Downloaded 22 times






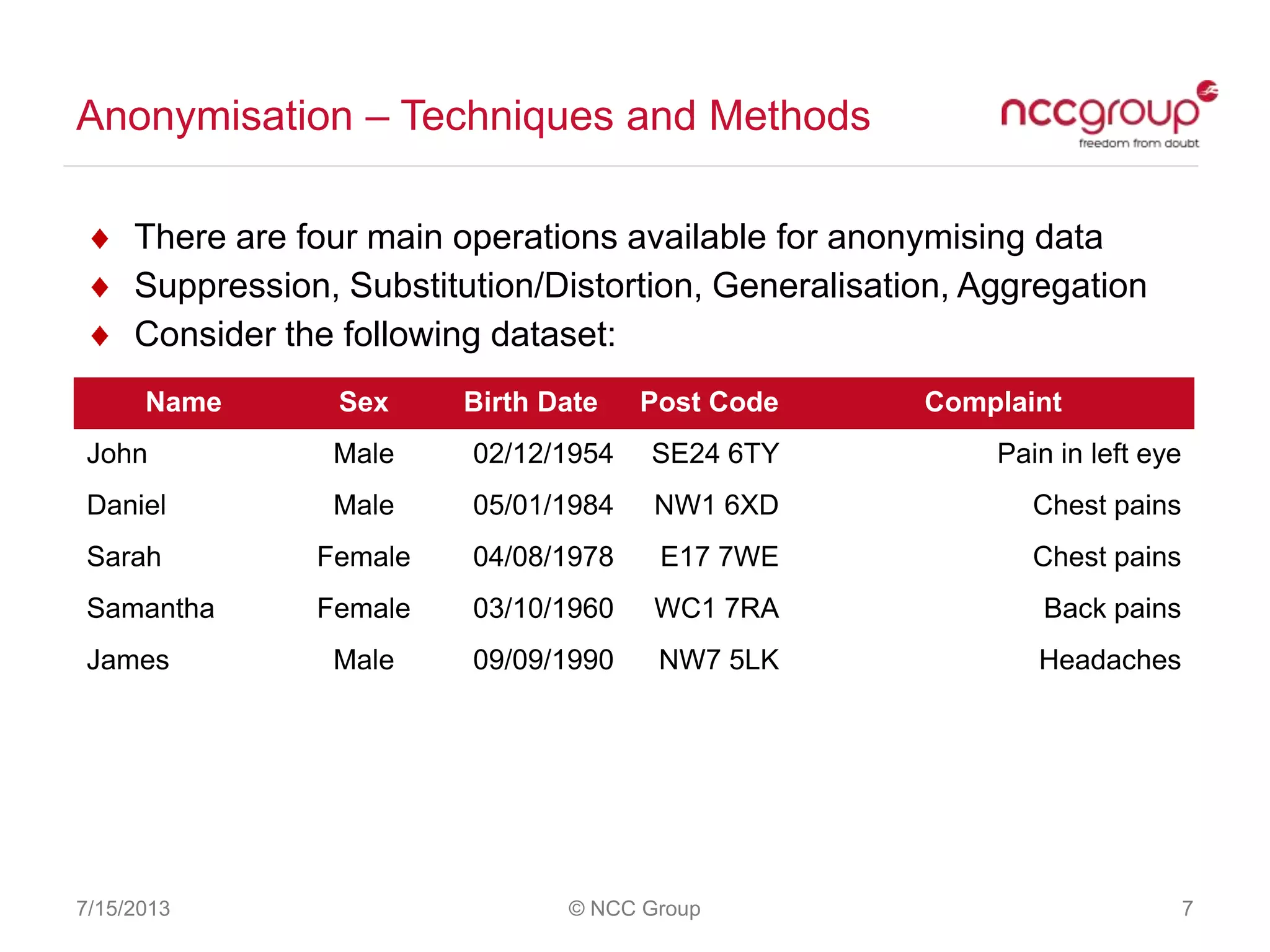

