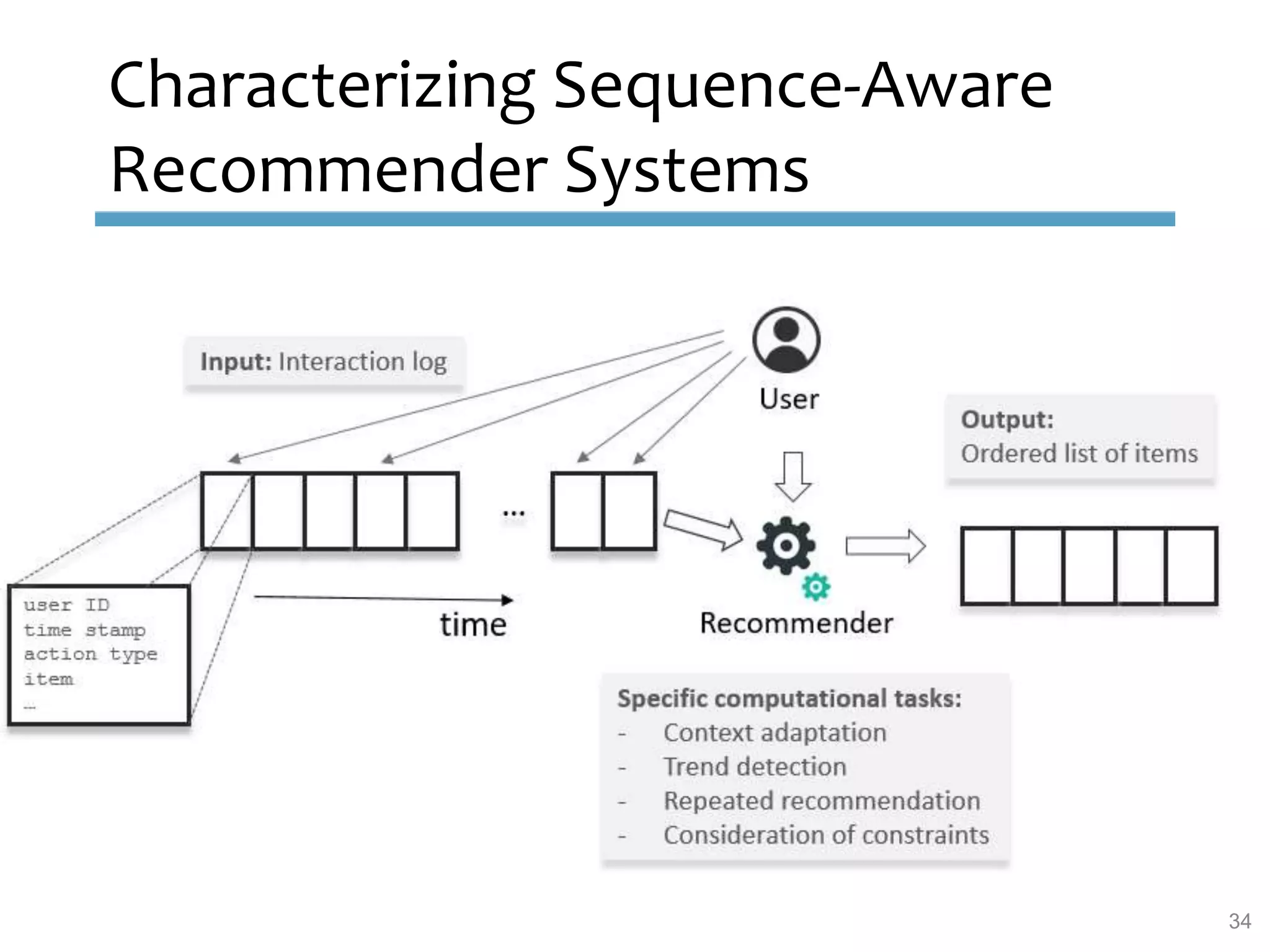
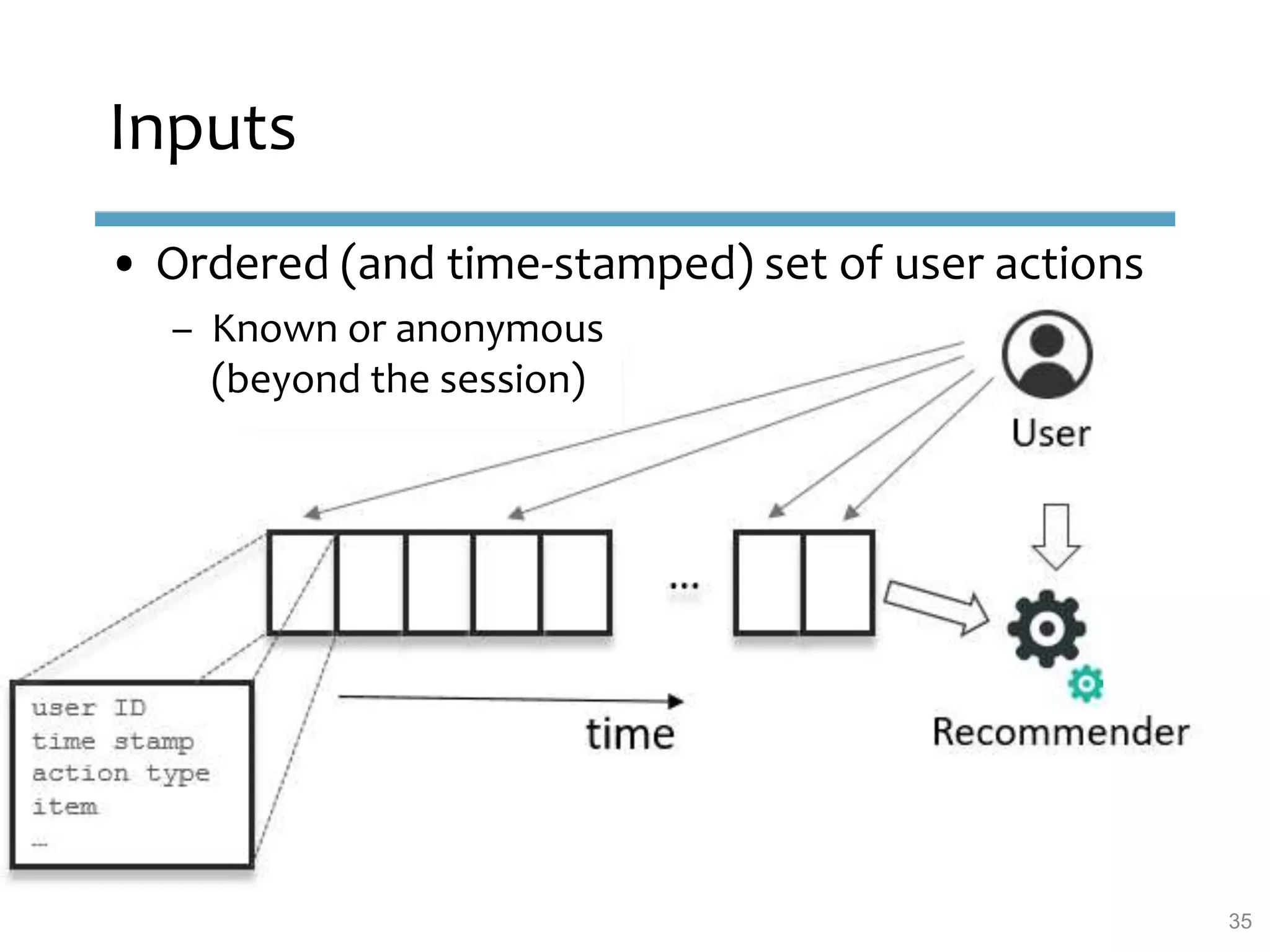
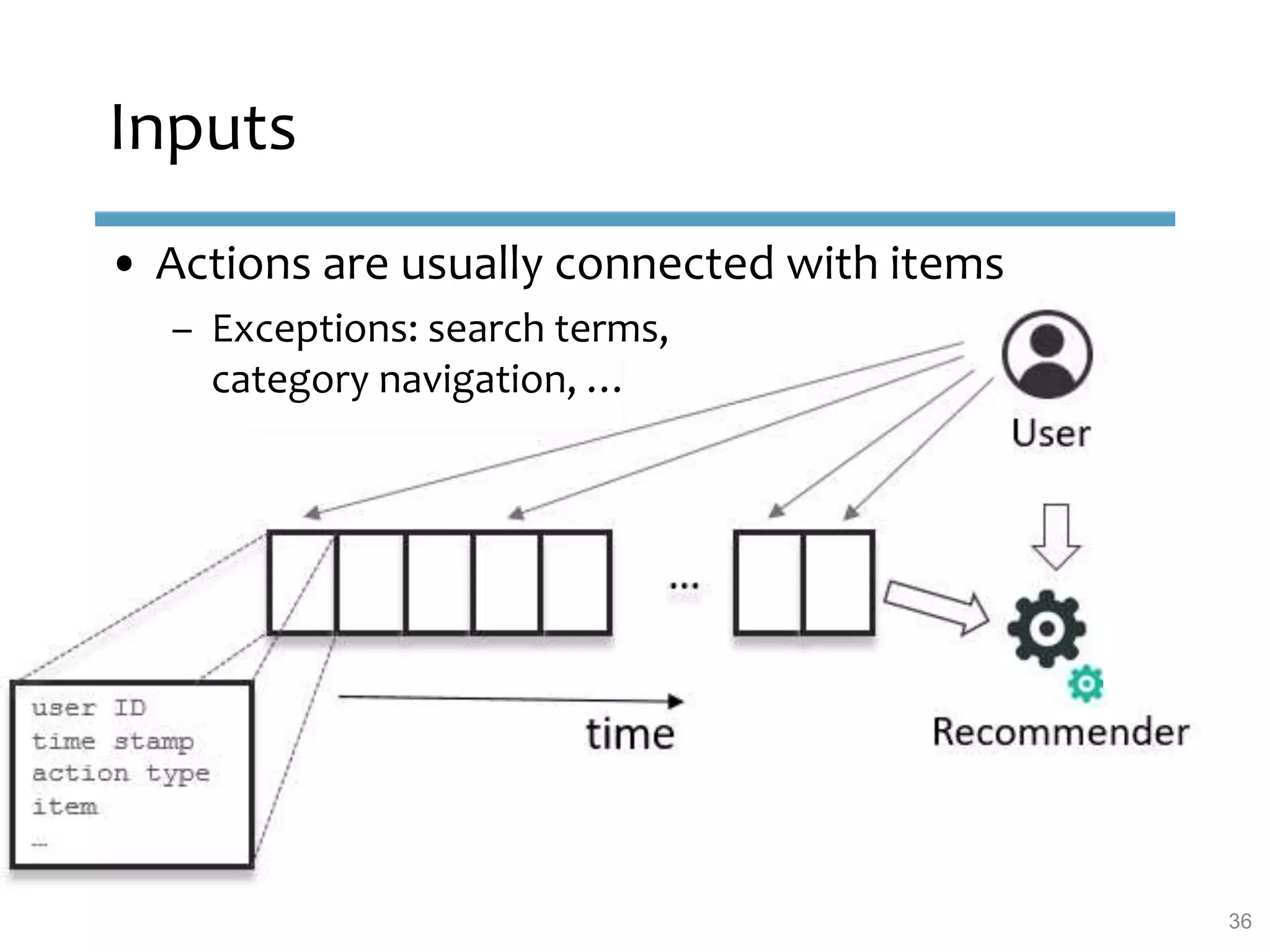
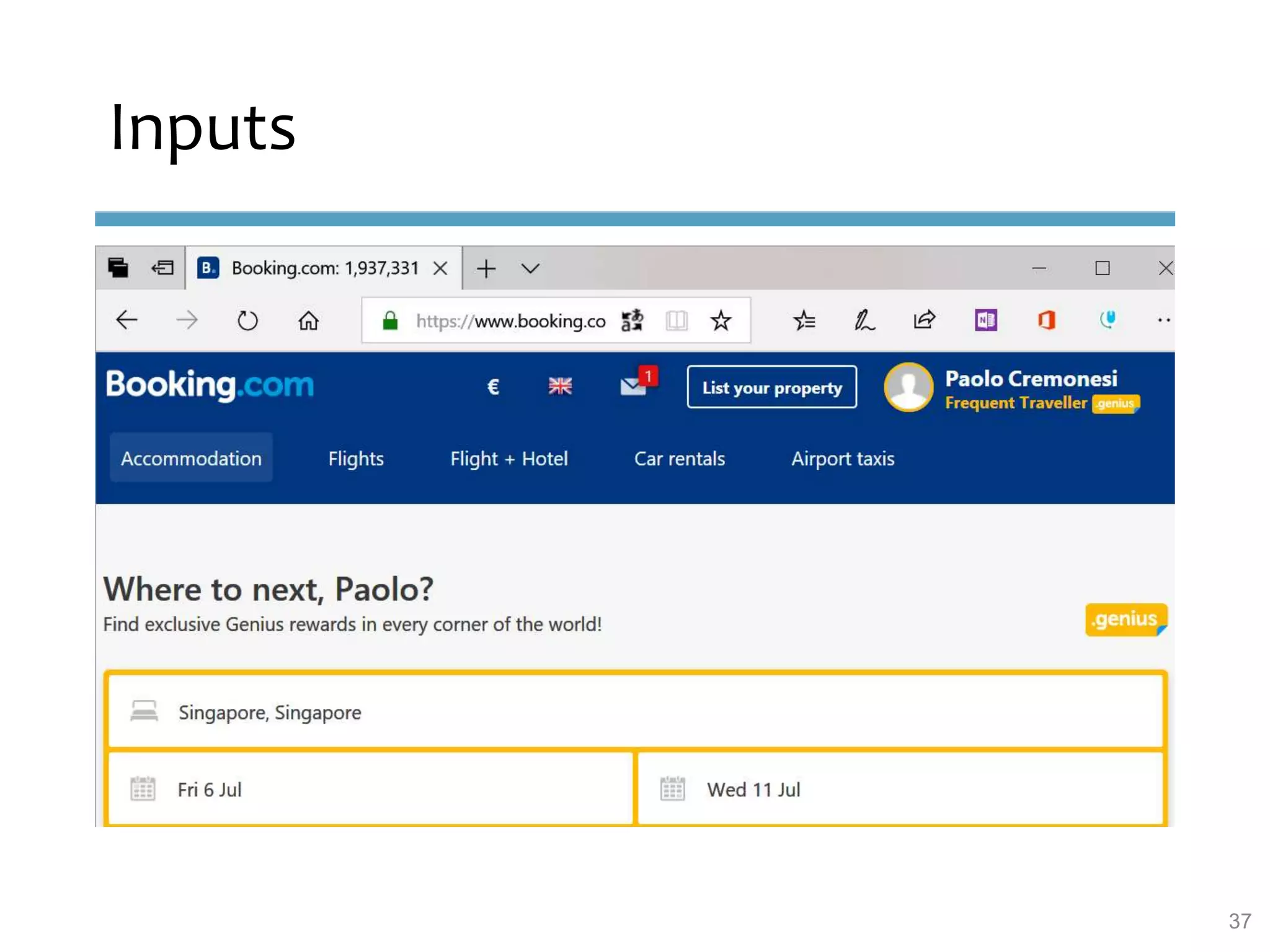
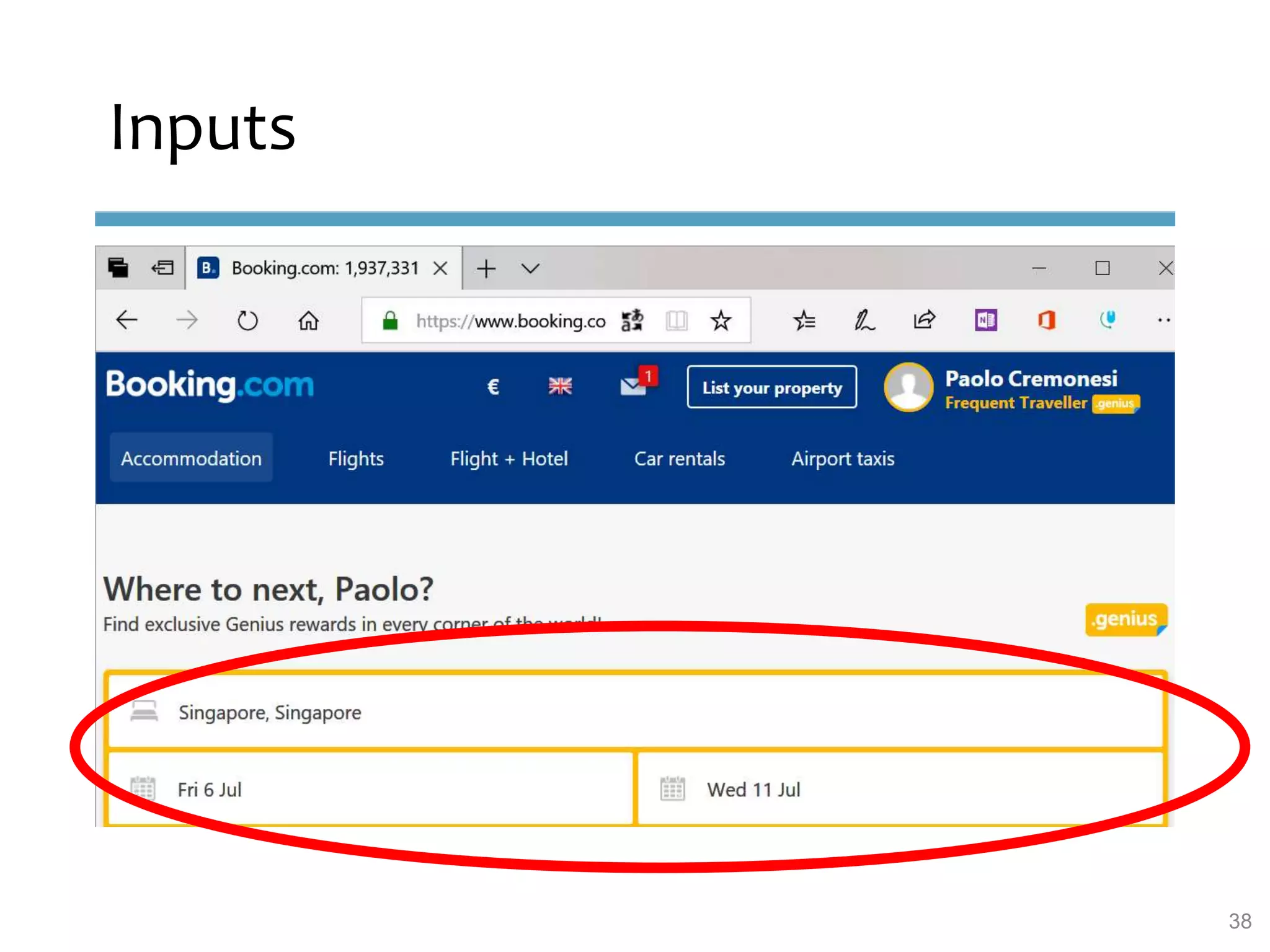
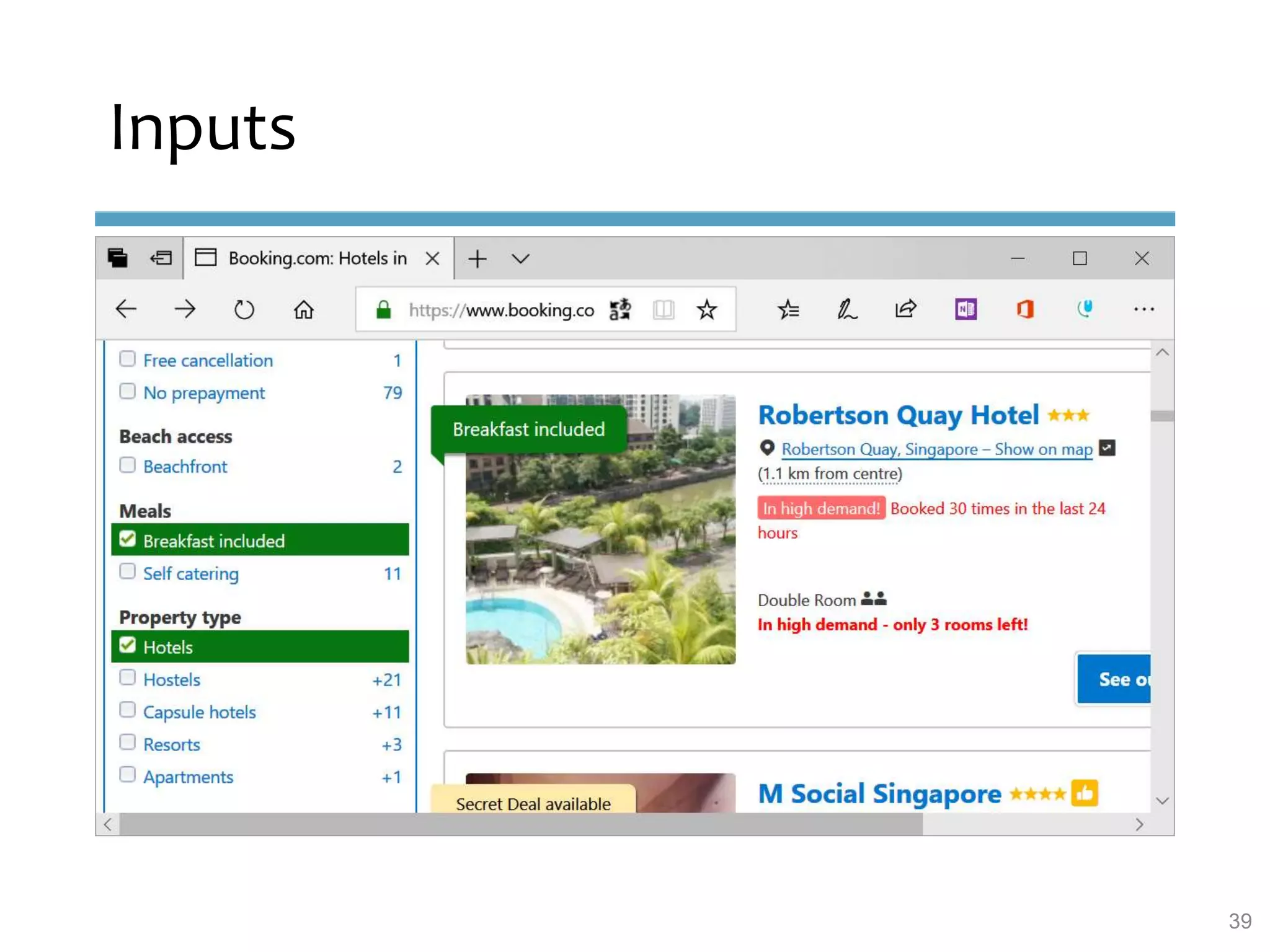
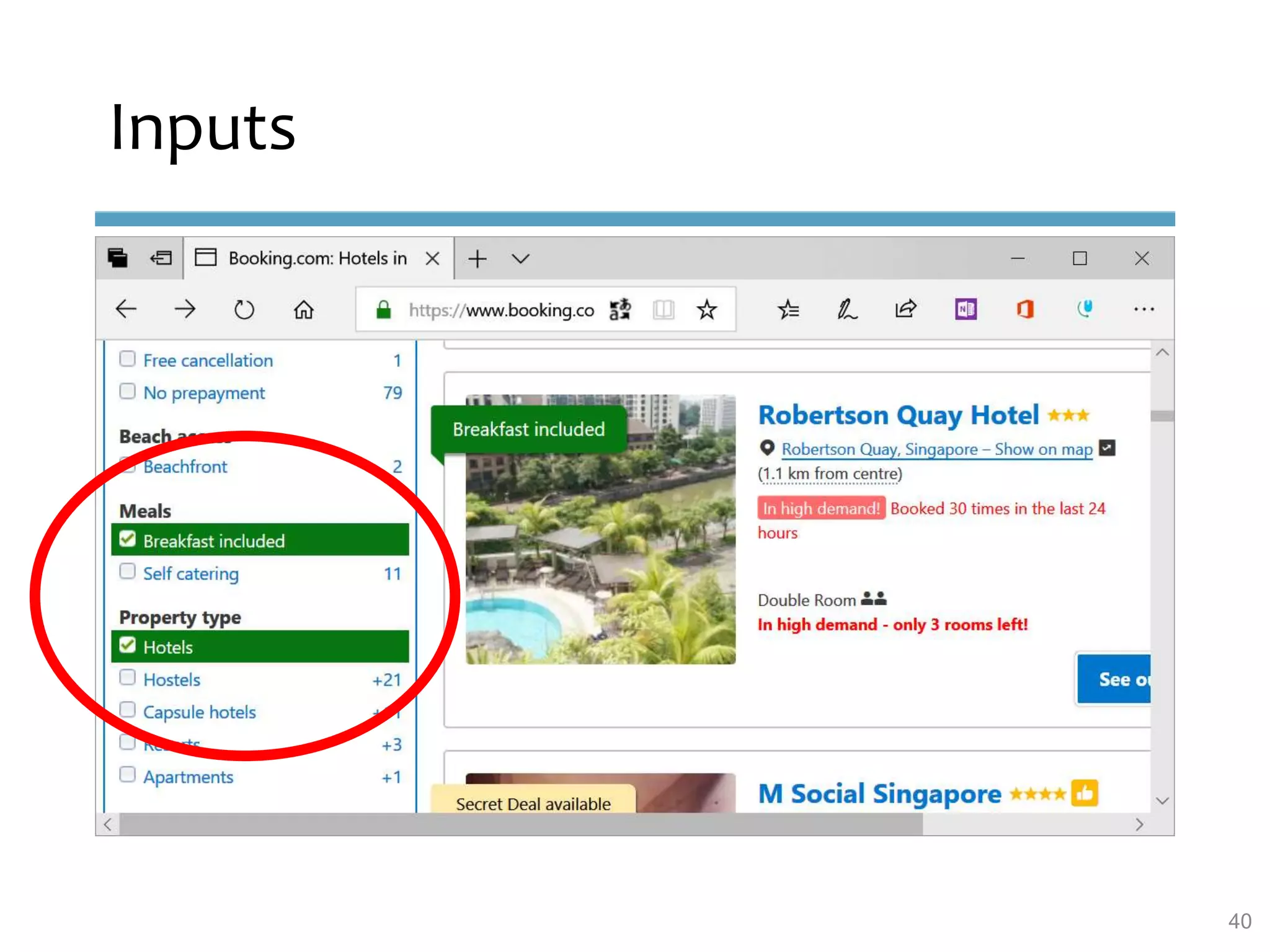
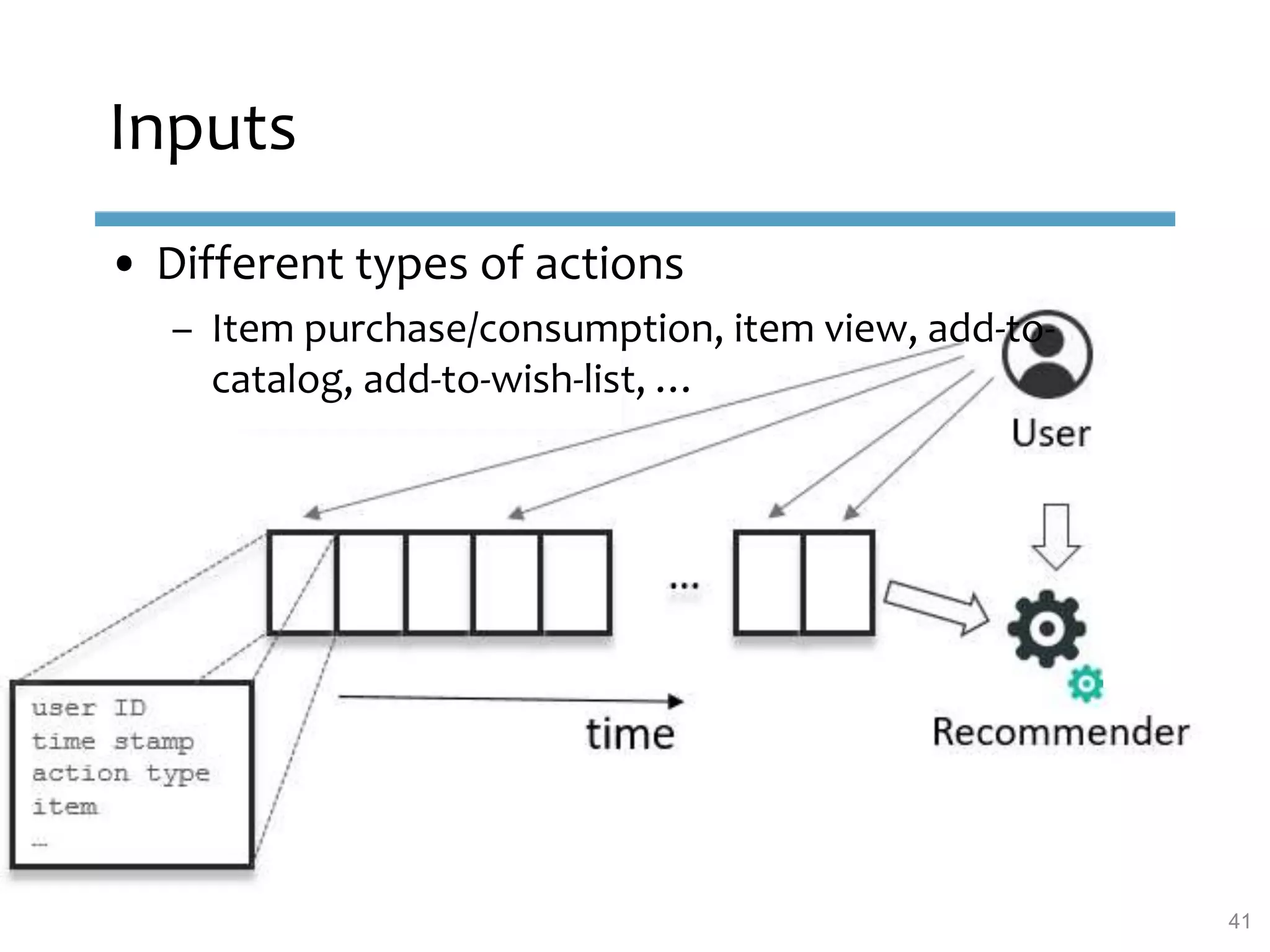
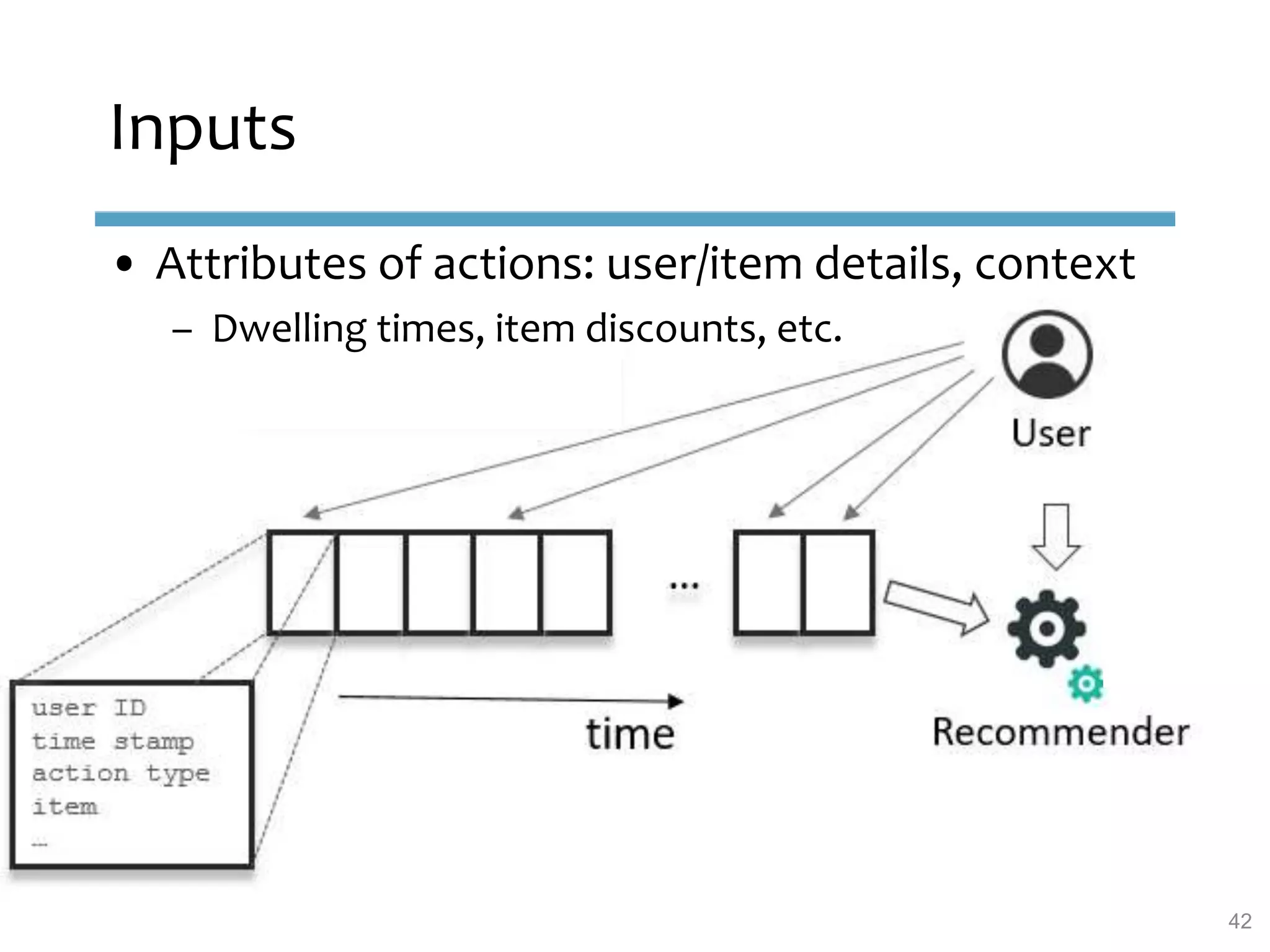