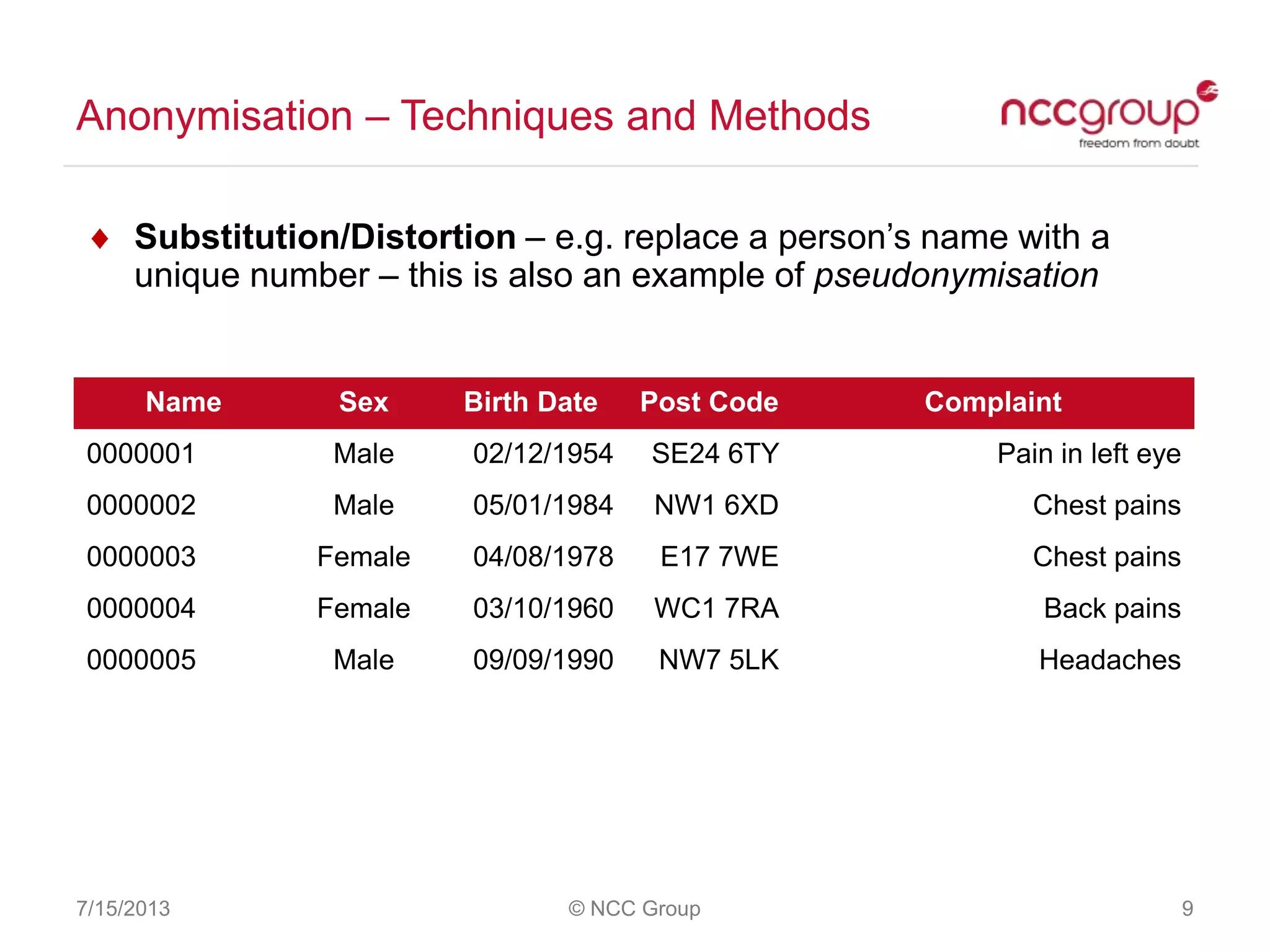
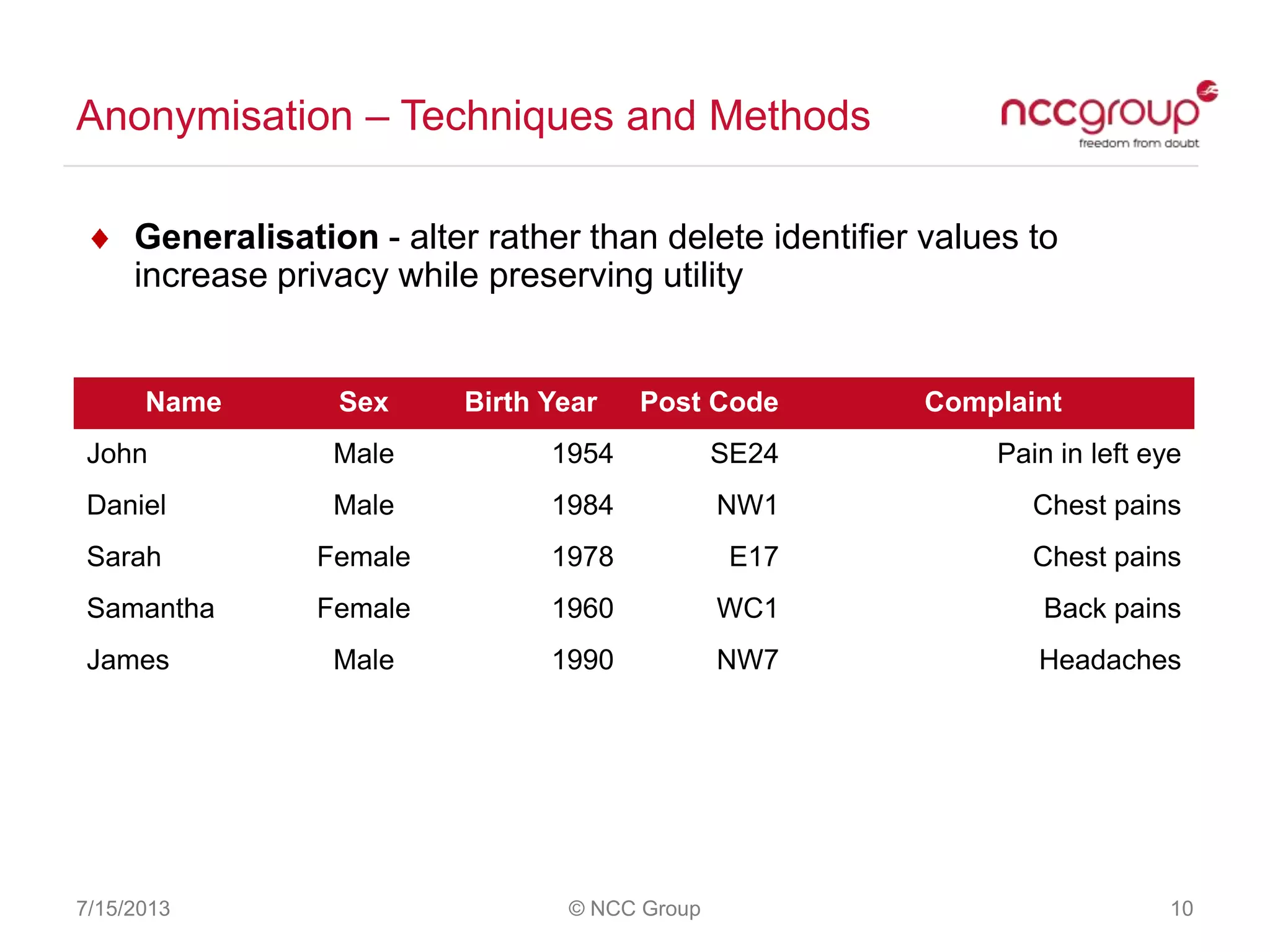
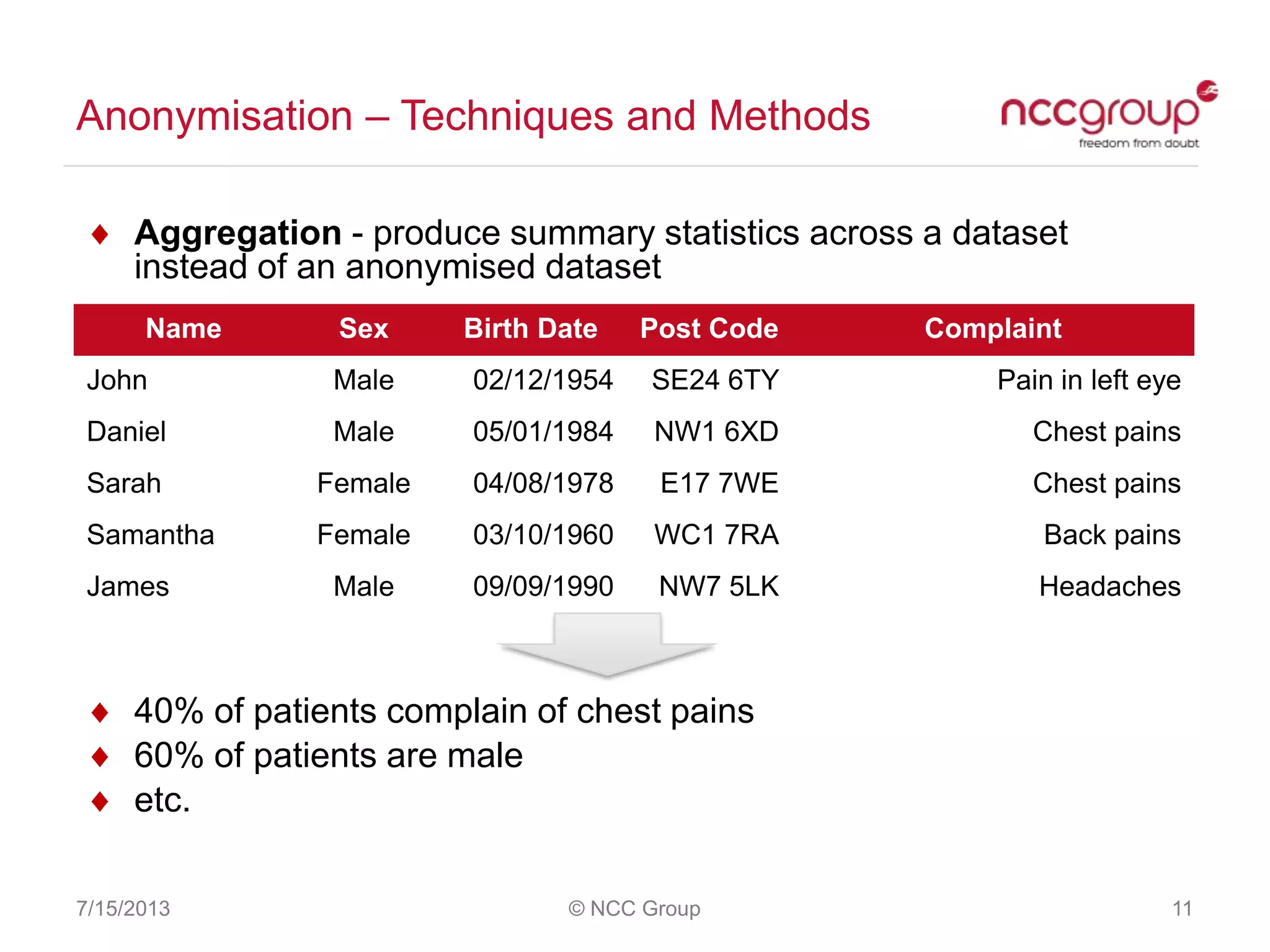