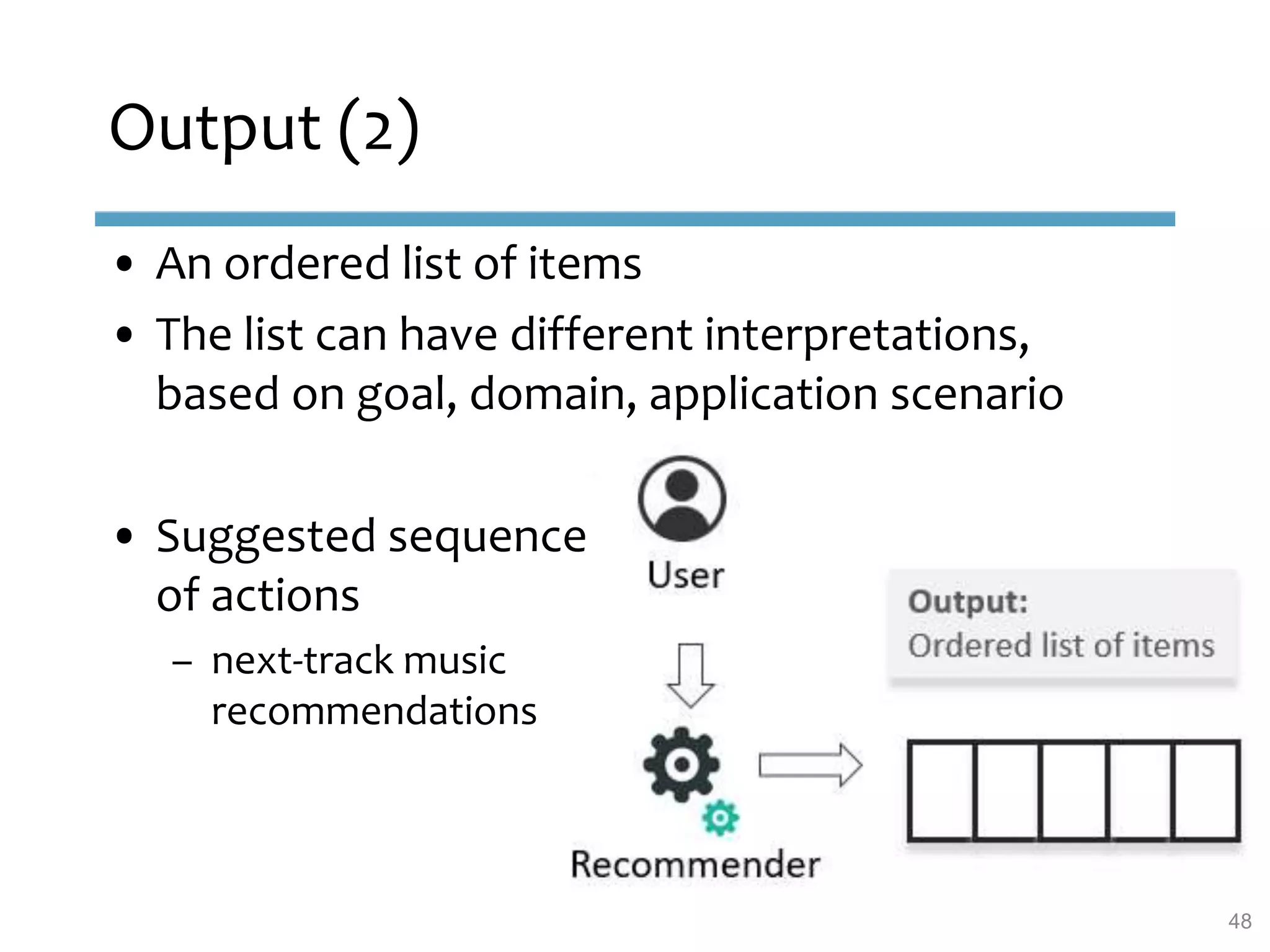
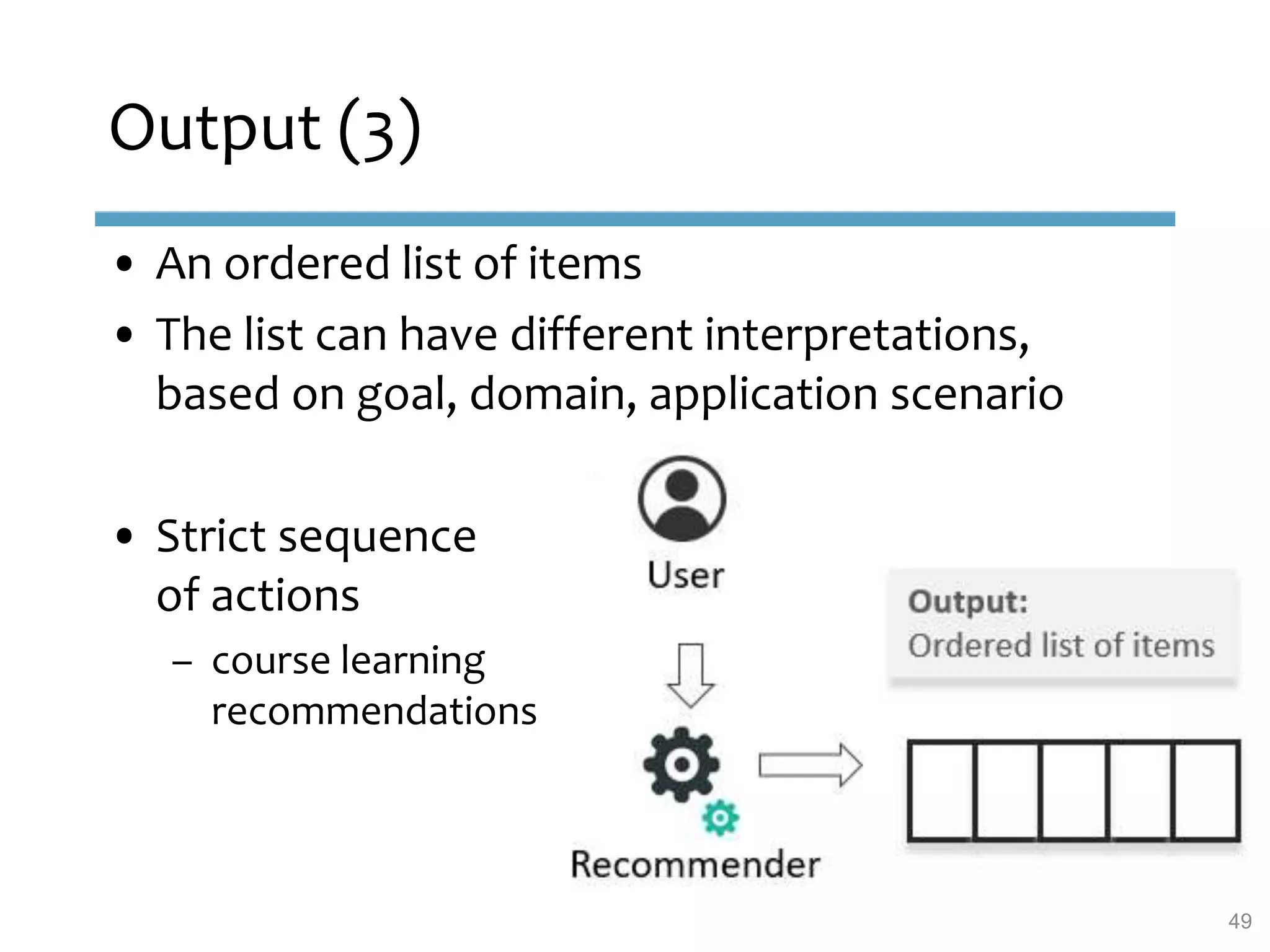
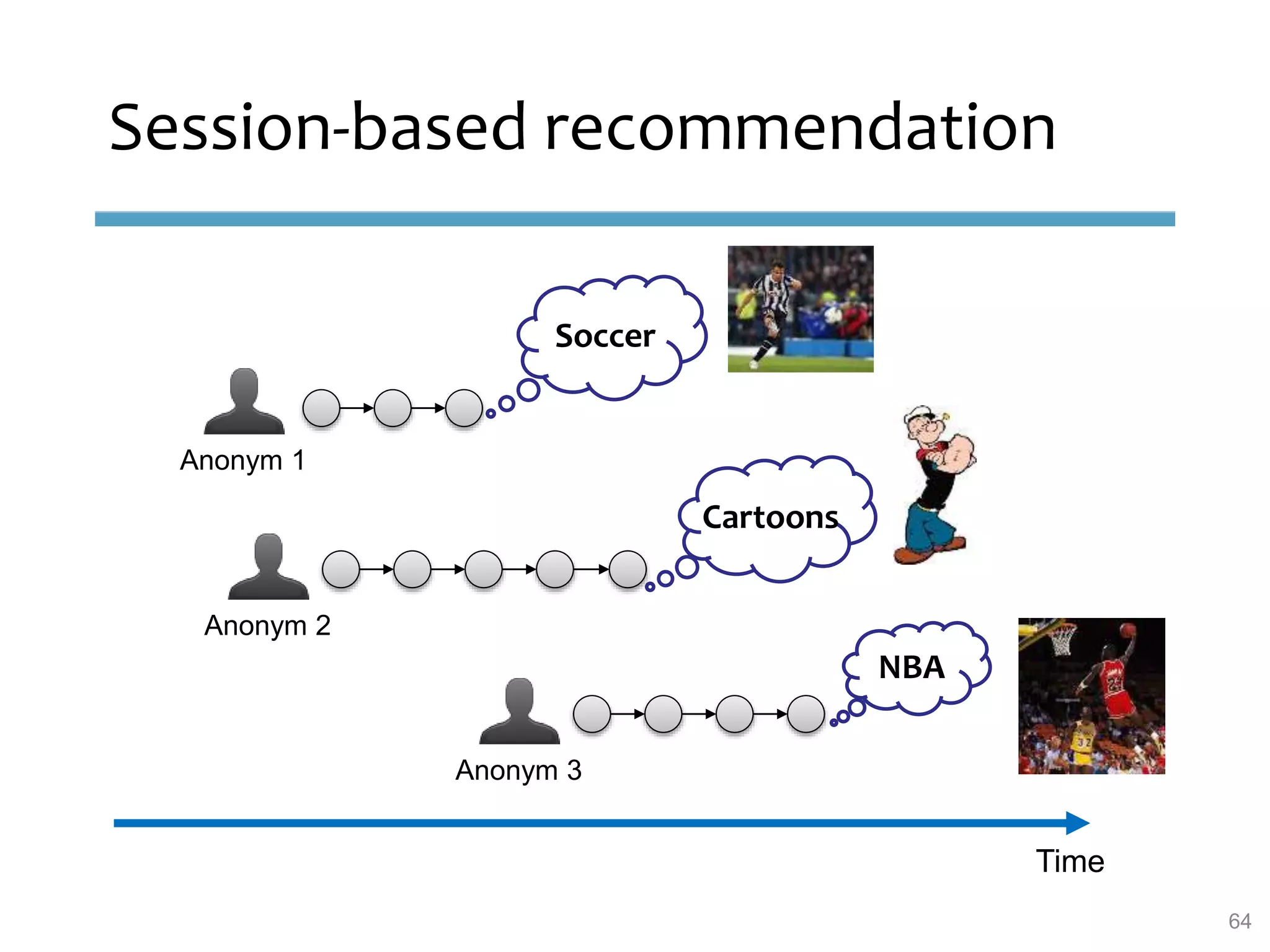
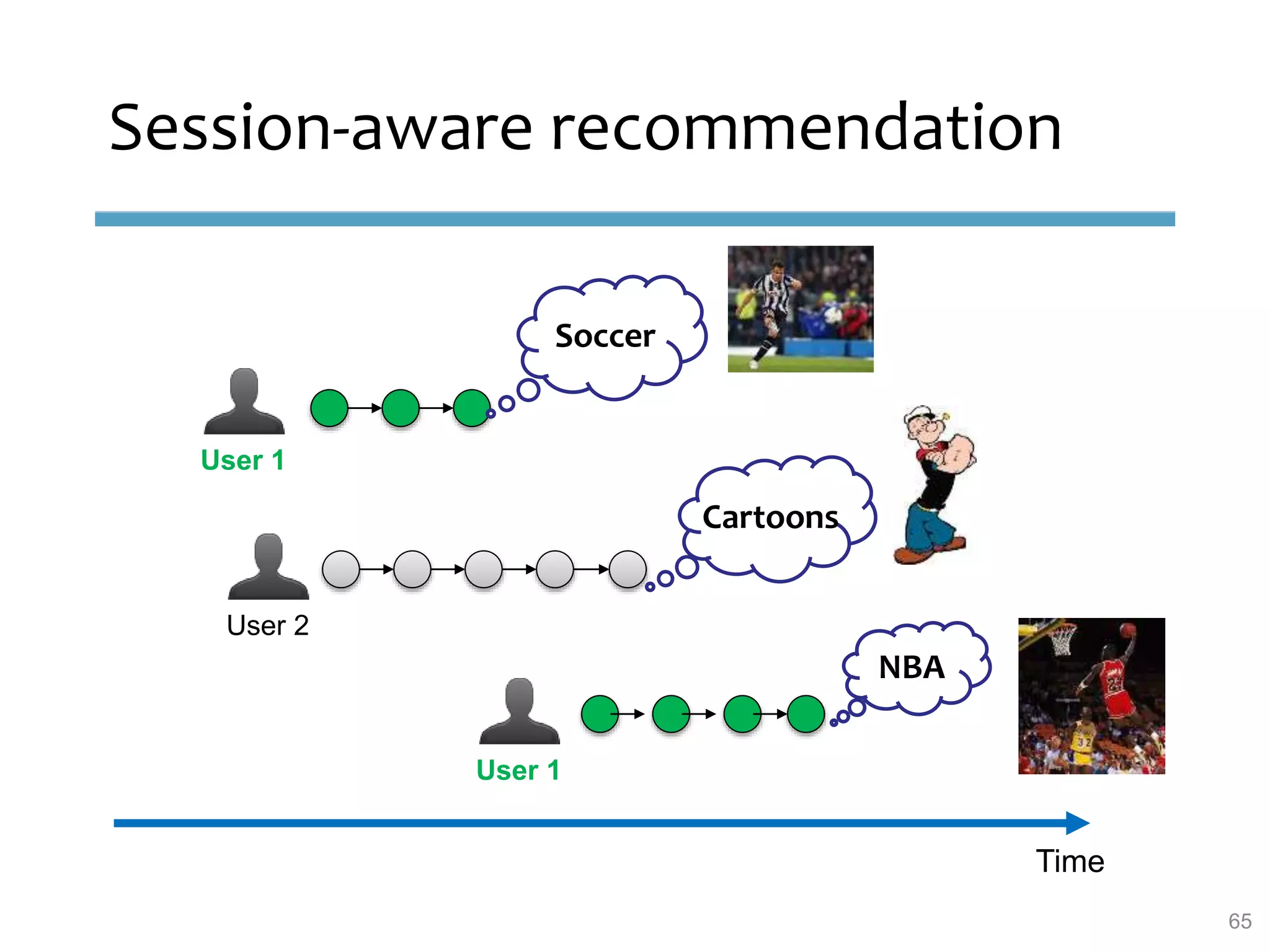
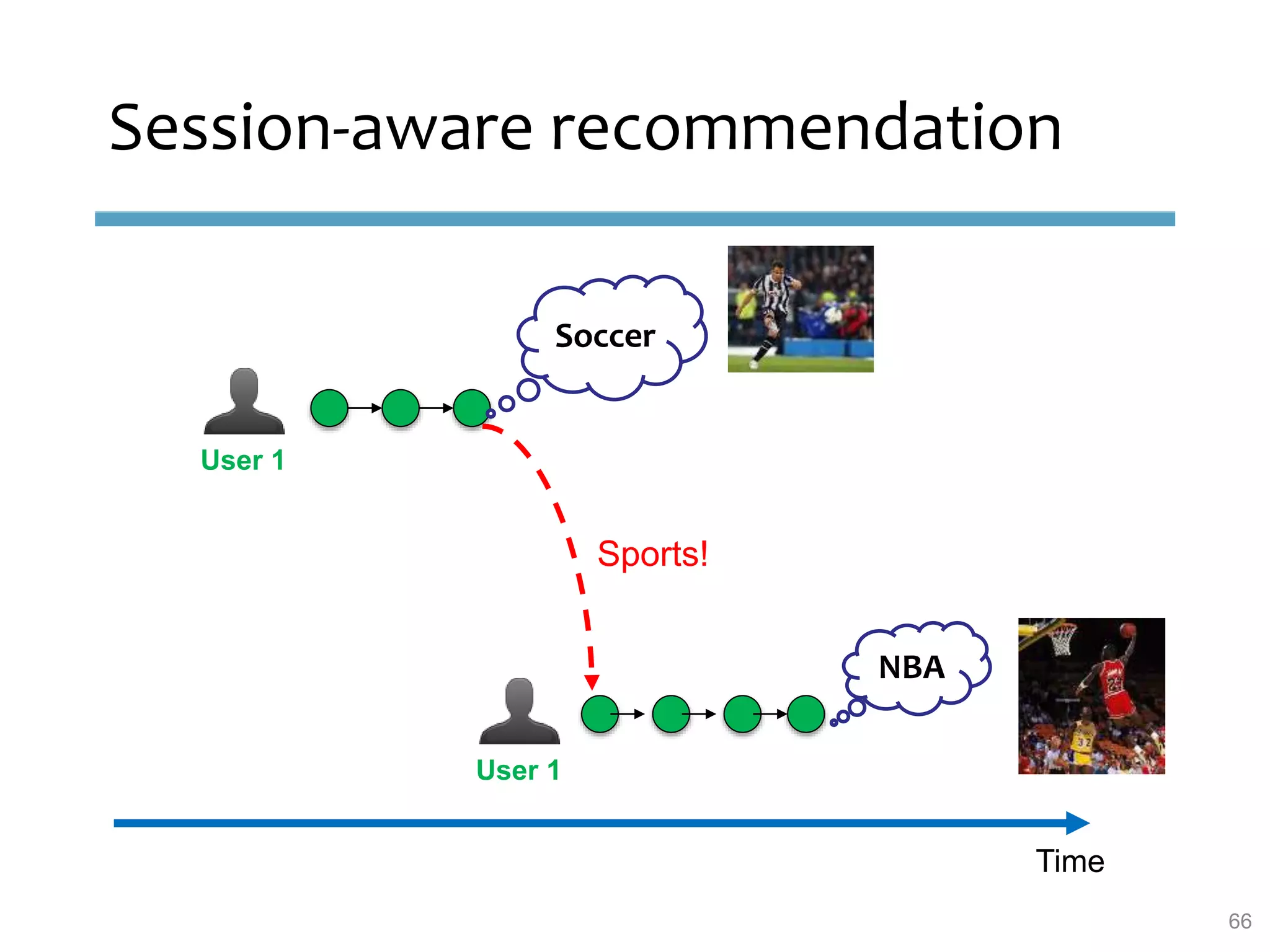
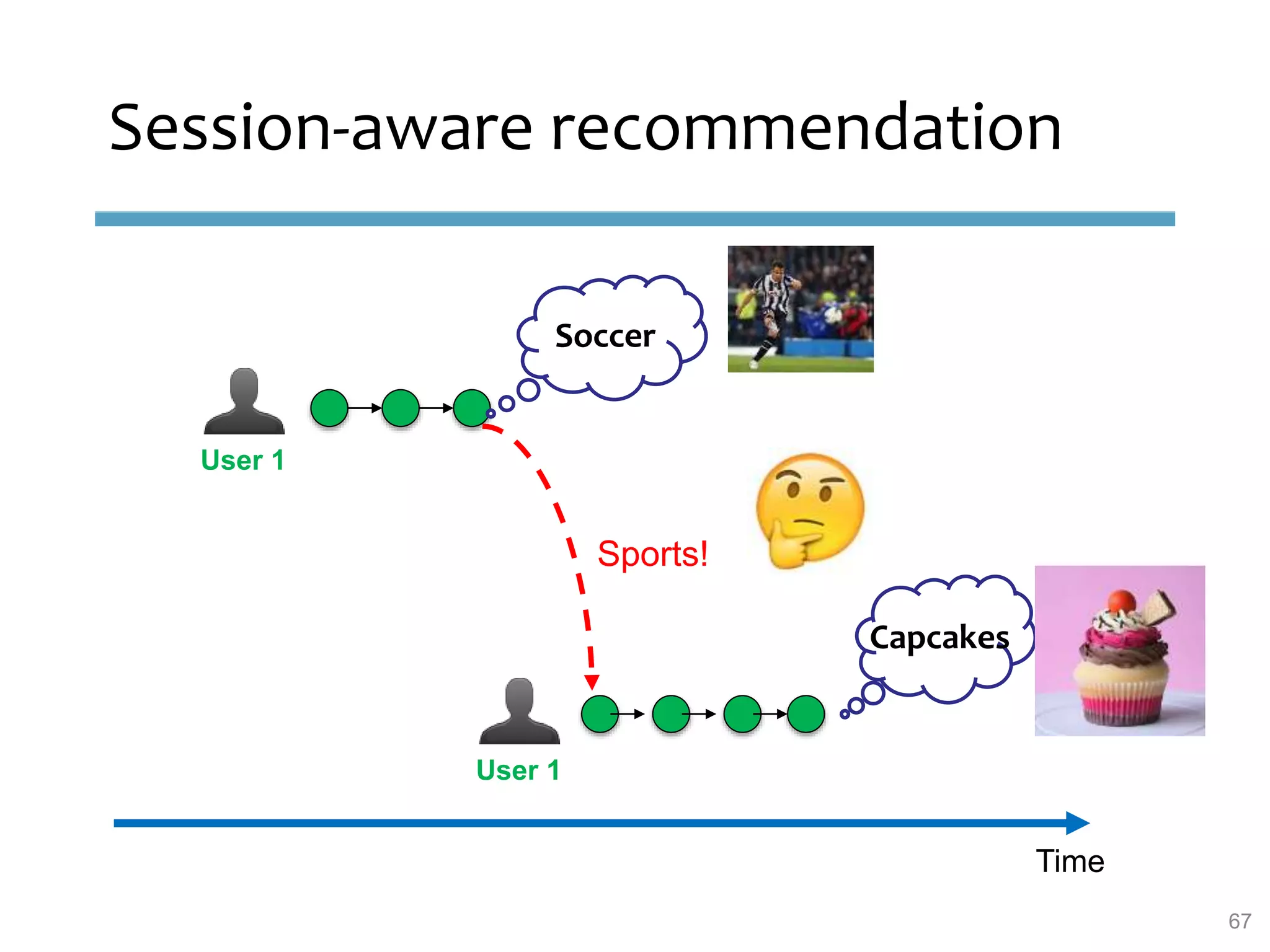
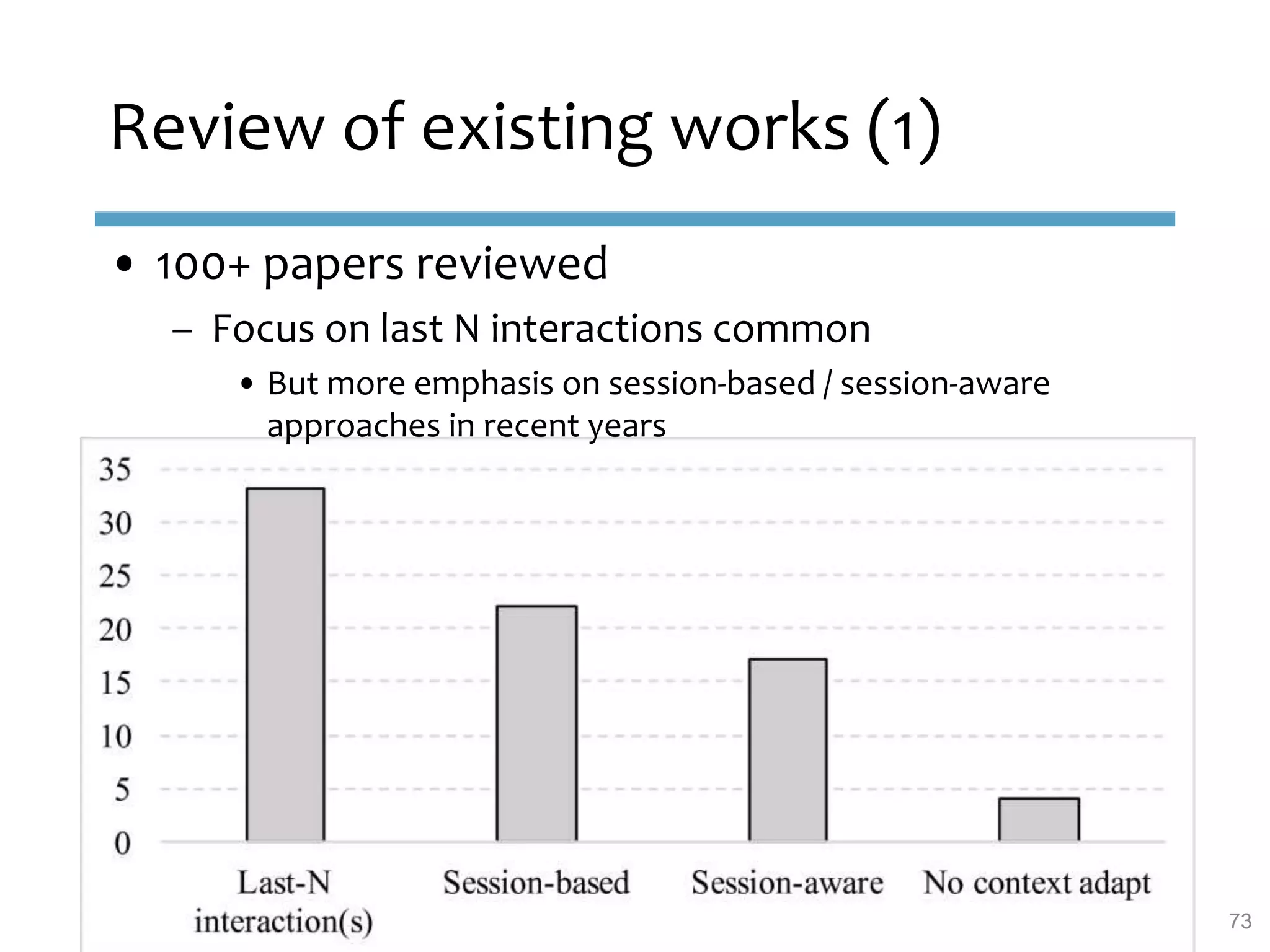
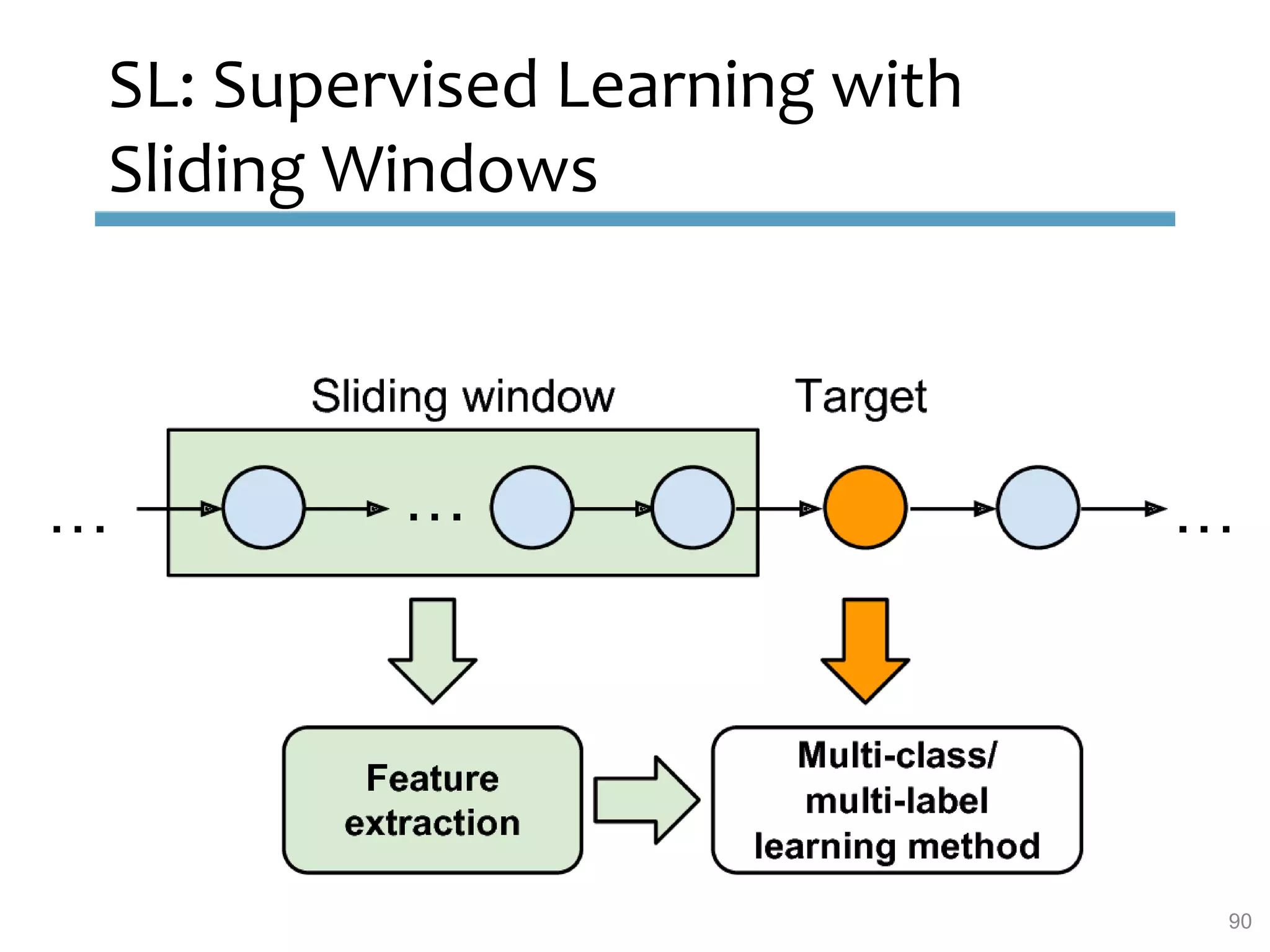