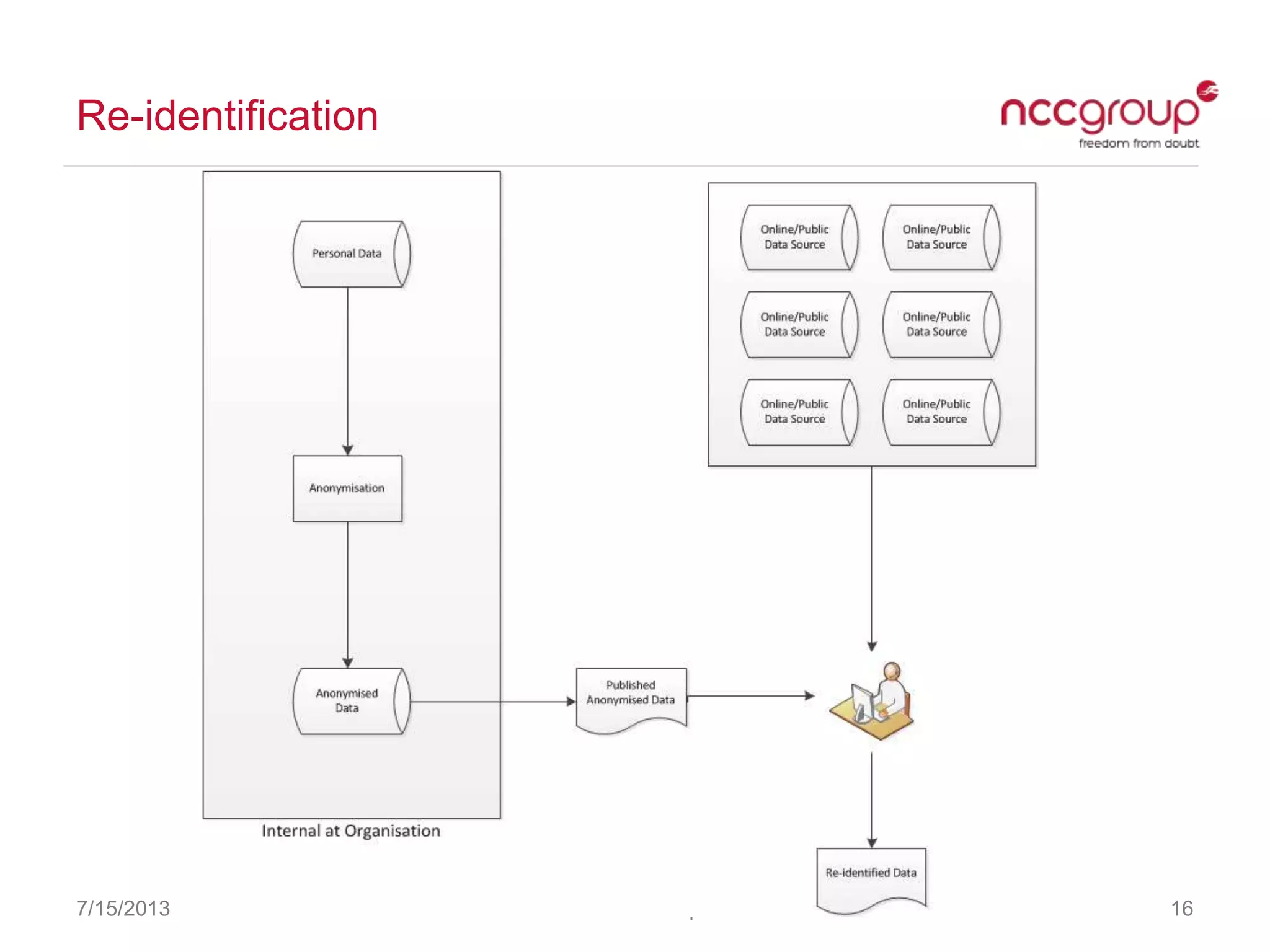