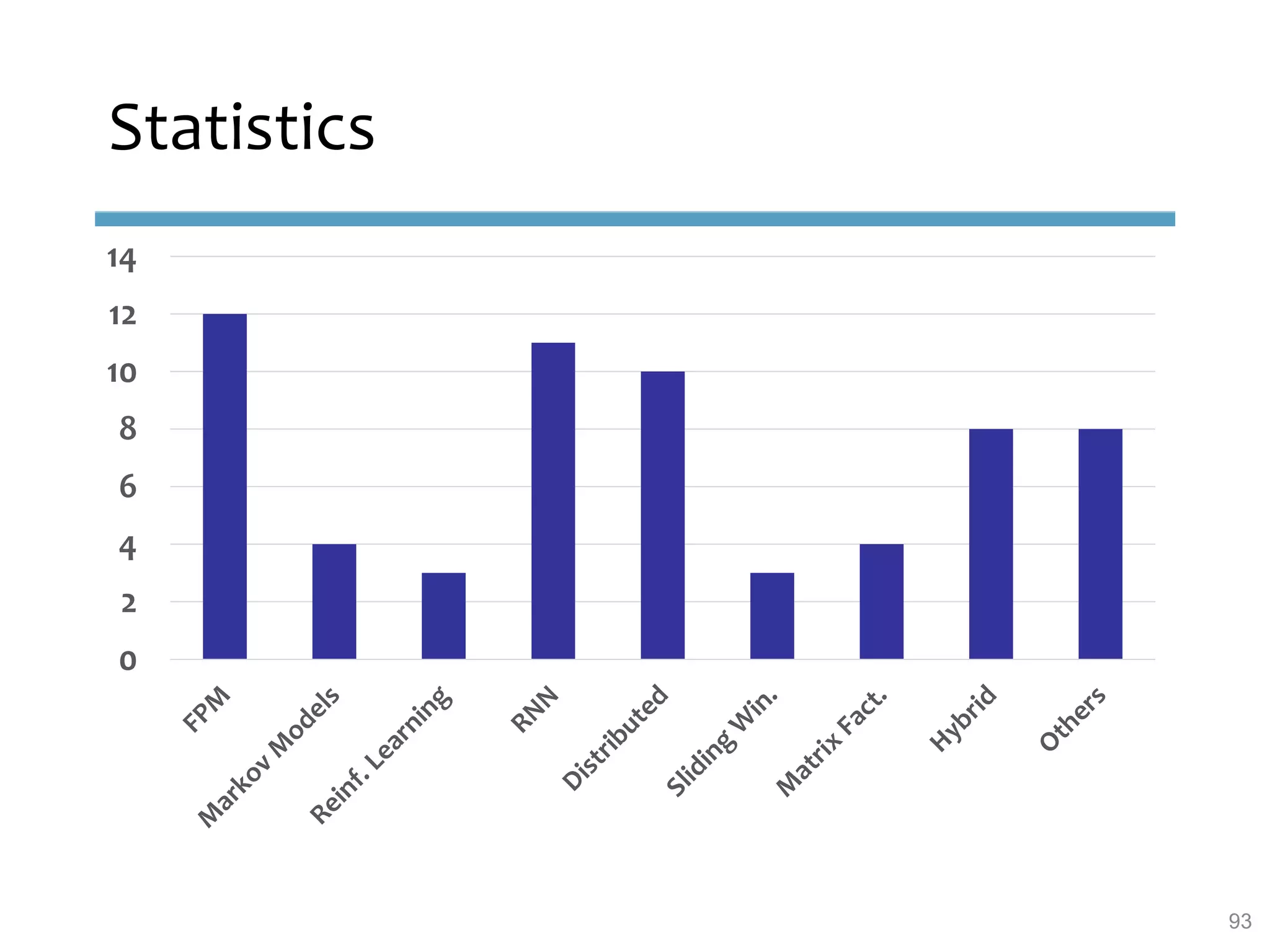
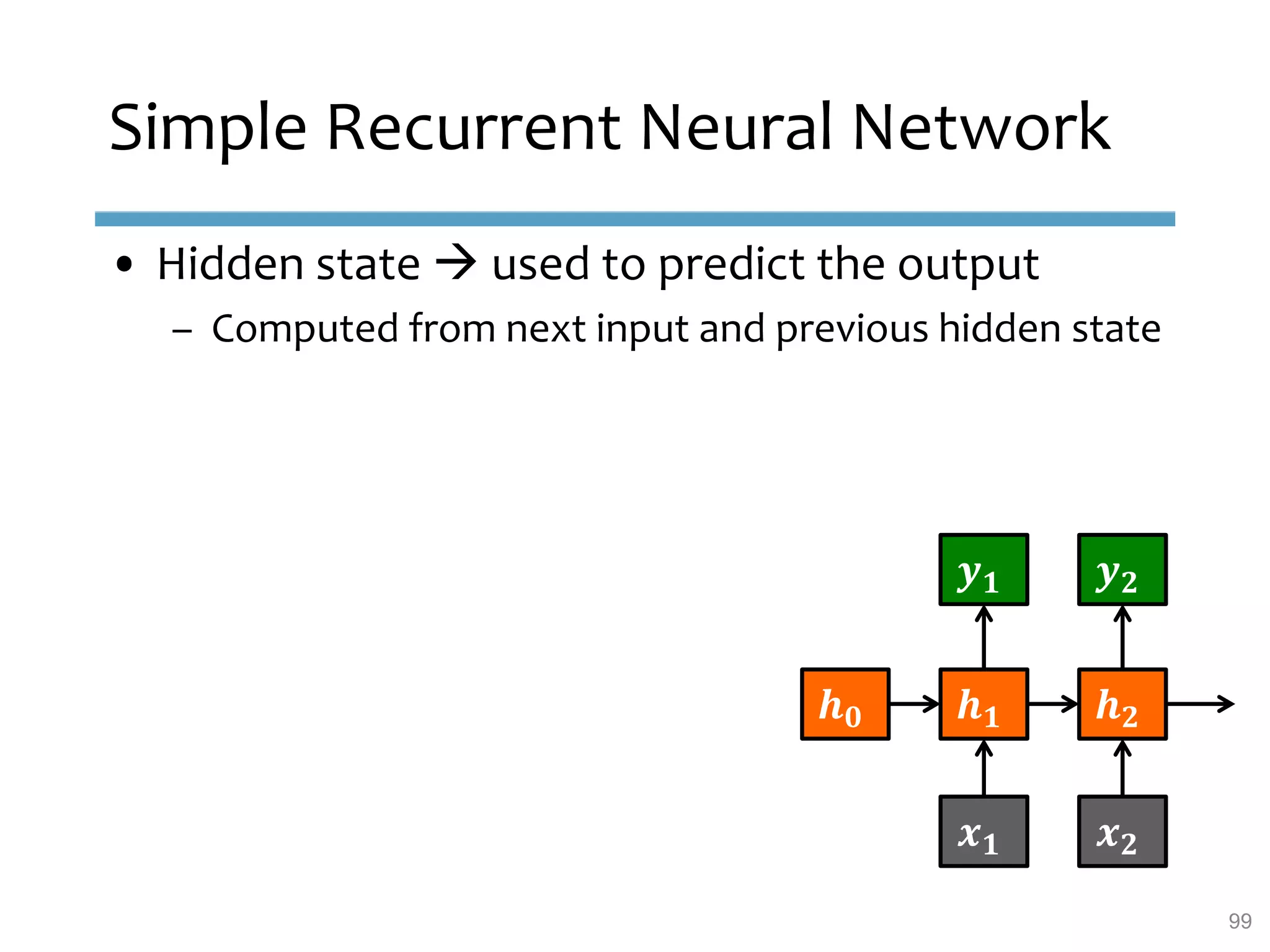
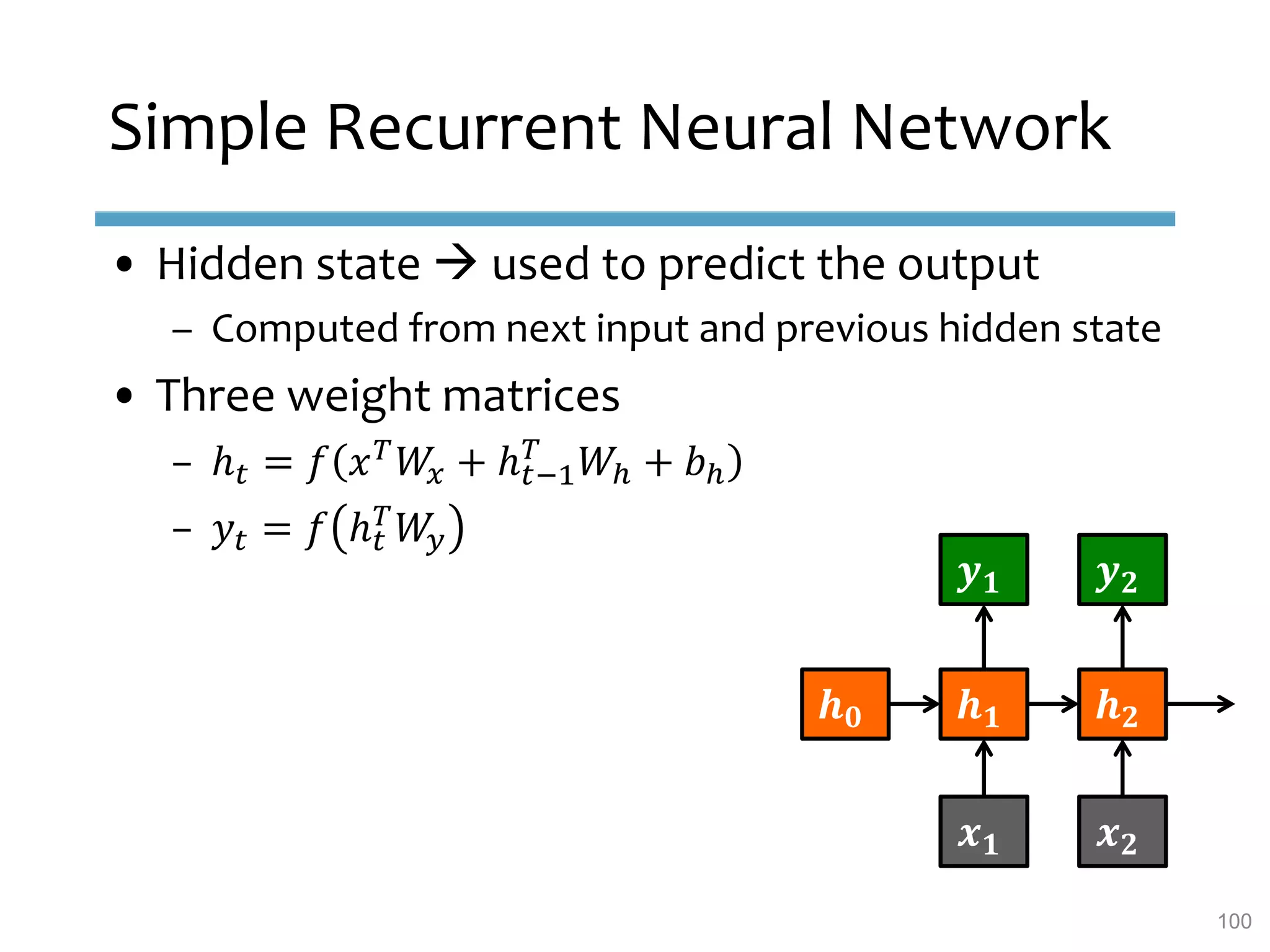
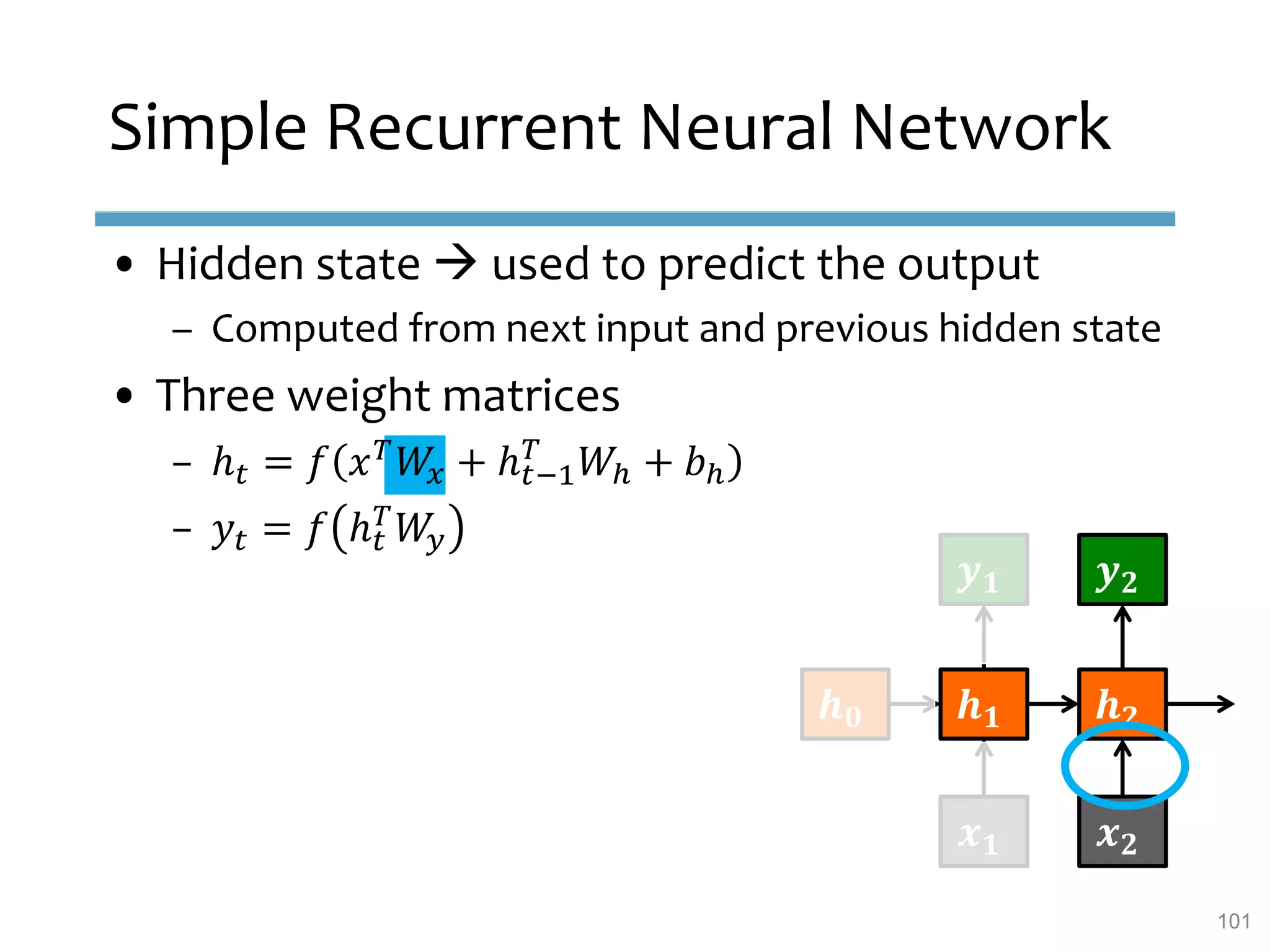
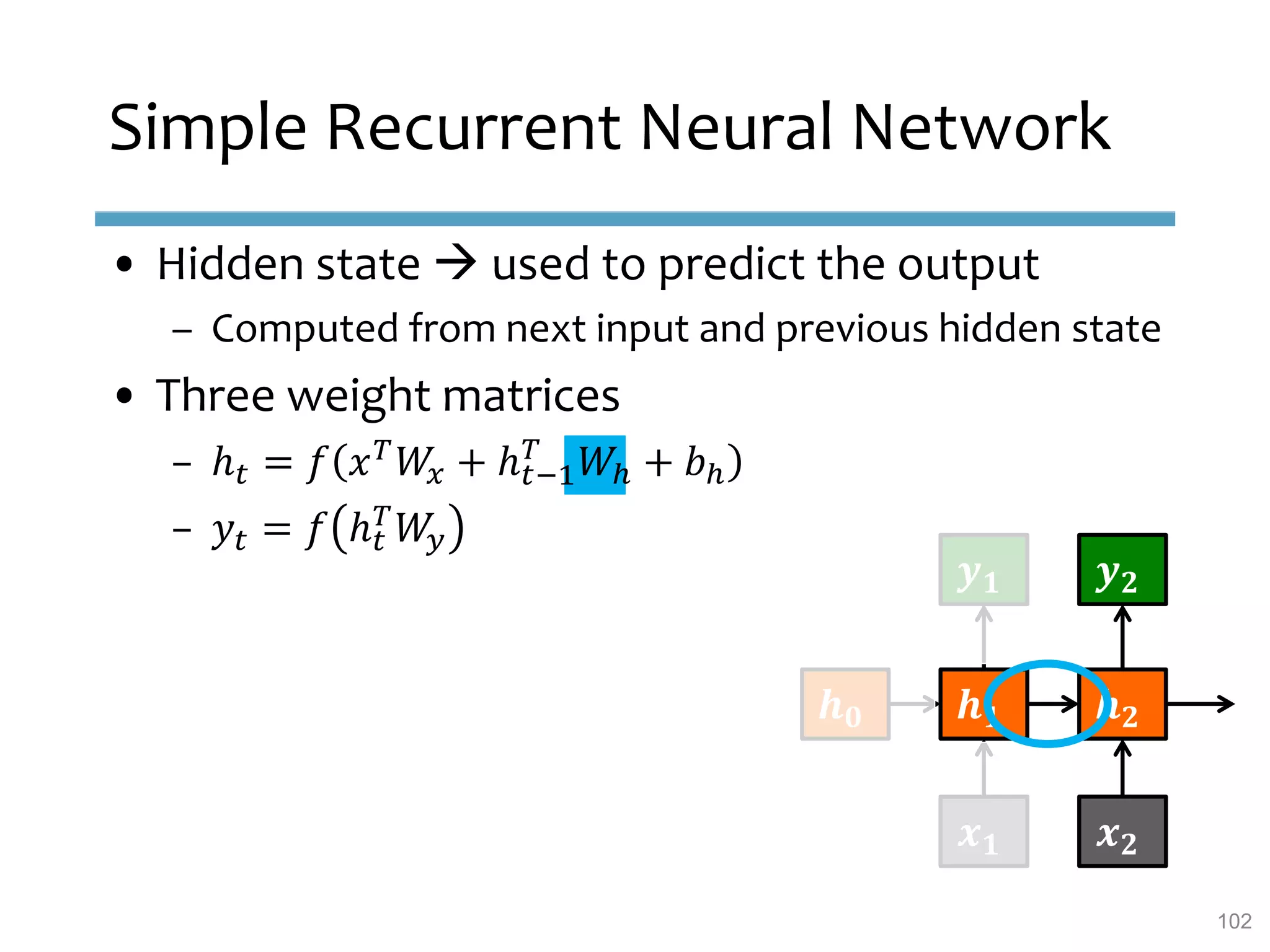
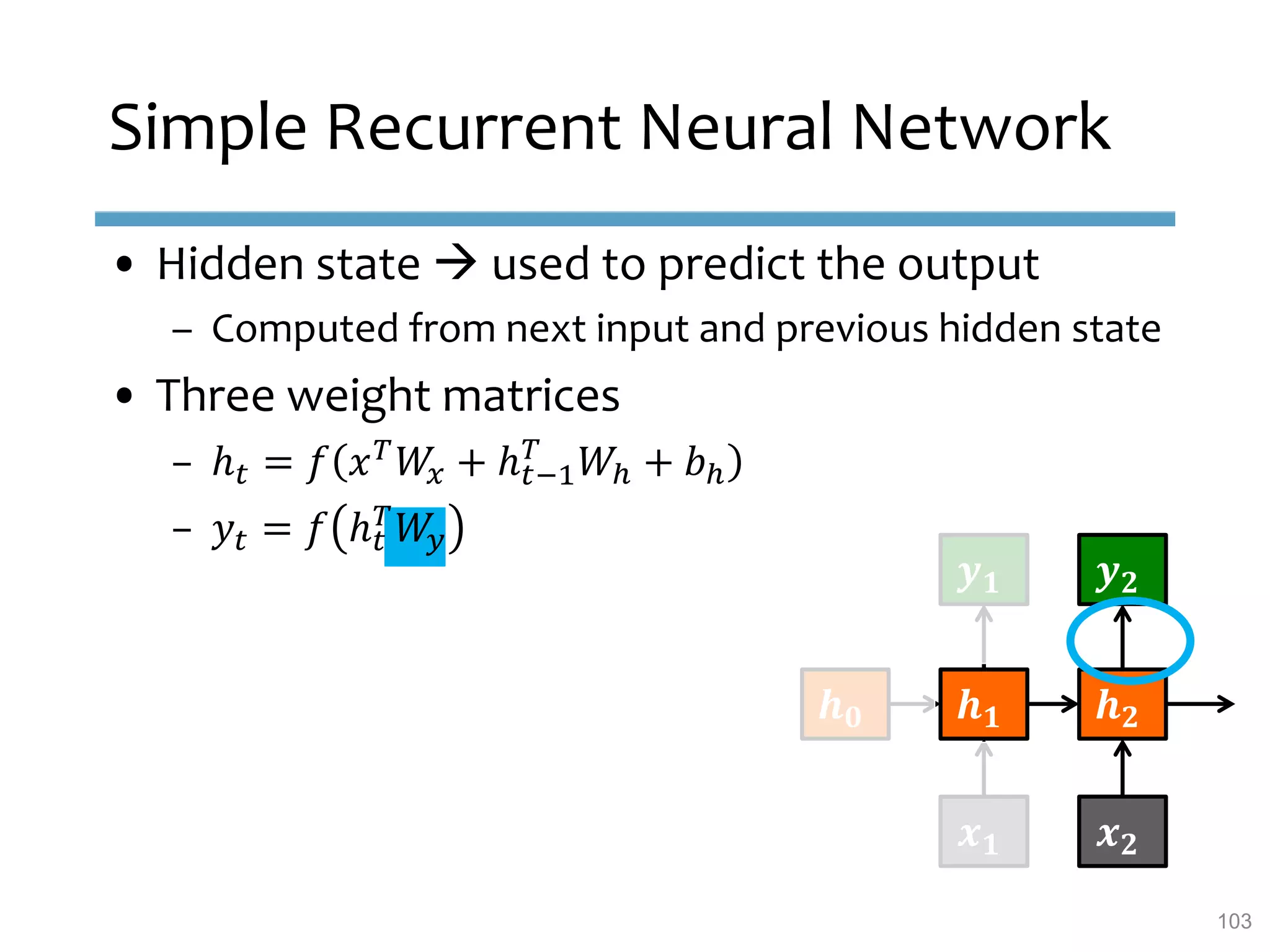
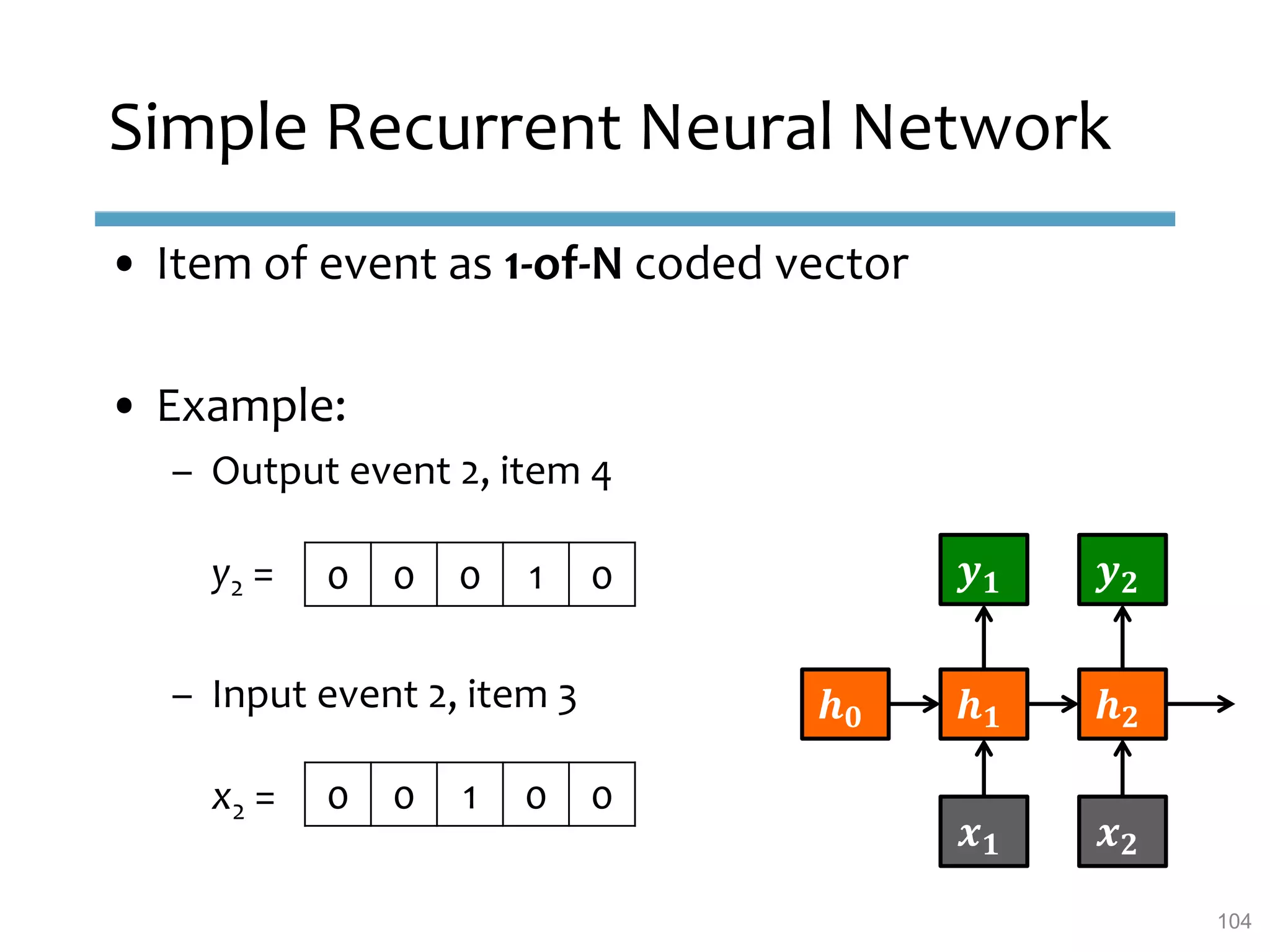
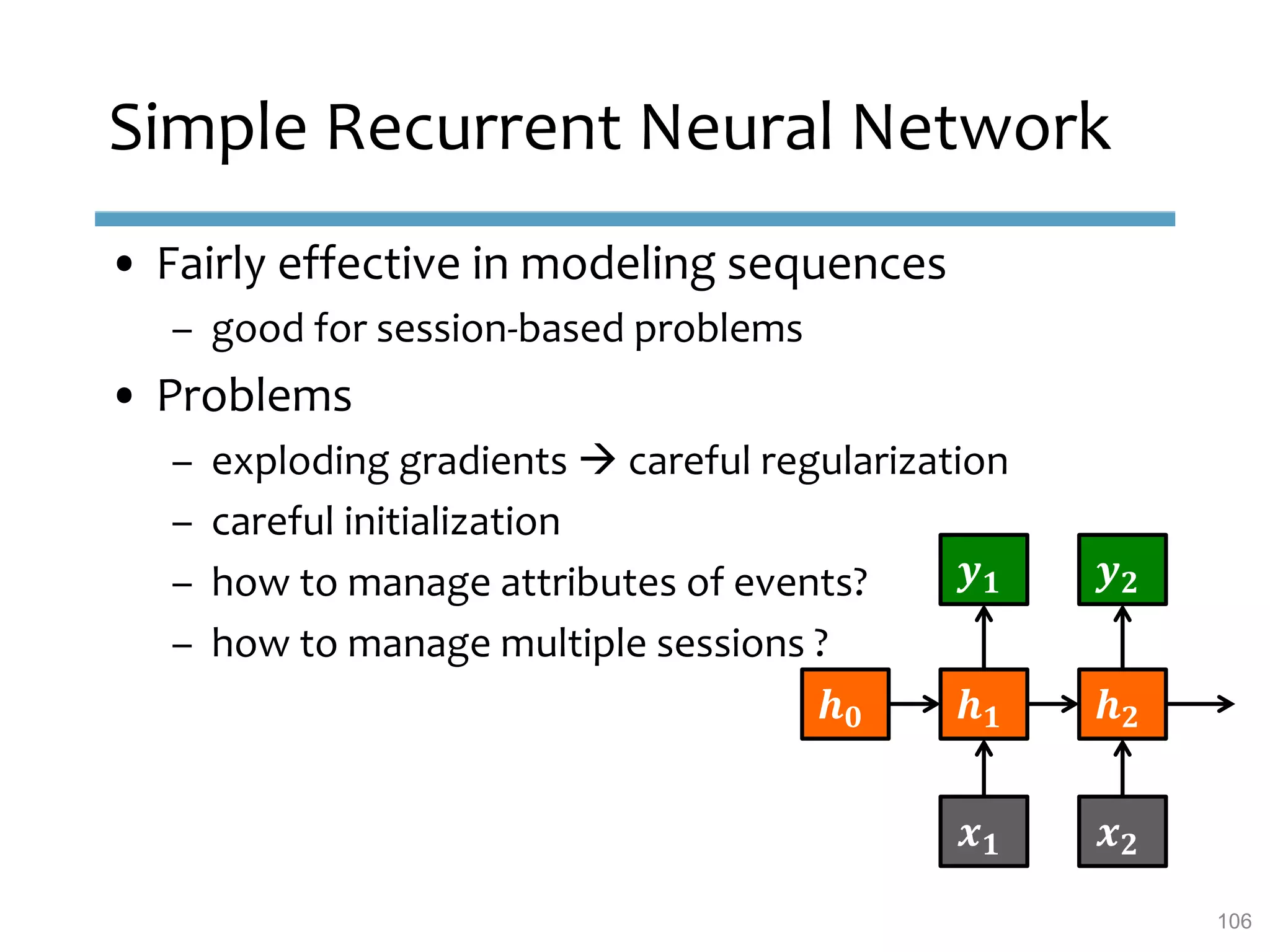
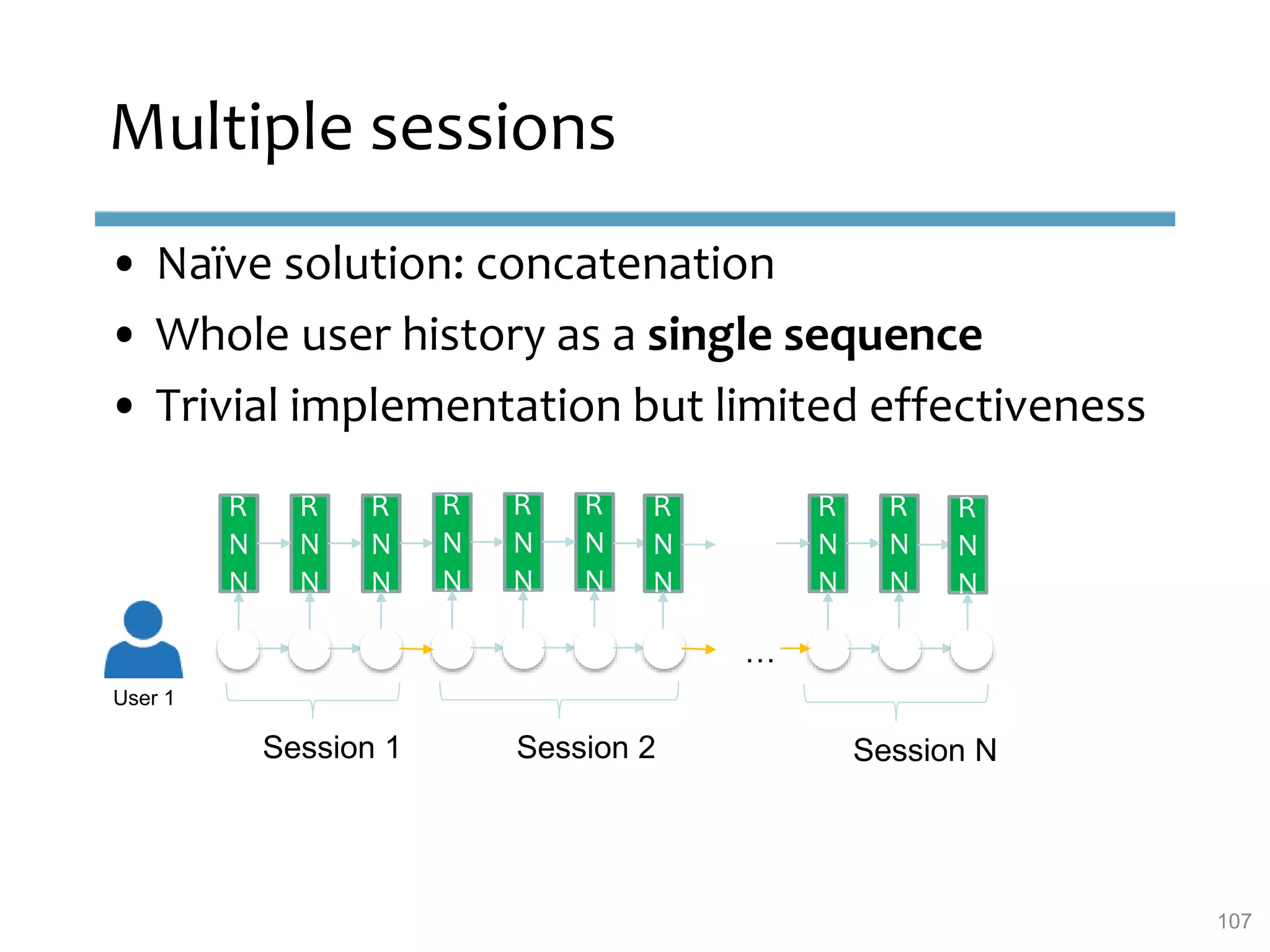