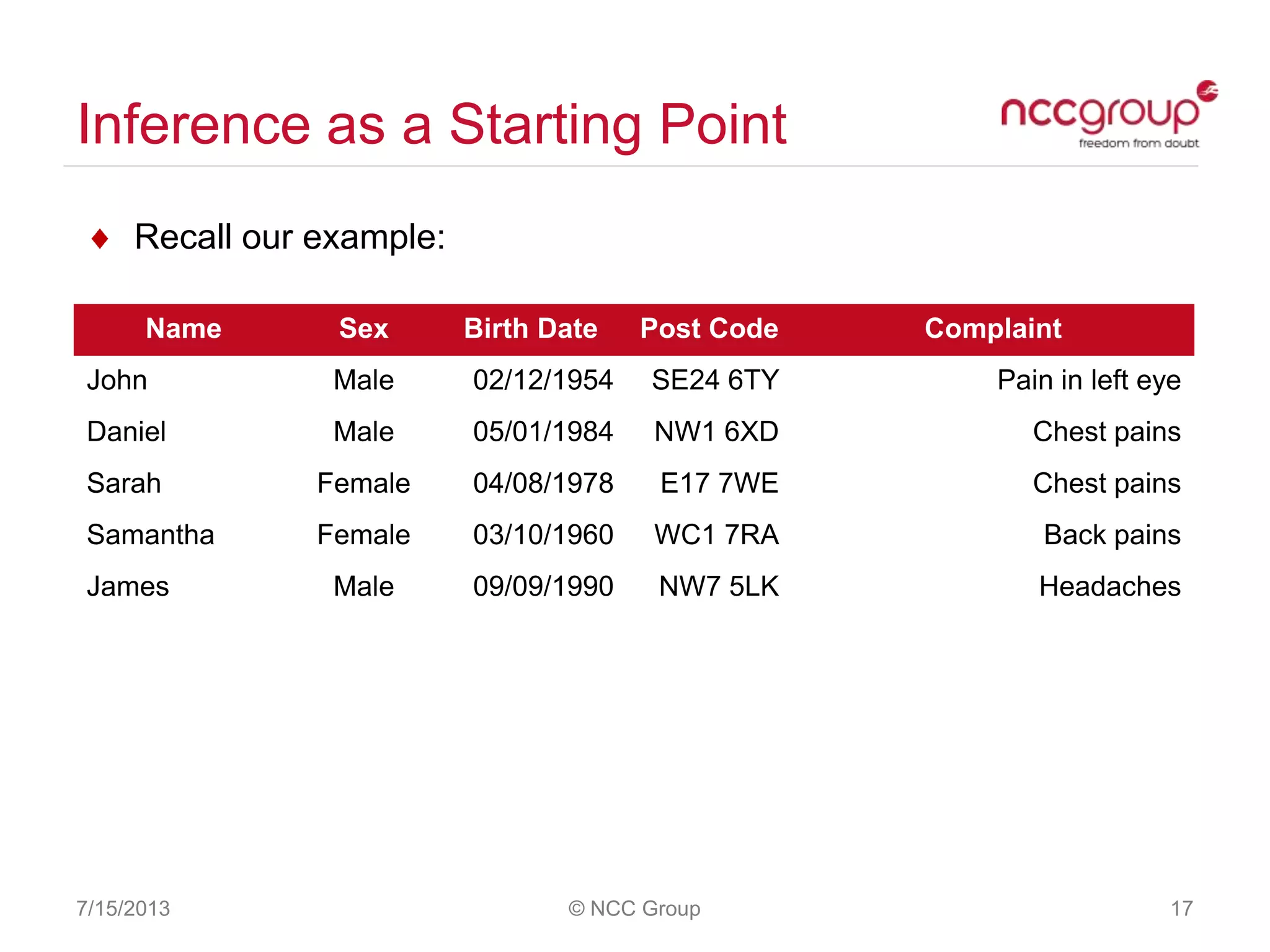



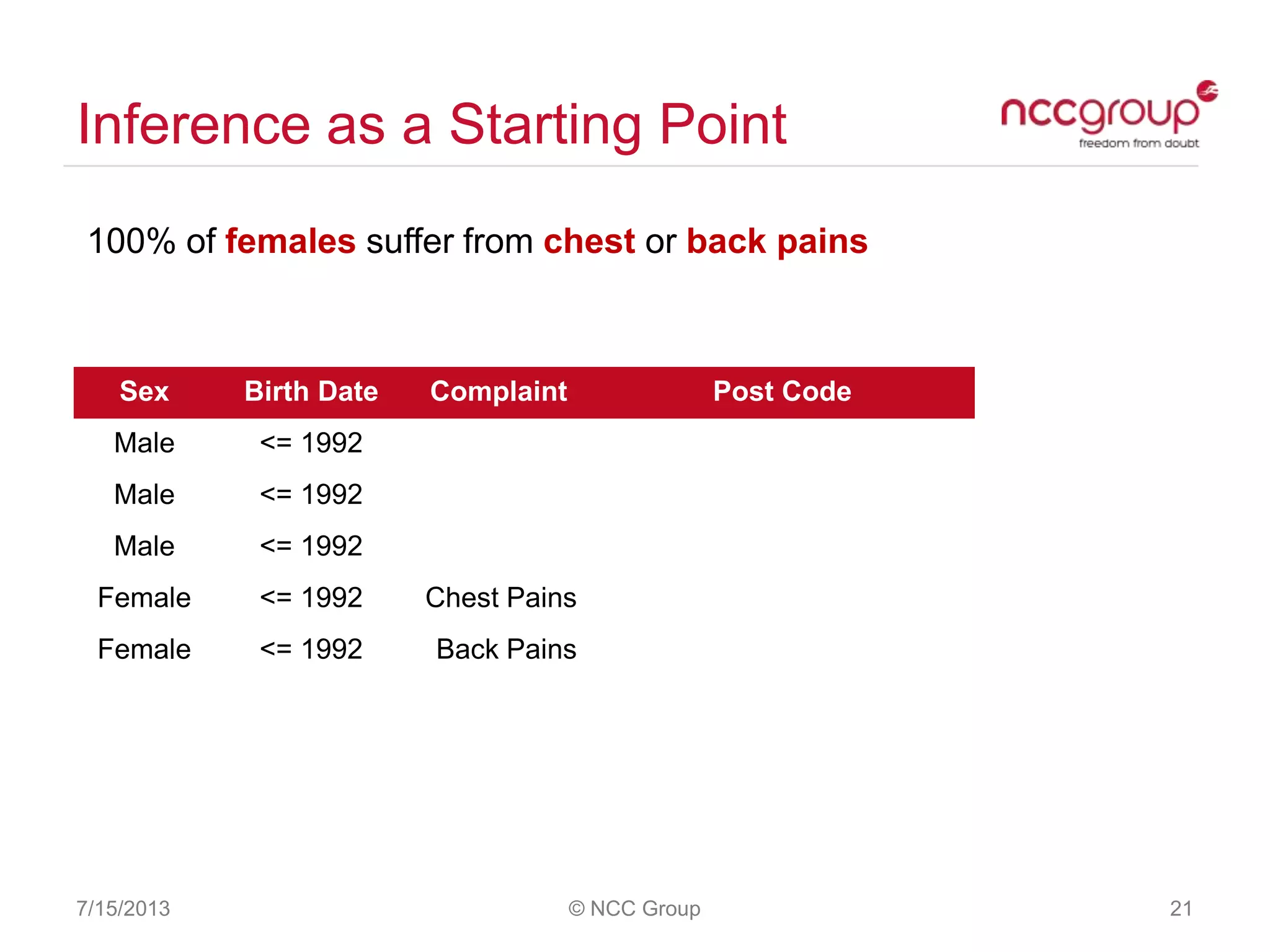