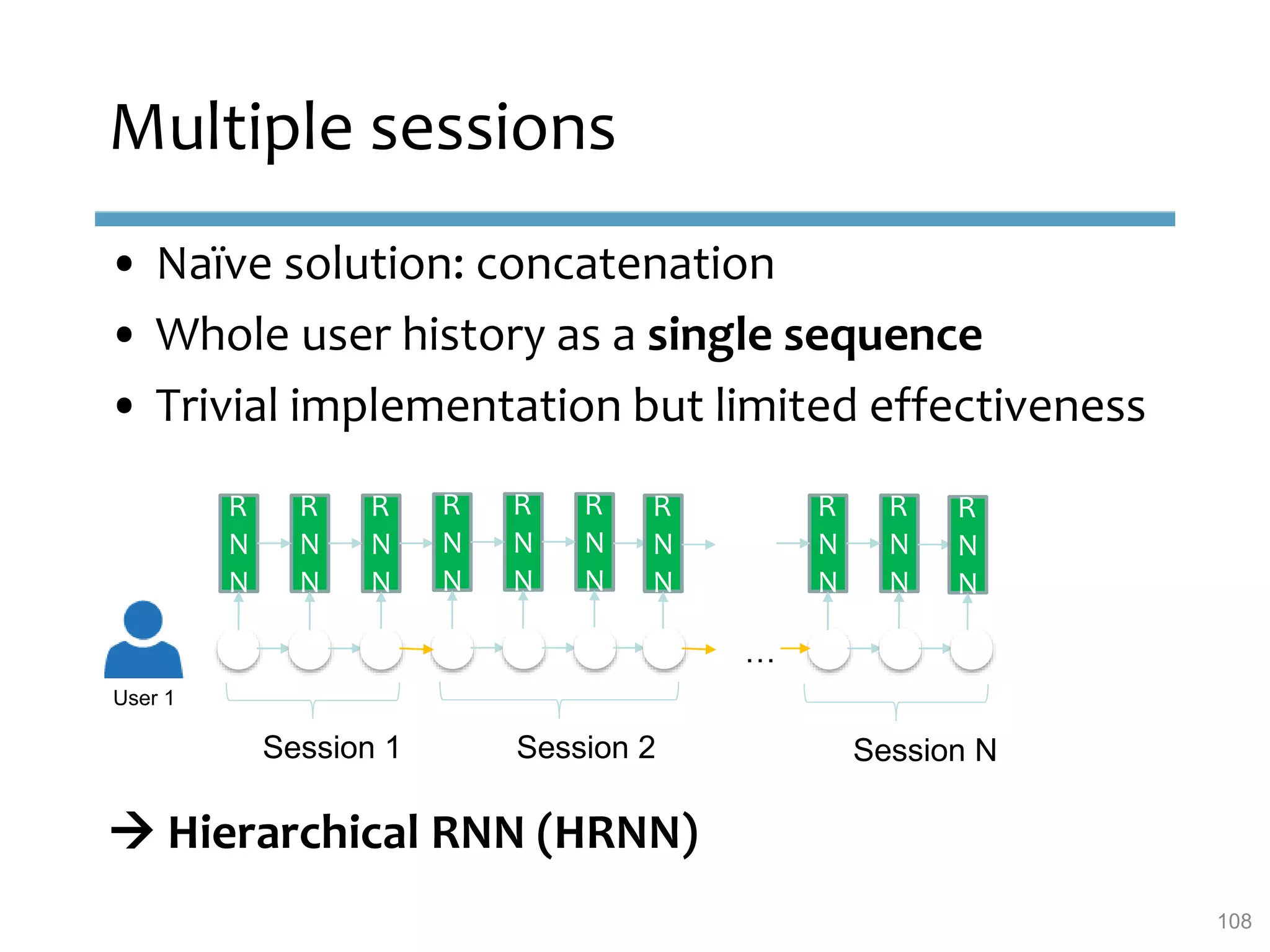
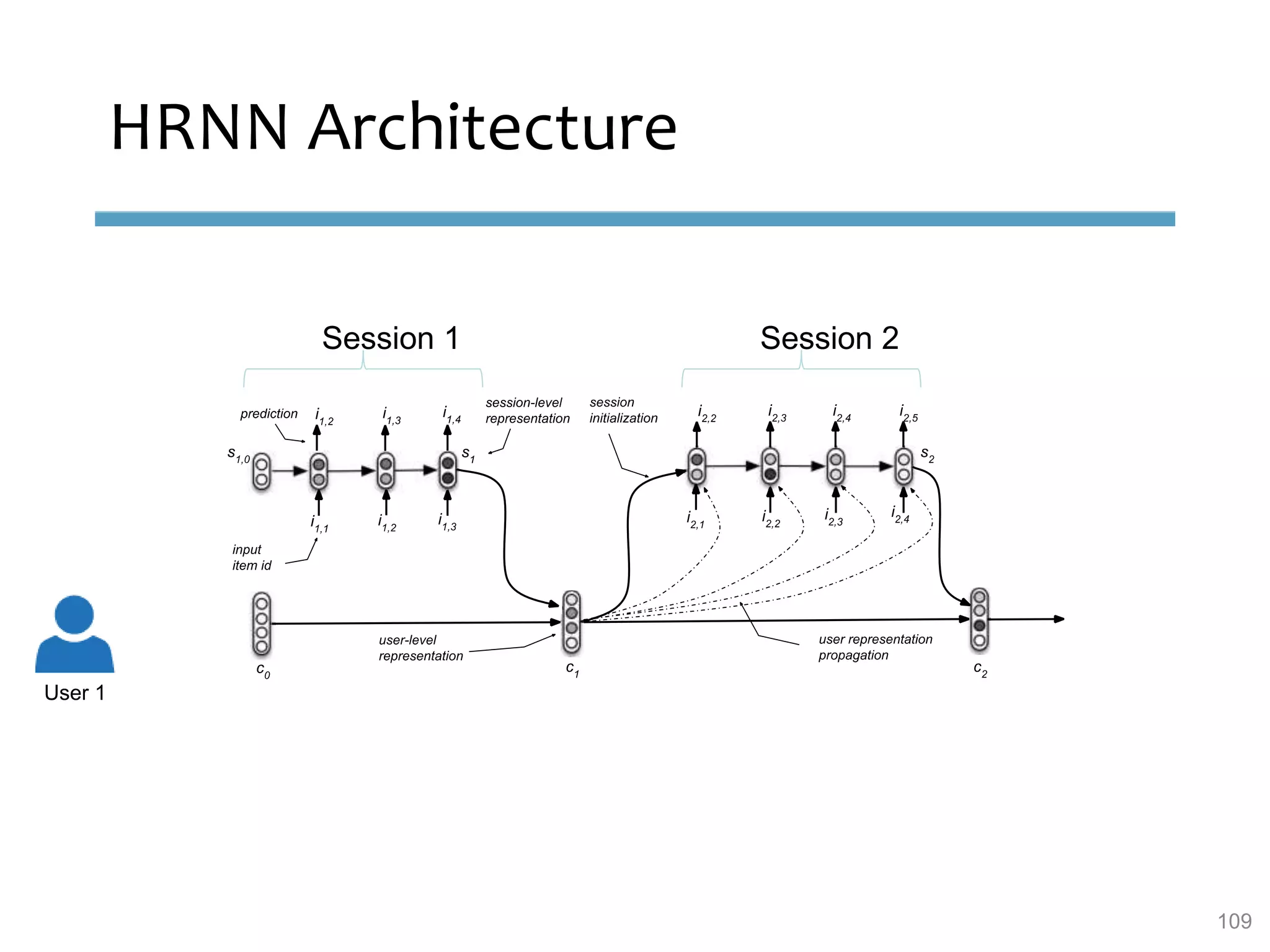
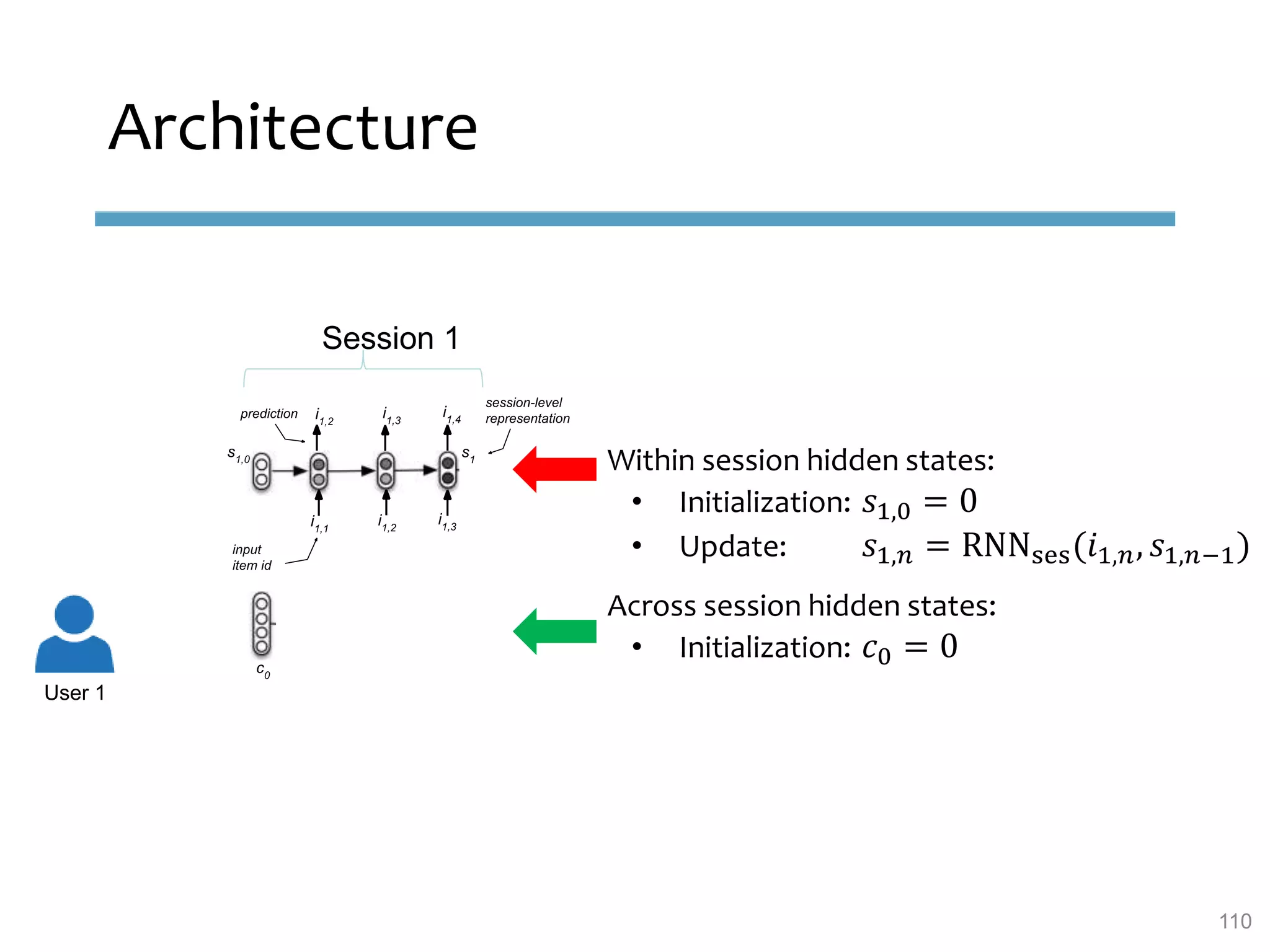
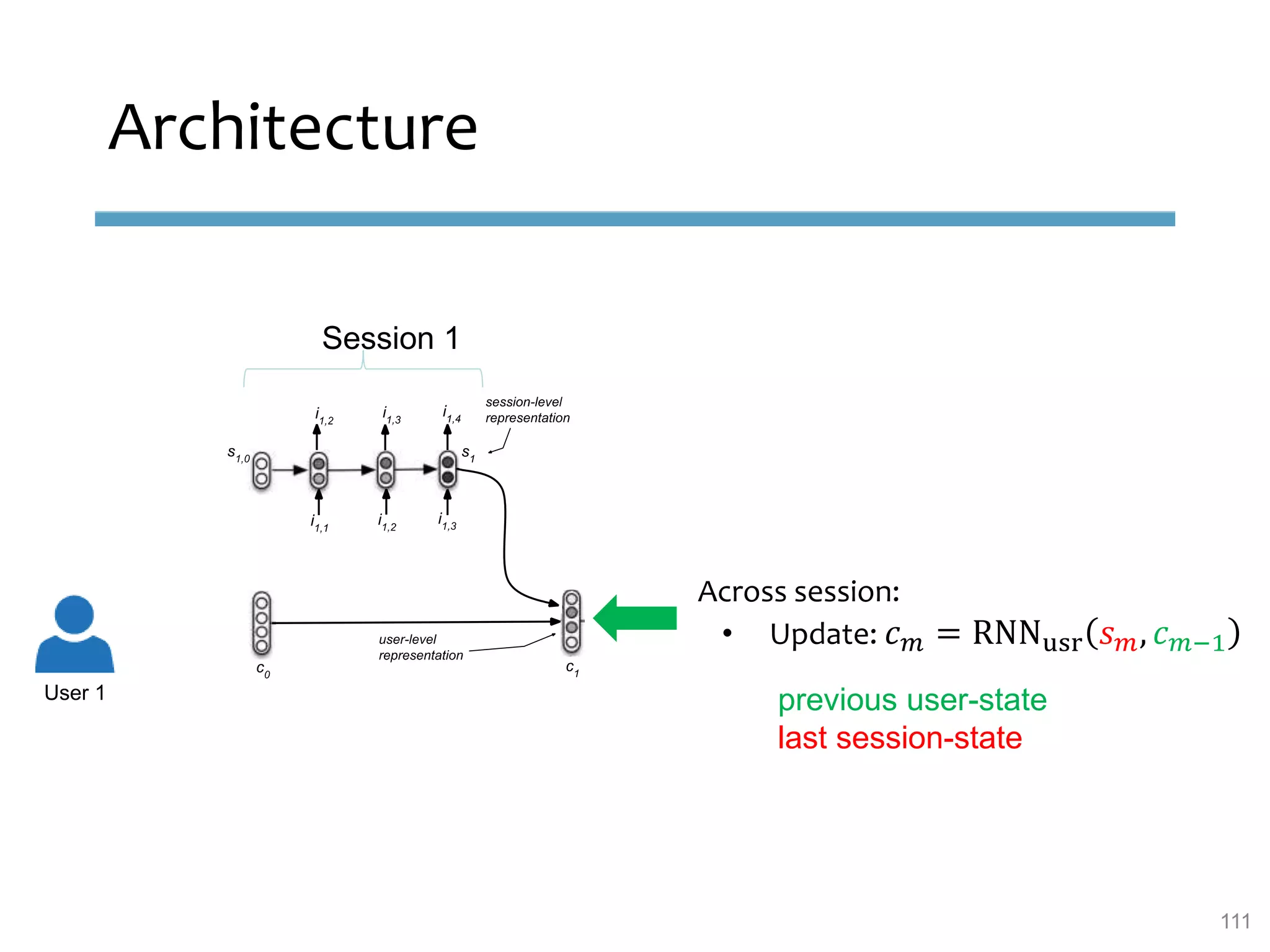
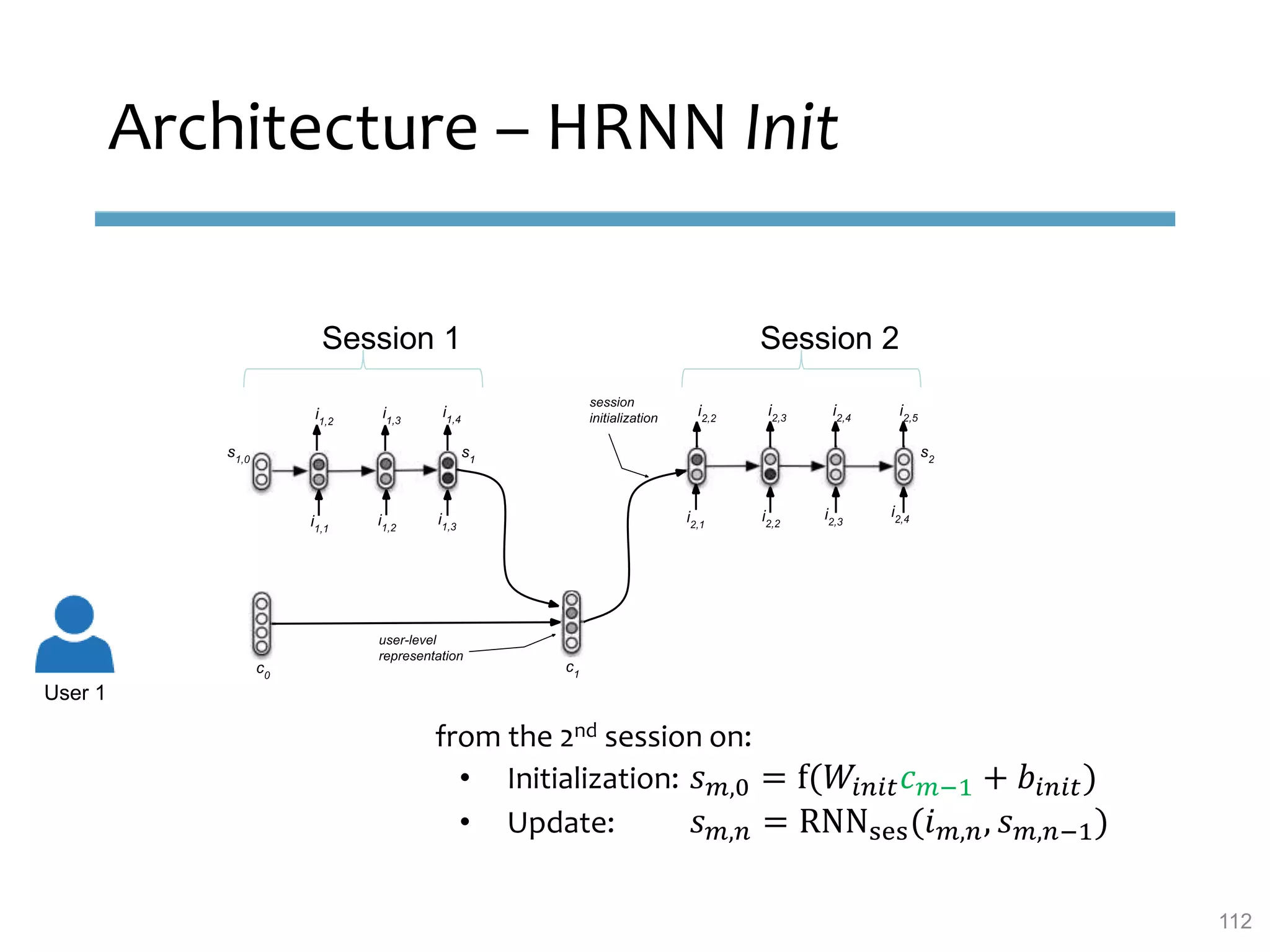
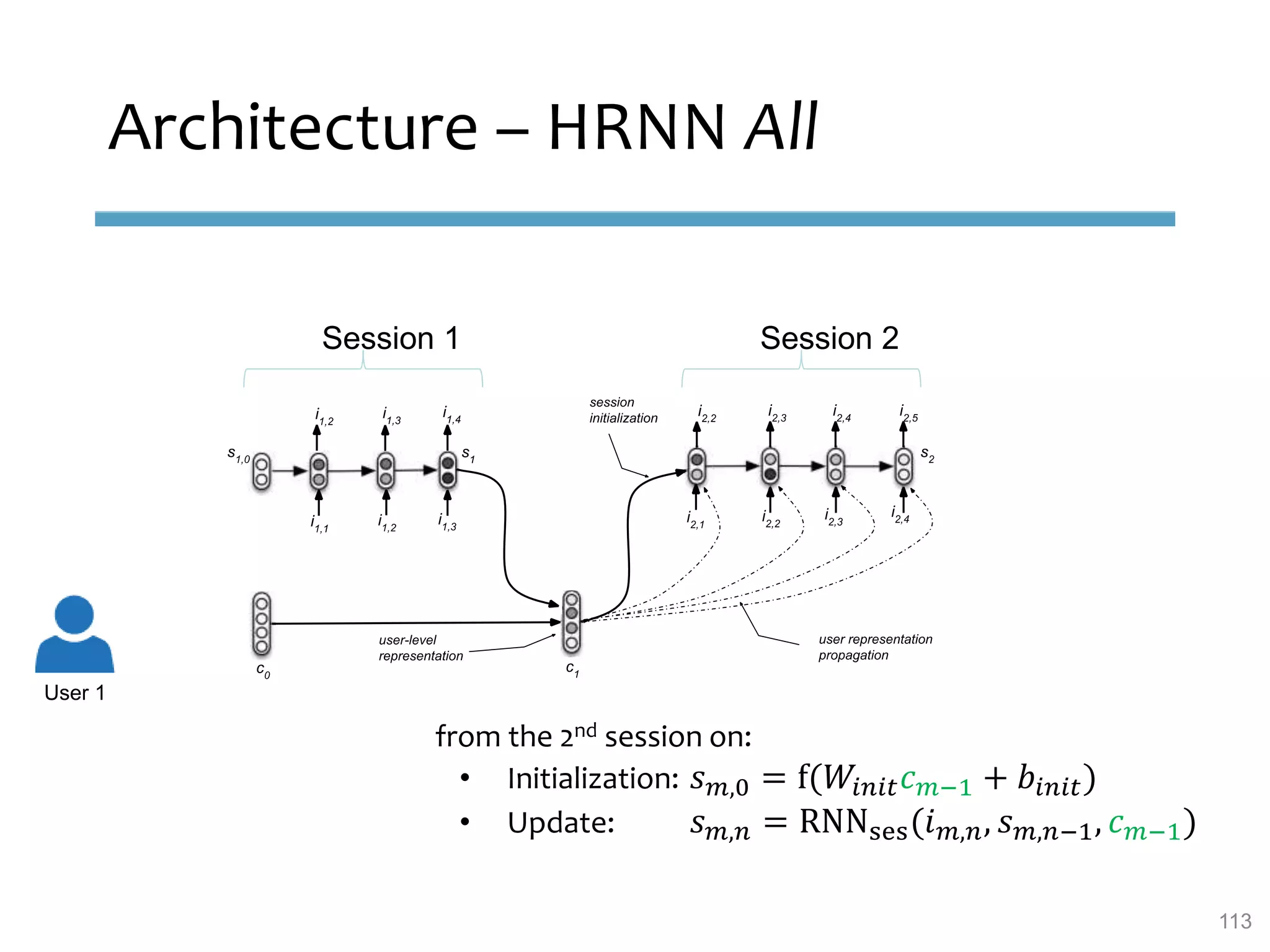
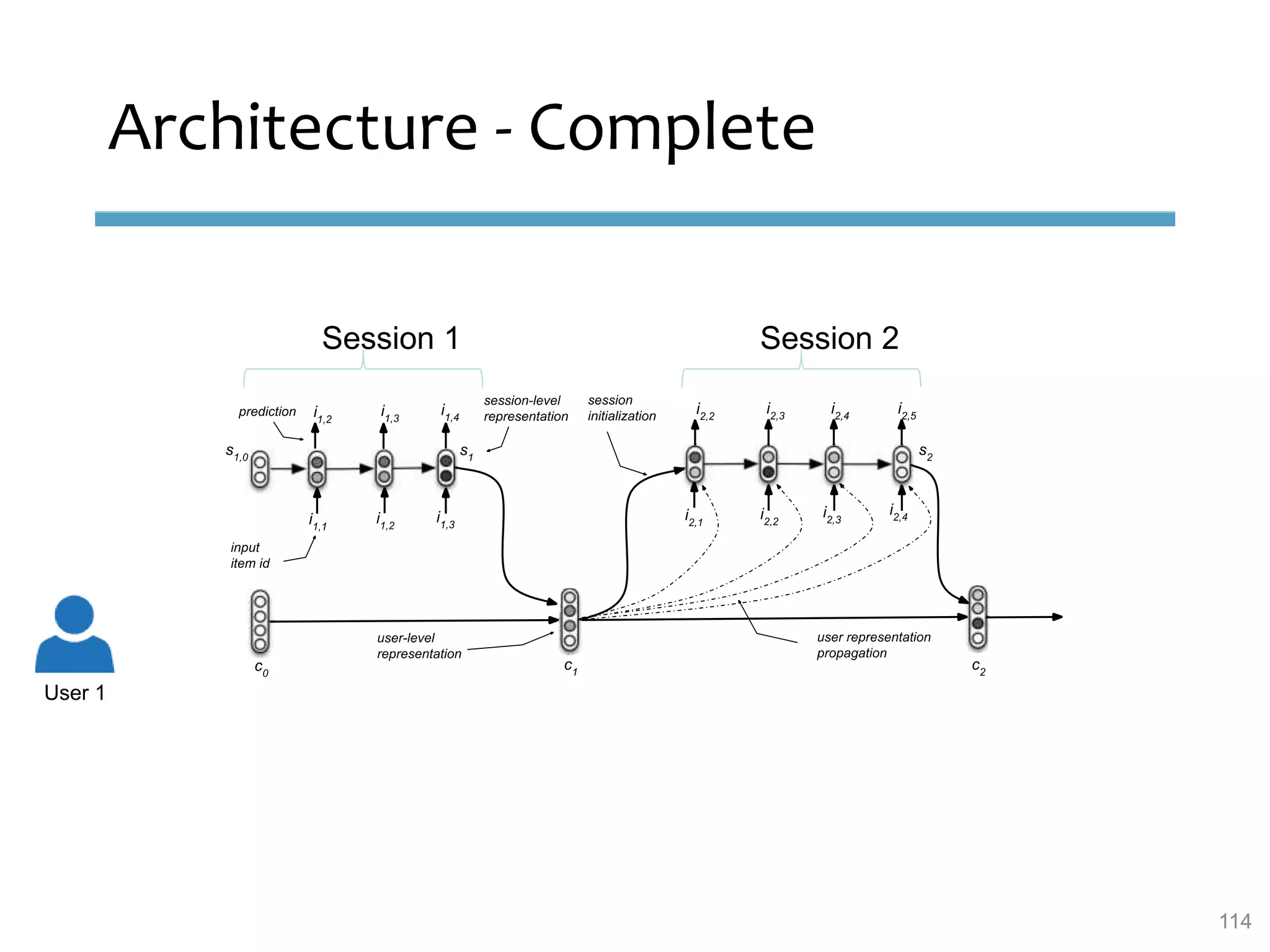
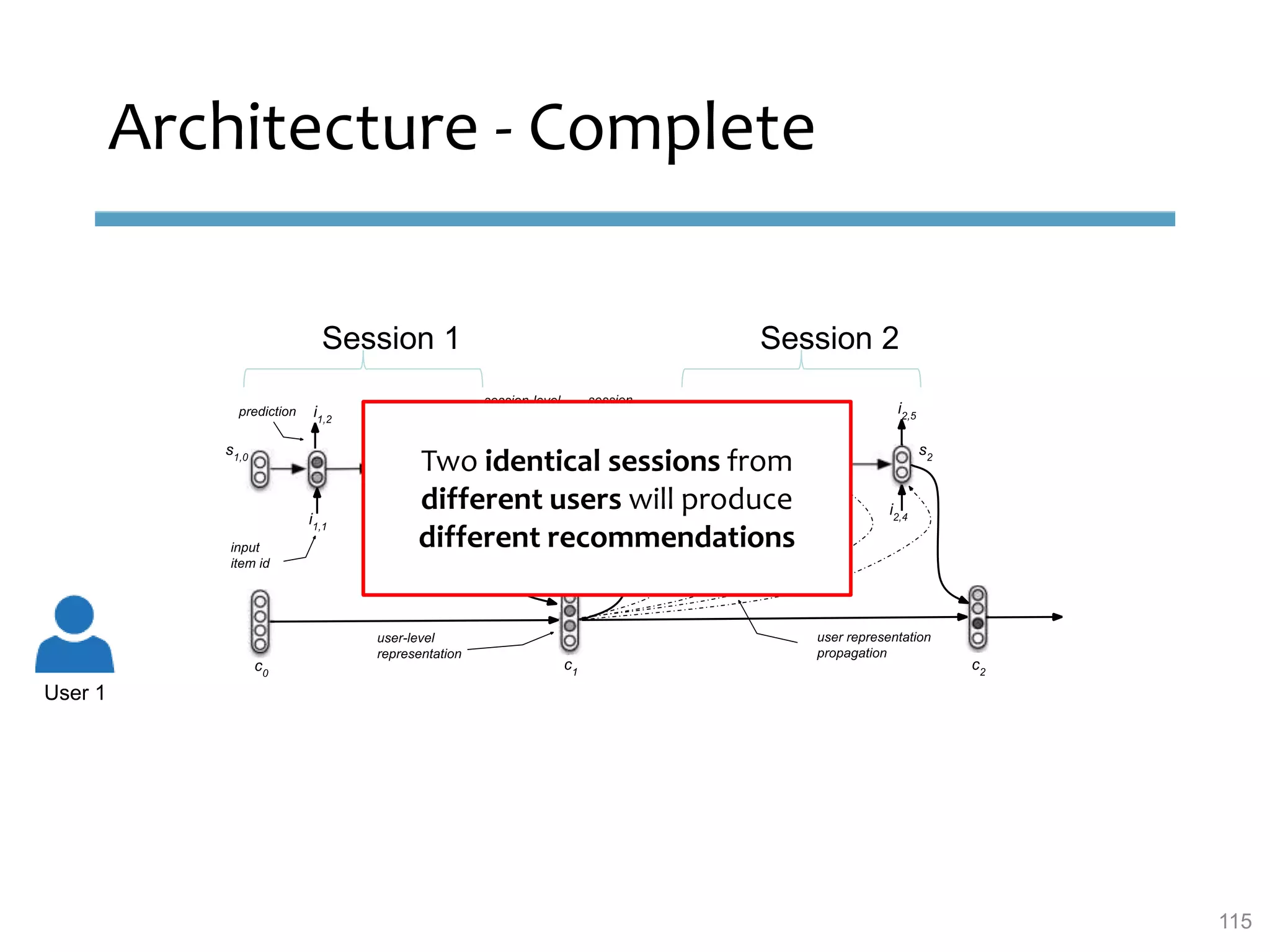
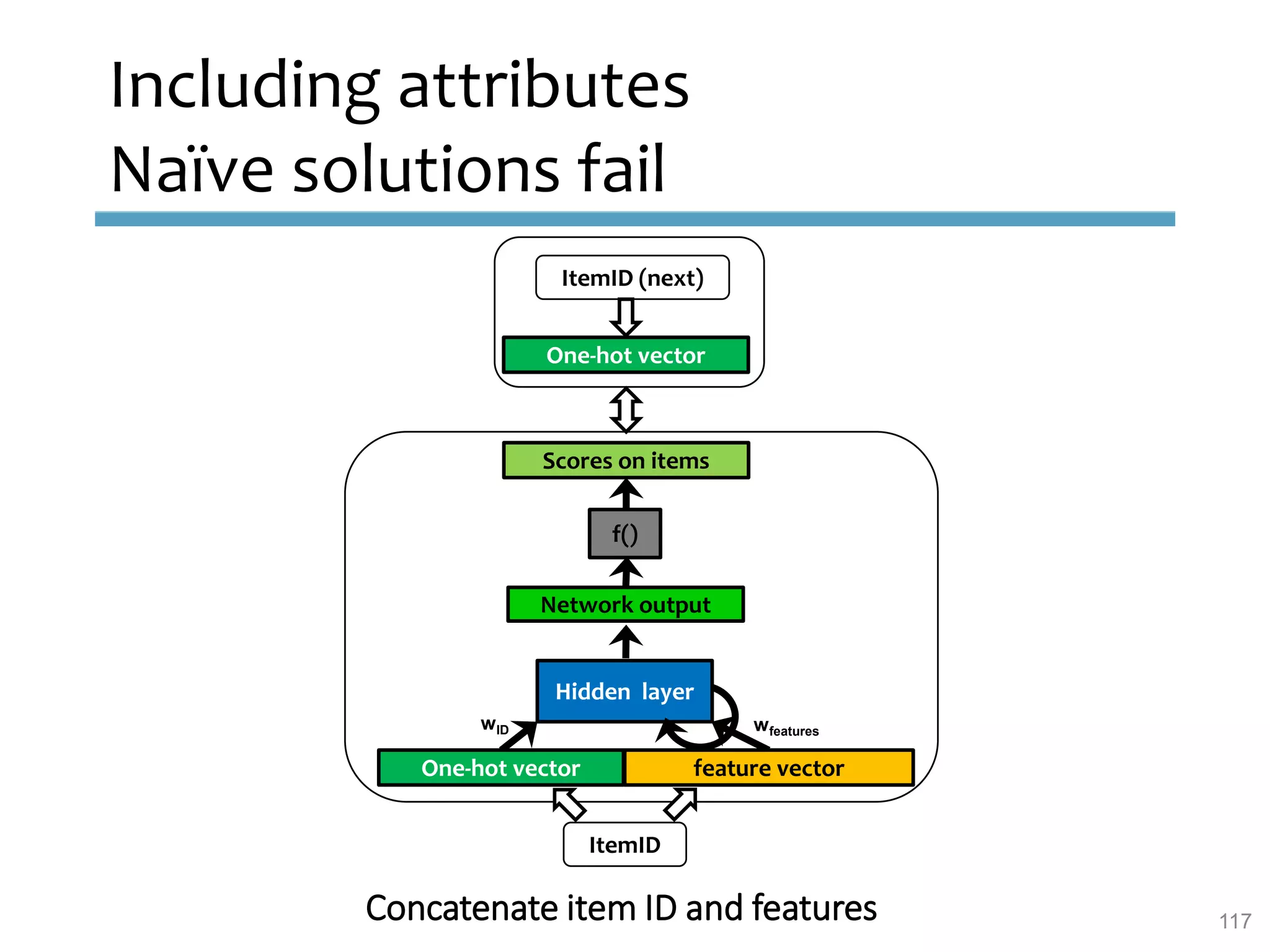
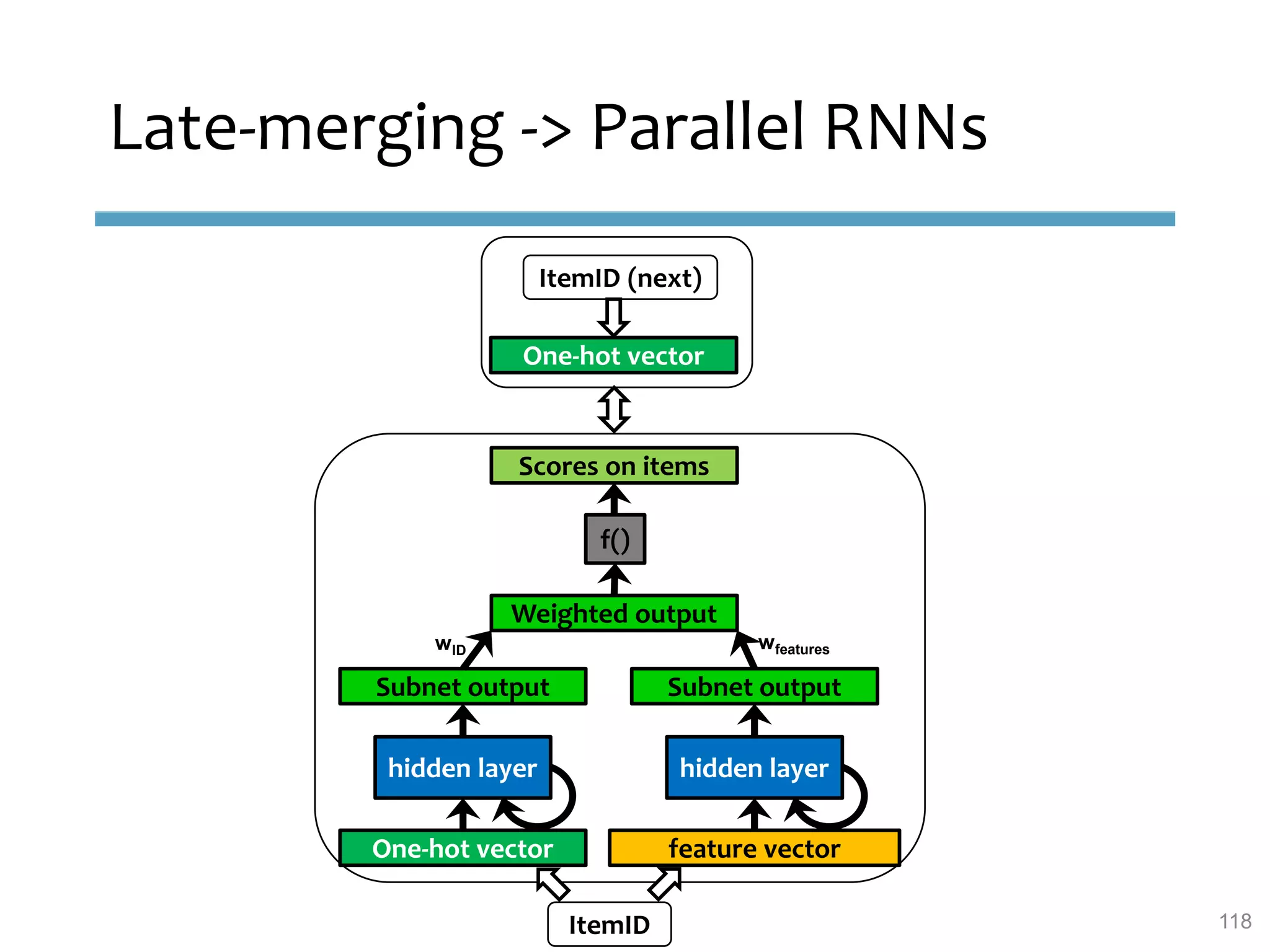
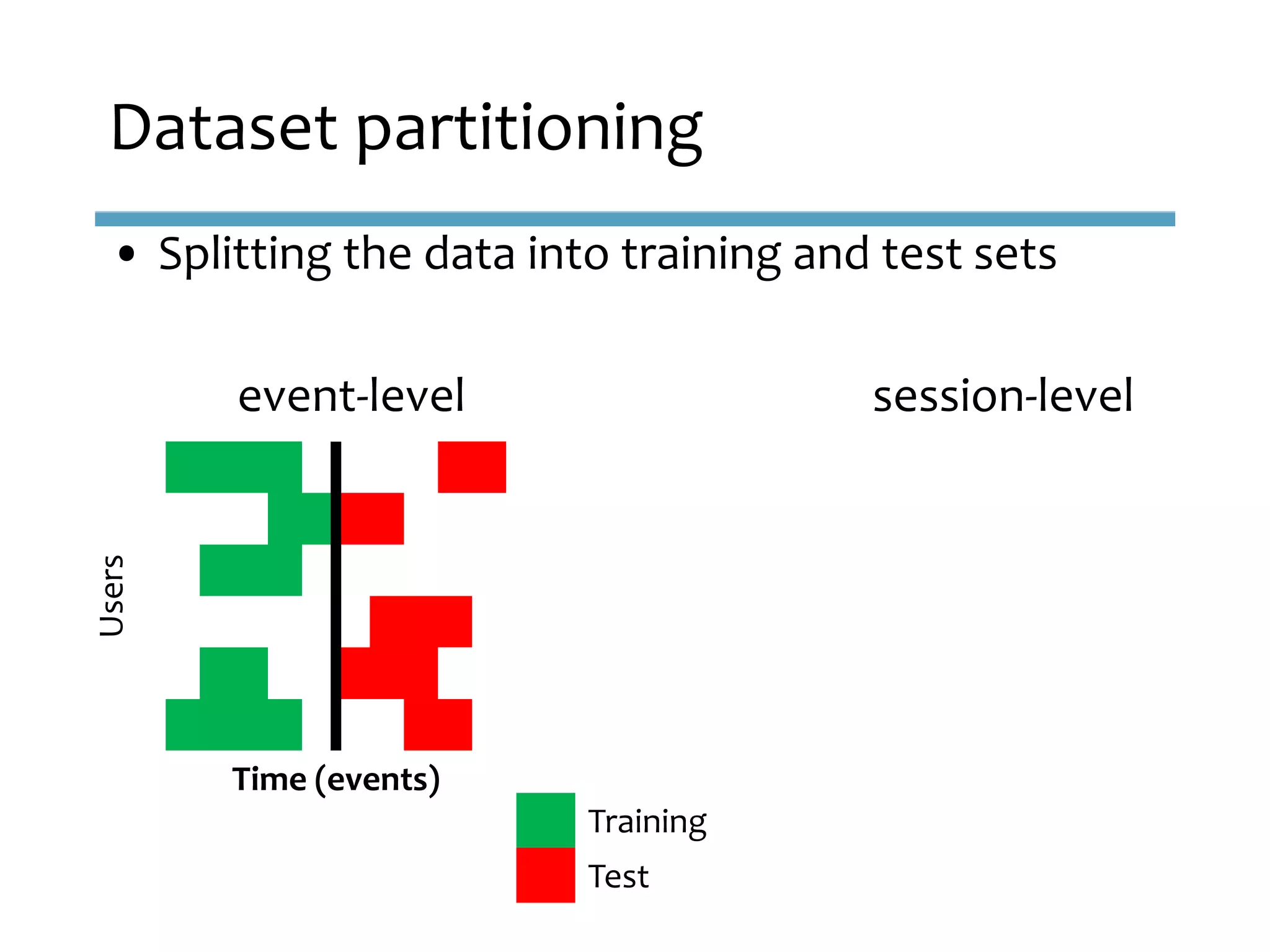
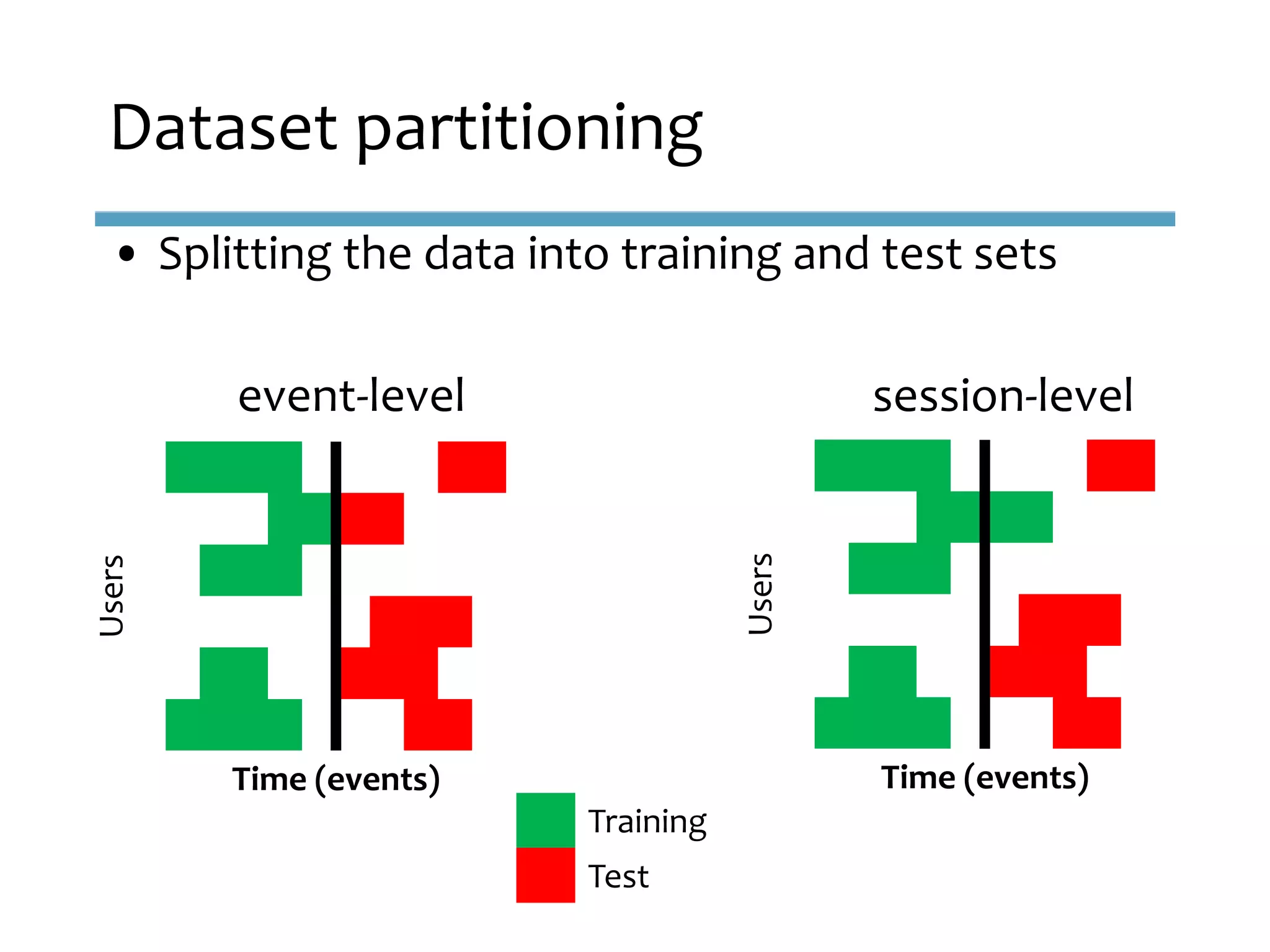
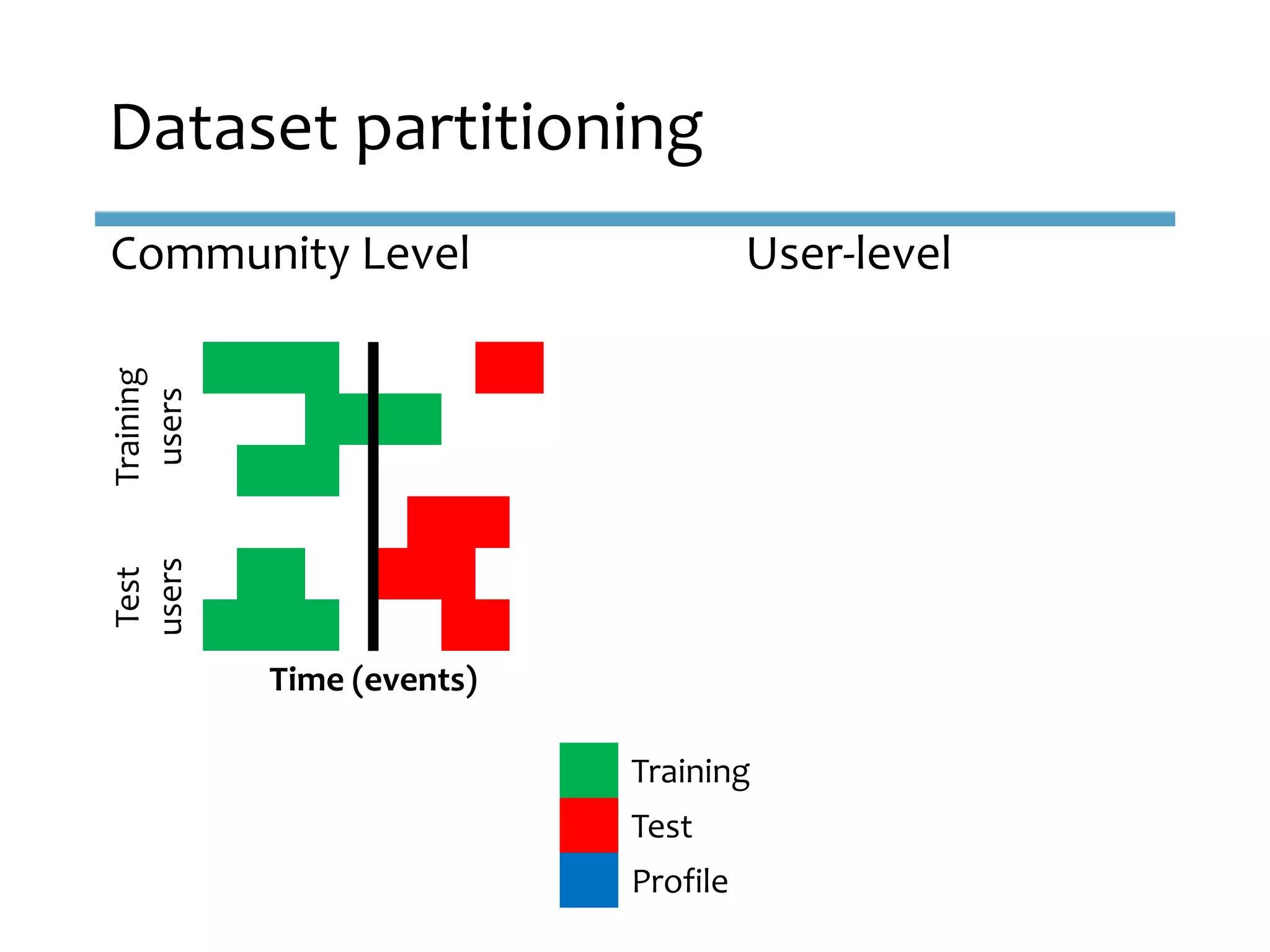
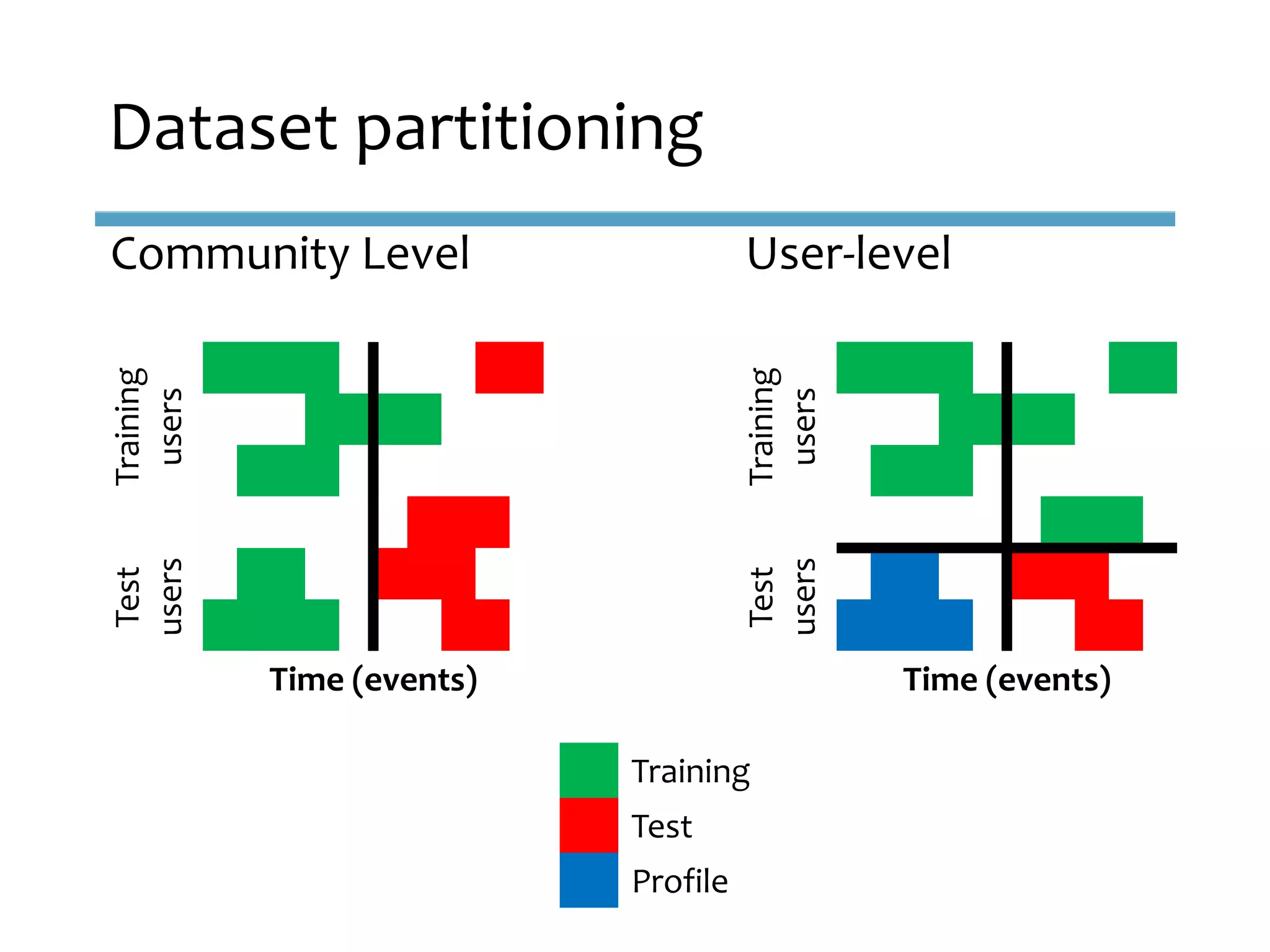
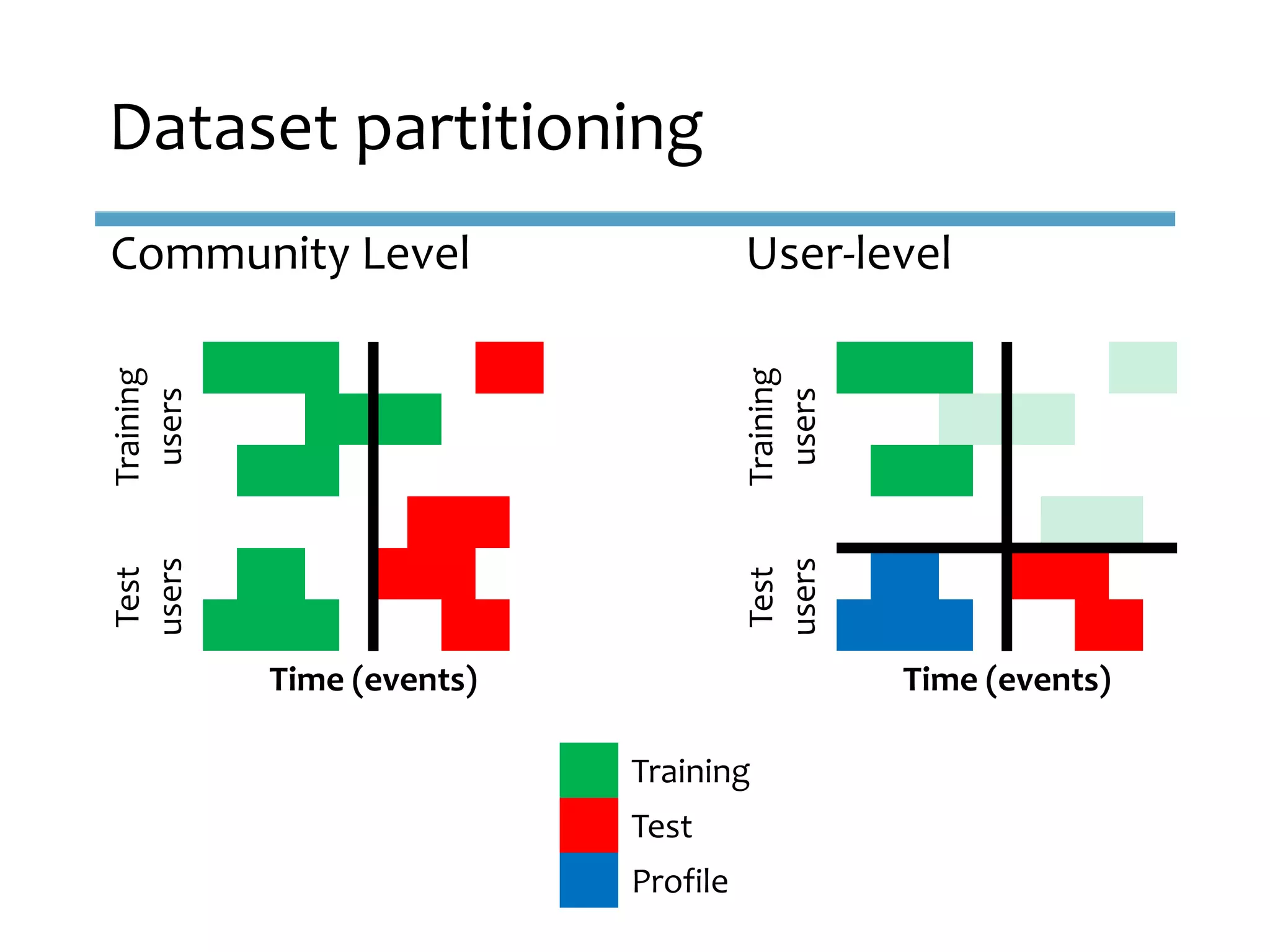
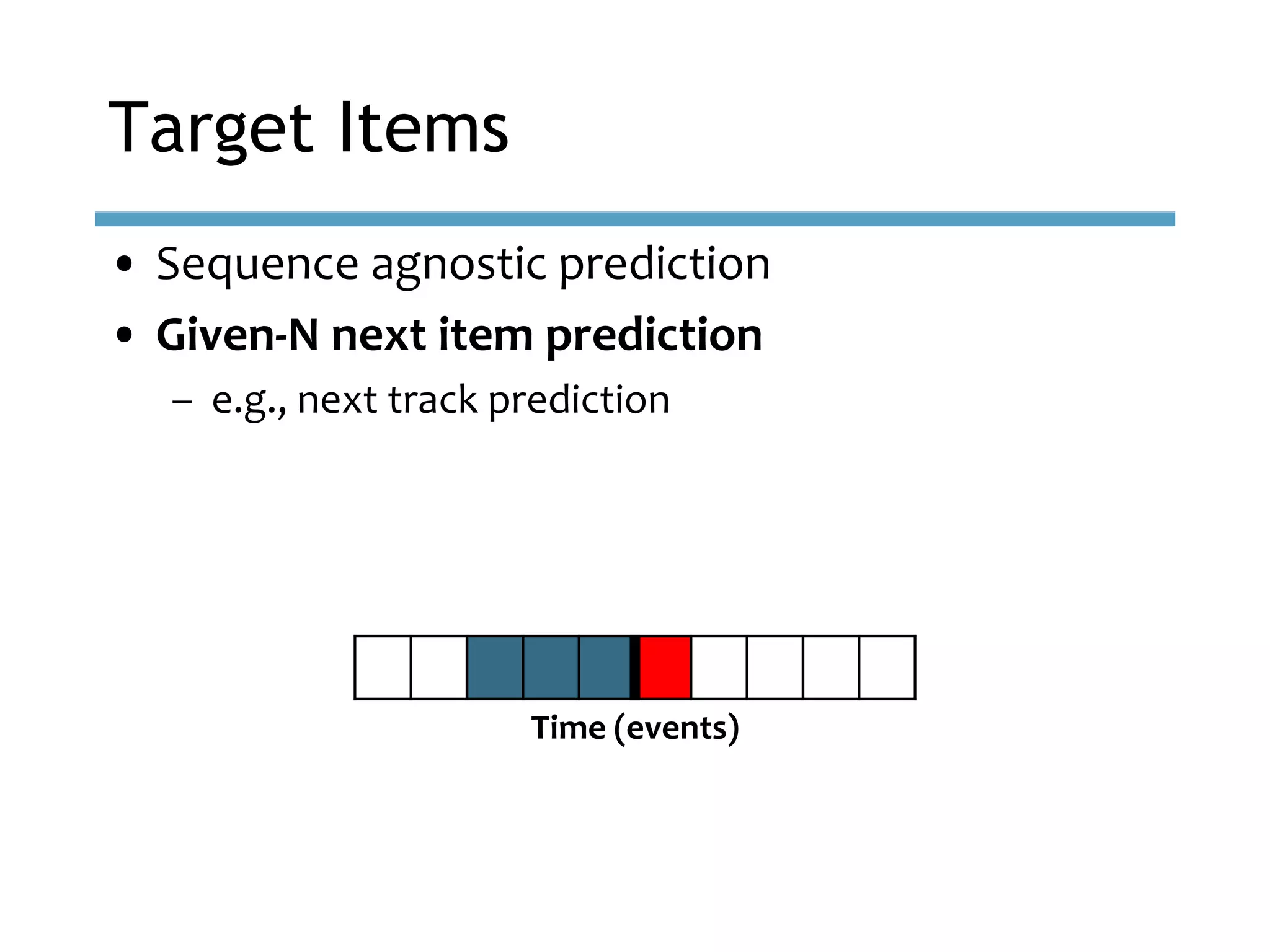
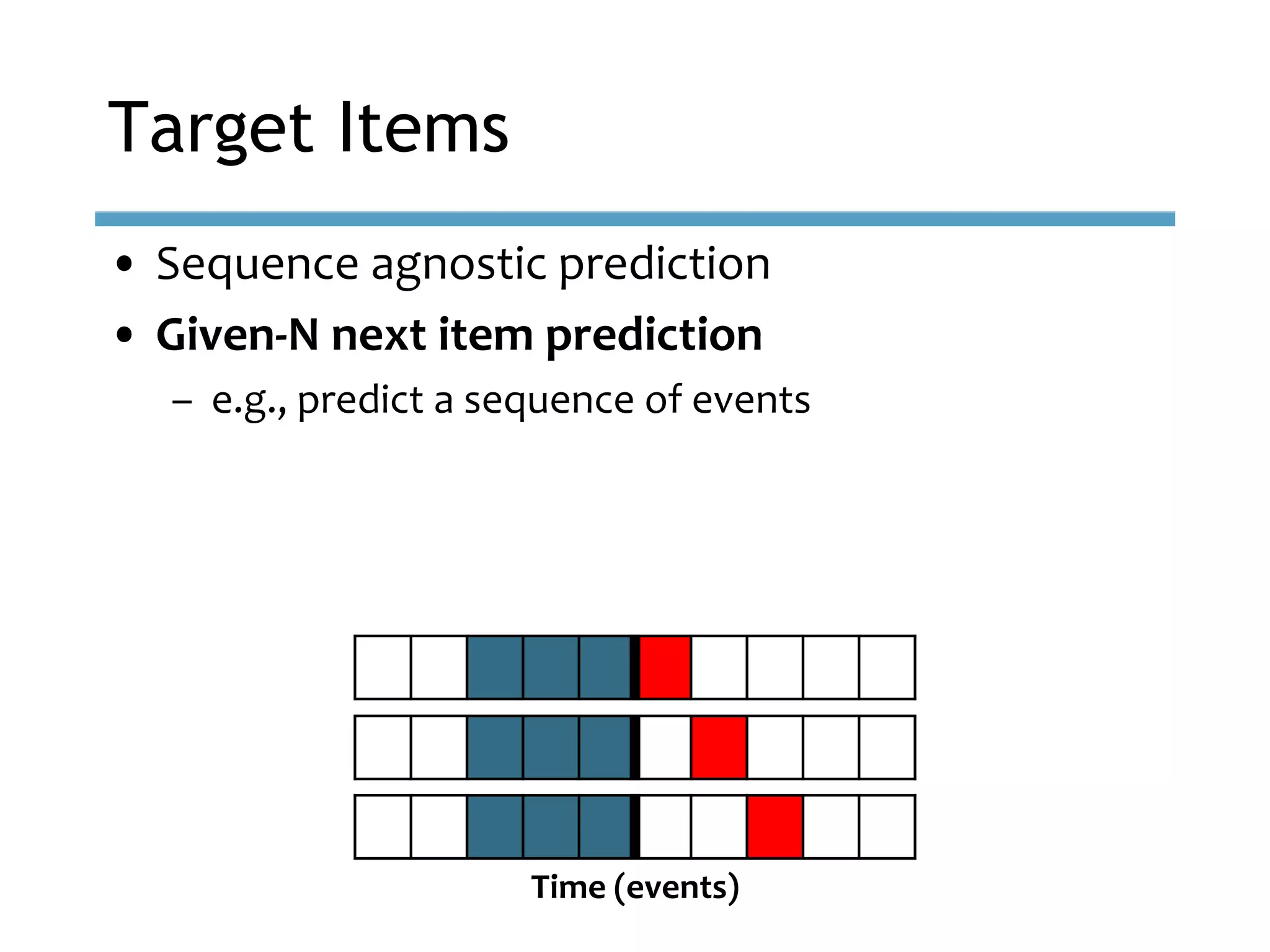