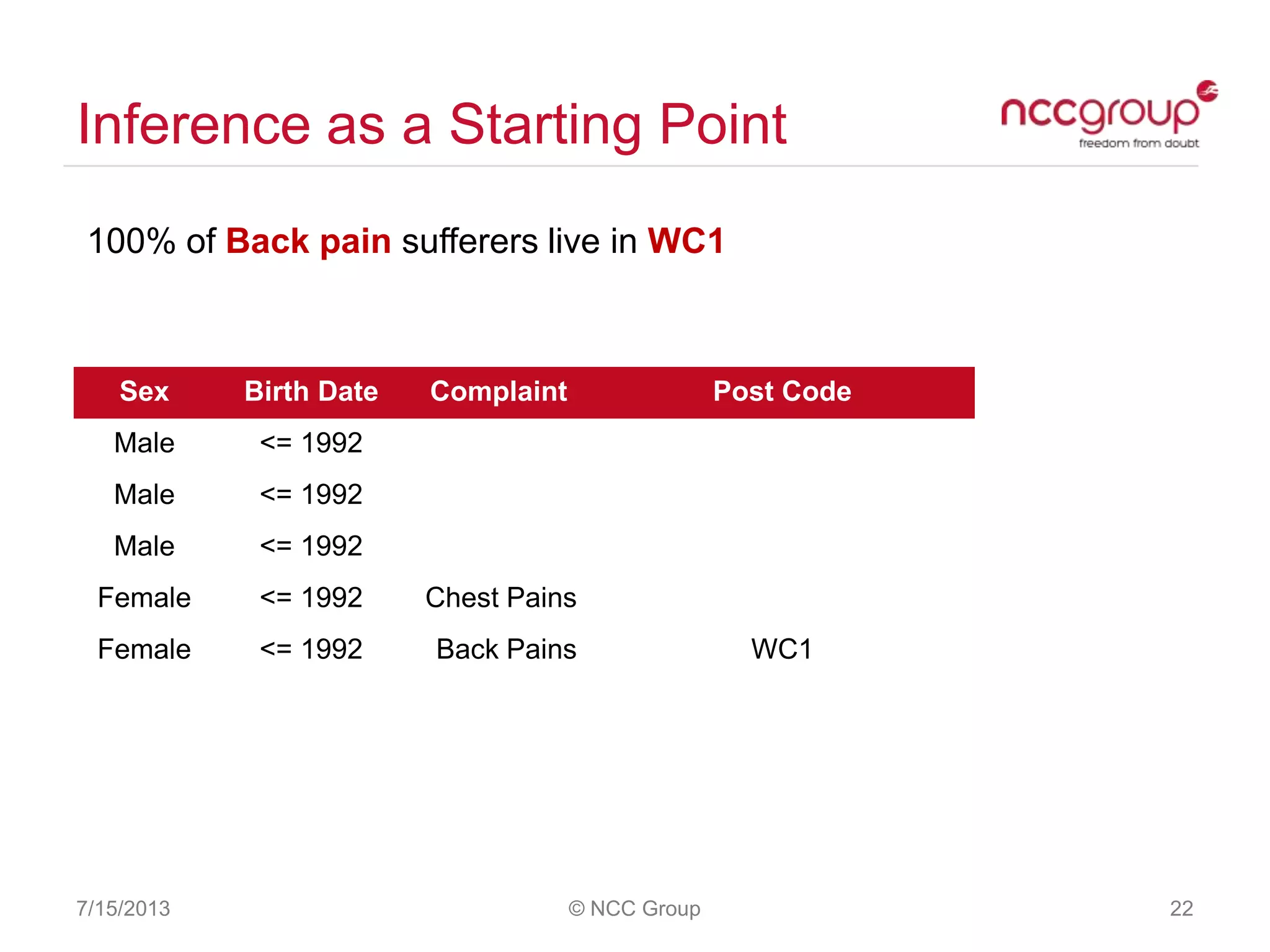
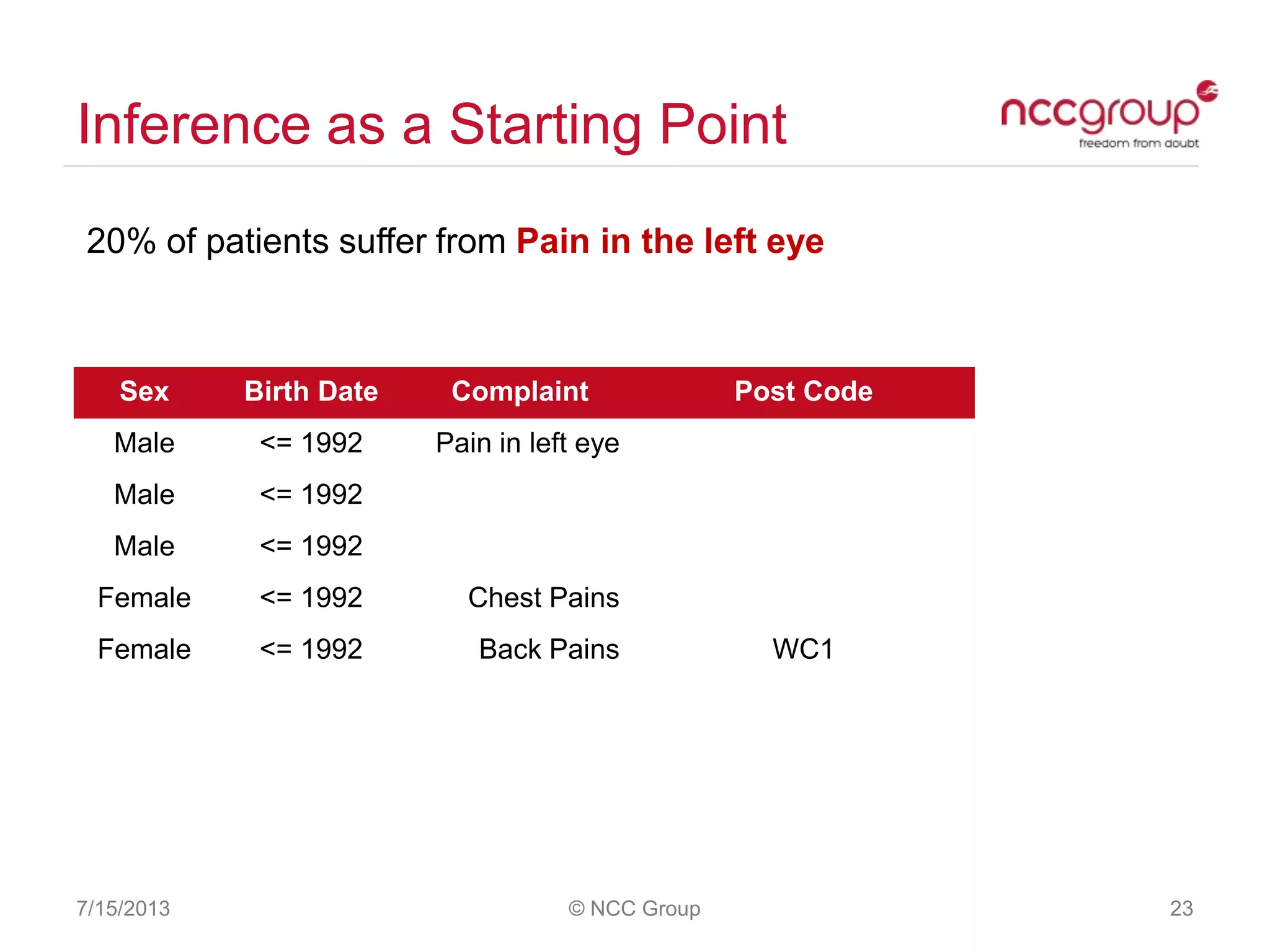


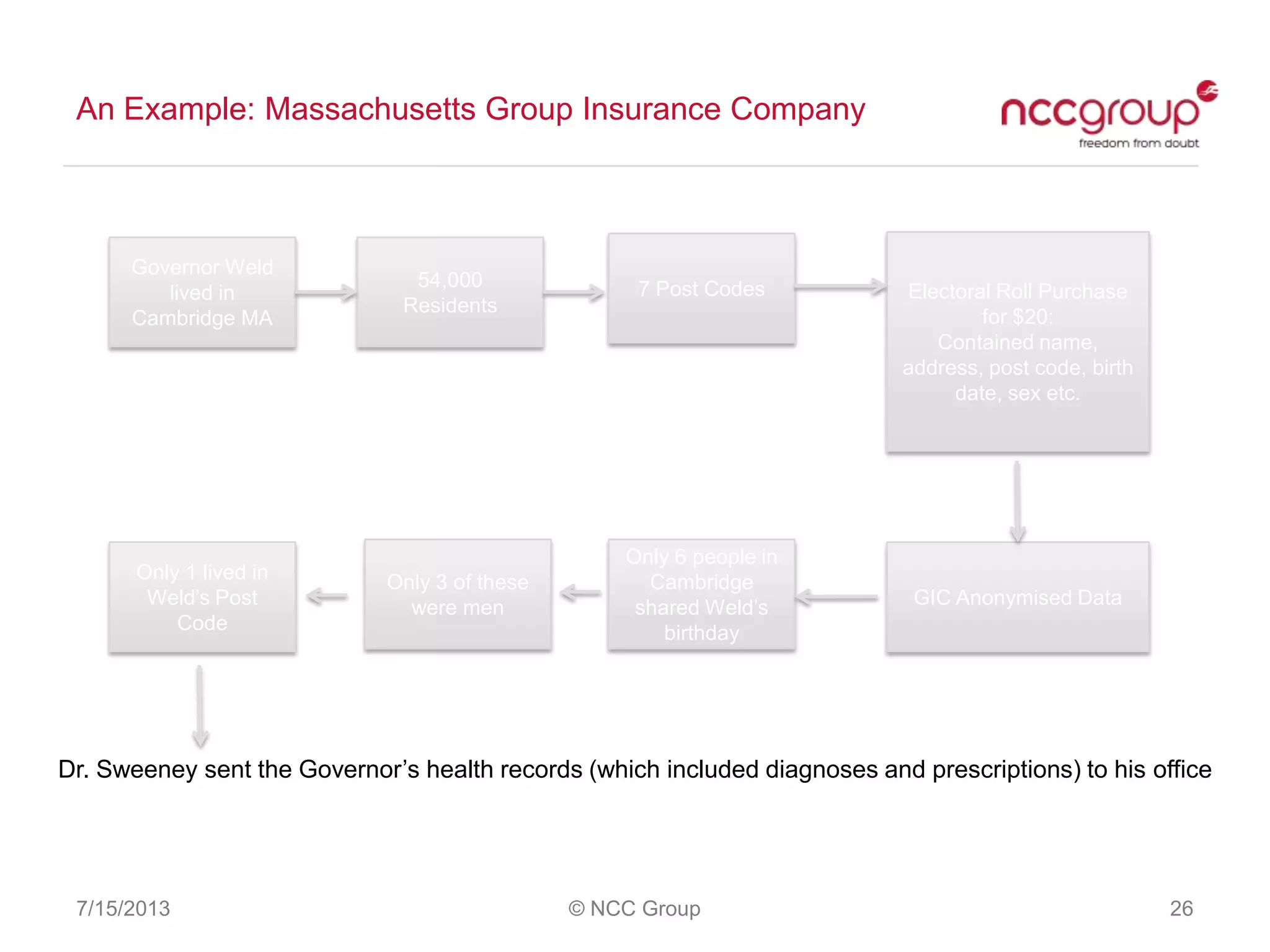