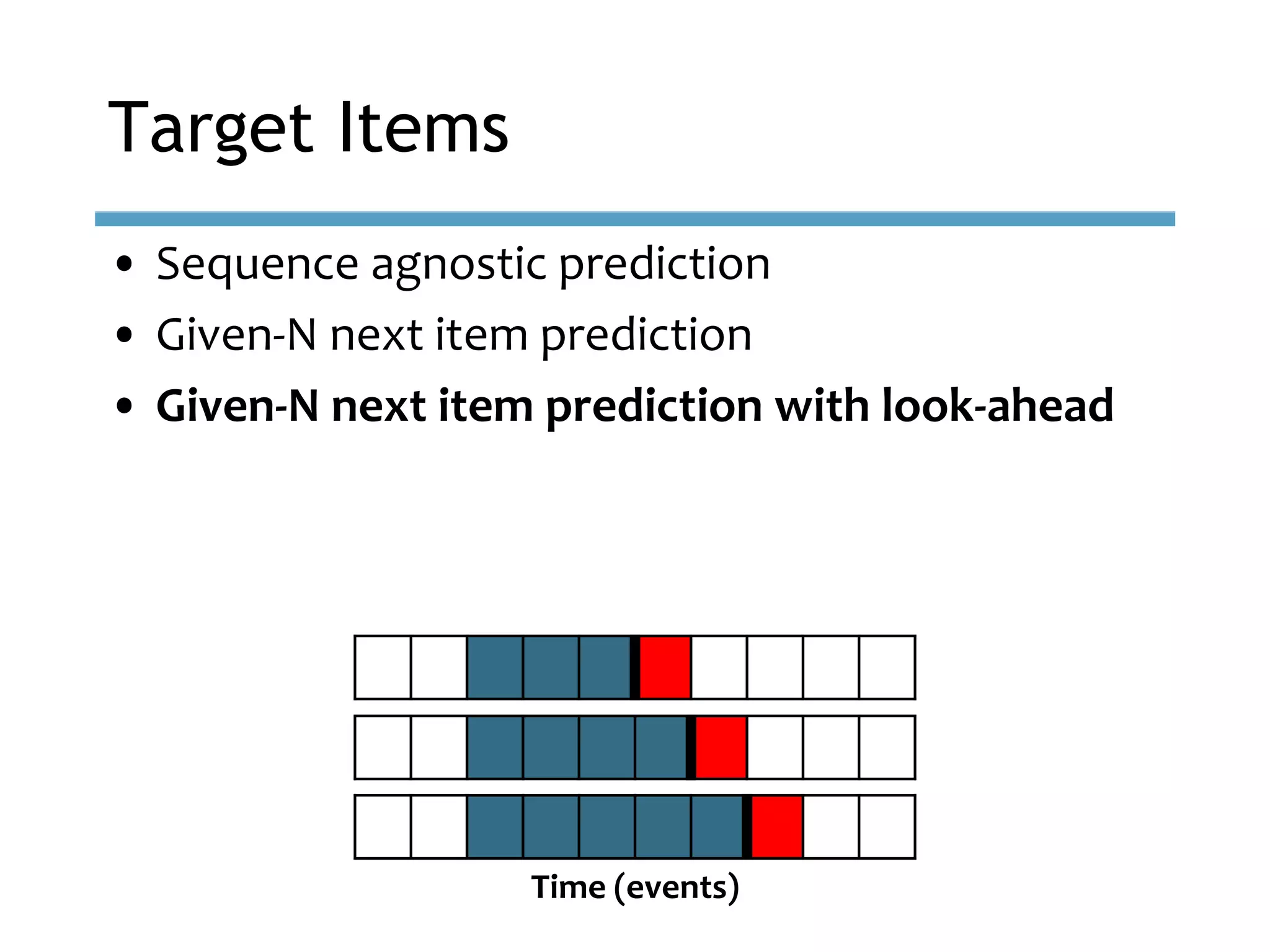
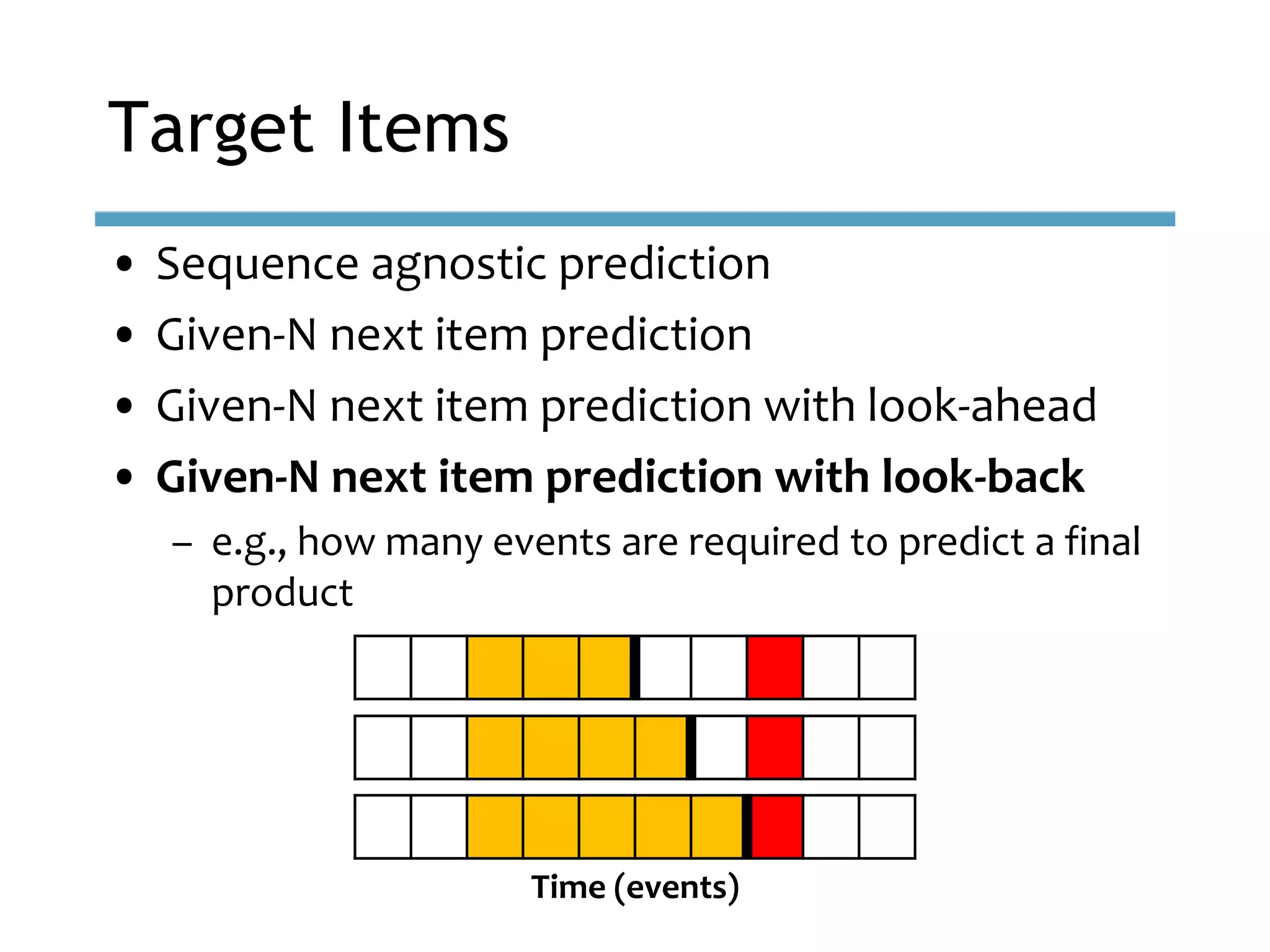
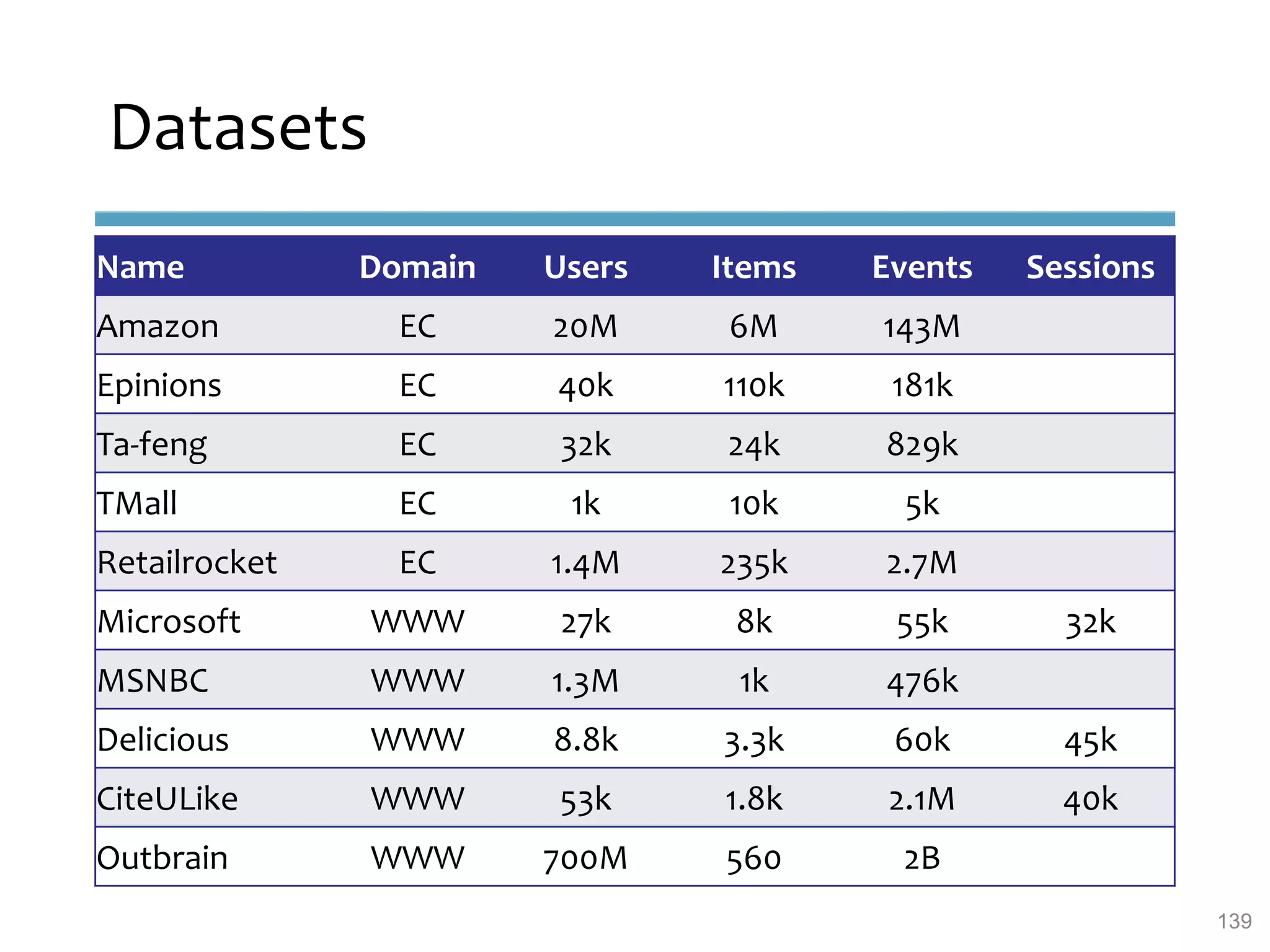
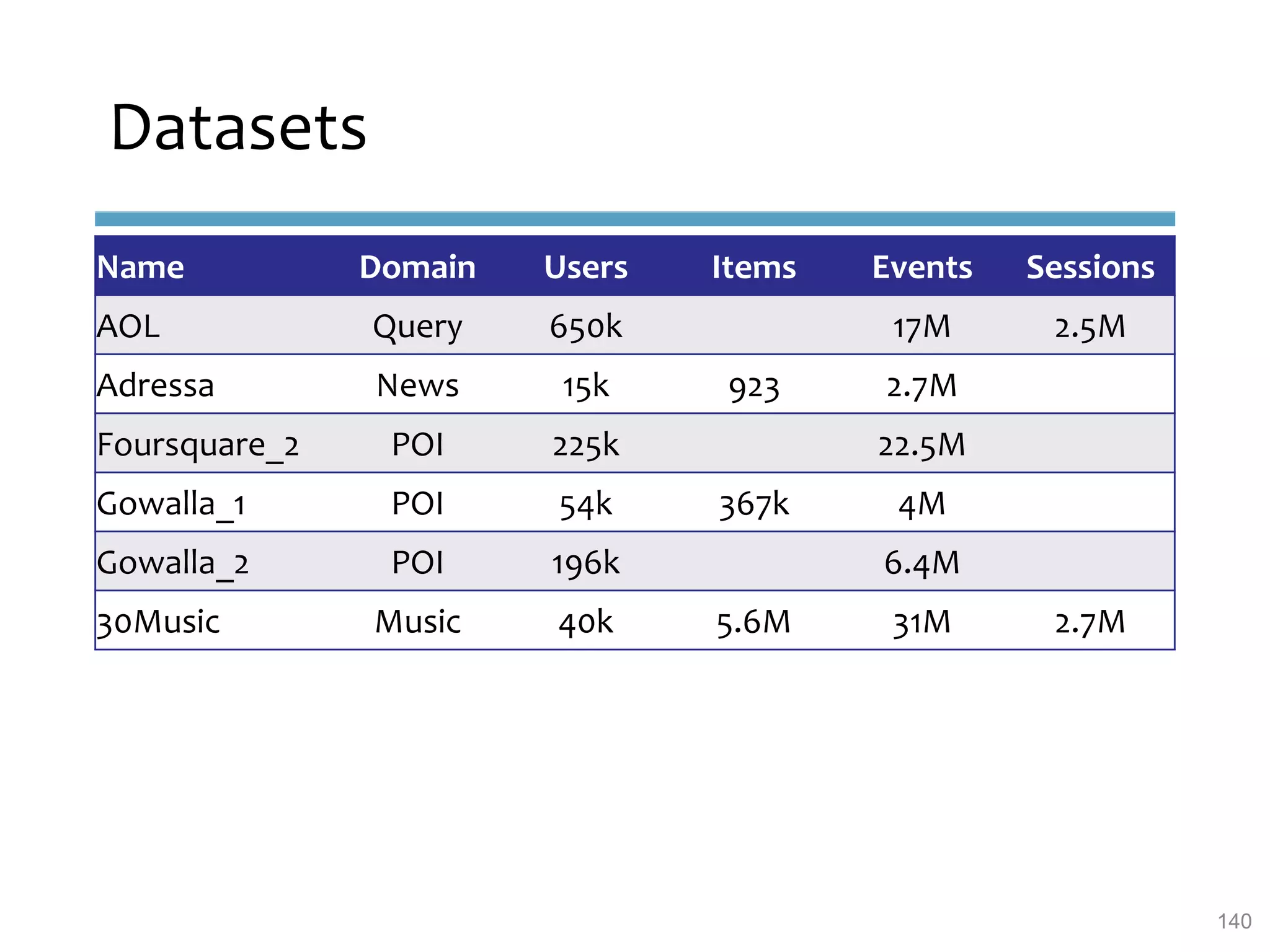
This document provides an overview of sequence-aware recommender systems. It discusses how sequence-aware recommenders differ from traditional recommender systems in that they take into account ordered, timestamped sequences of user actions and interactions rather than single user-item pairs. The document outlines various types of sequence-aware recommendation problems such as context adaptation, trend detection, repeated recommendations, and considering sequential patterns and order constraints. It also reviews existing algorithmic approaches for sequence-aware recommendations, which include sequence learning techniques like frequent pattern mining and sequence modeling, as well as hybrid methods.































































































































![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