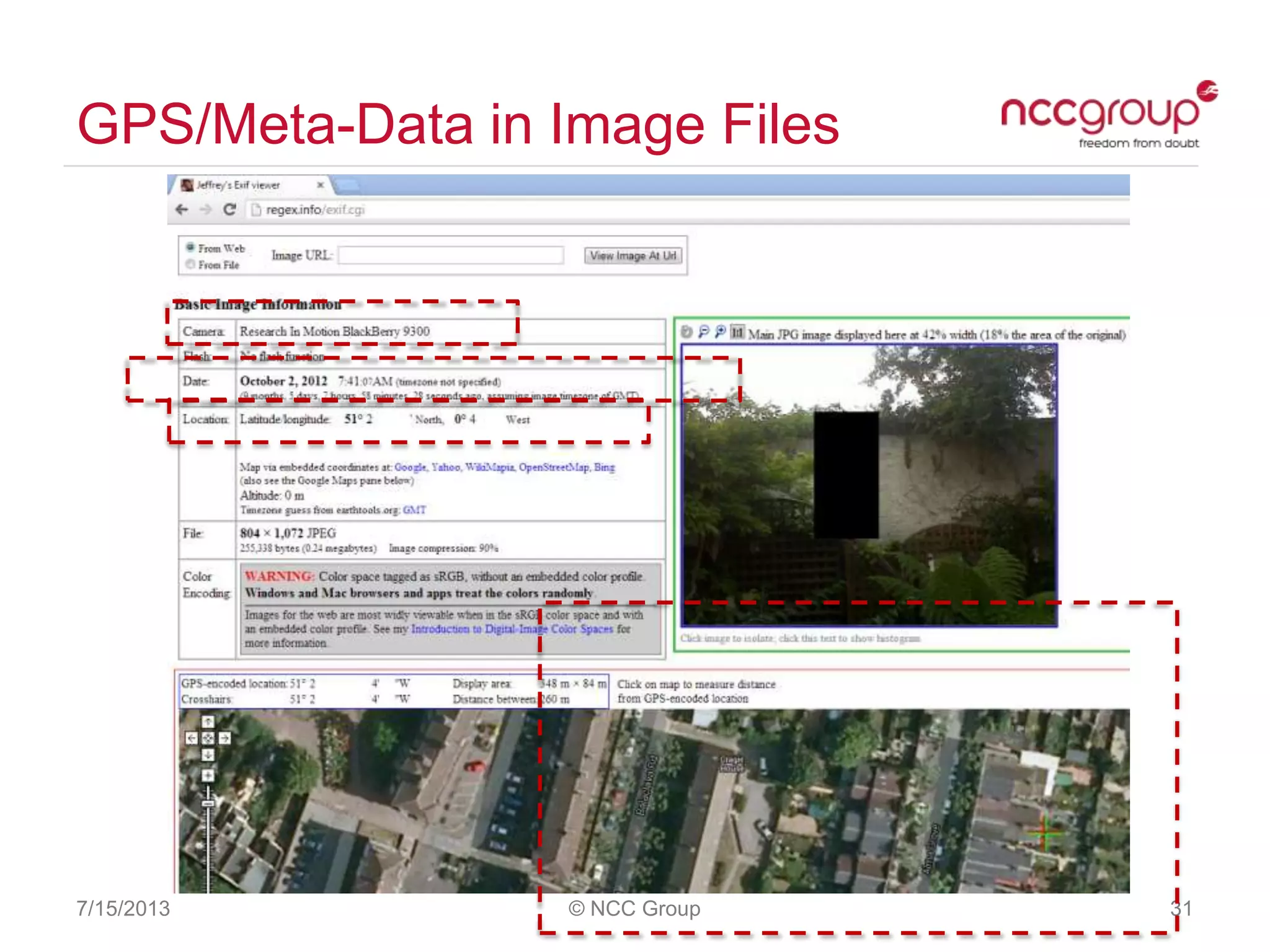
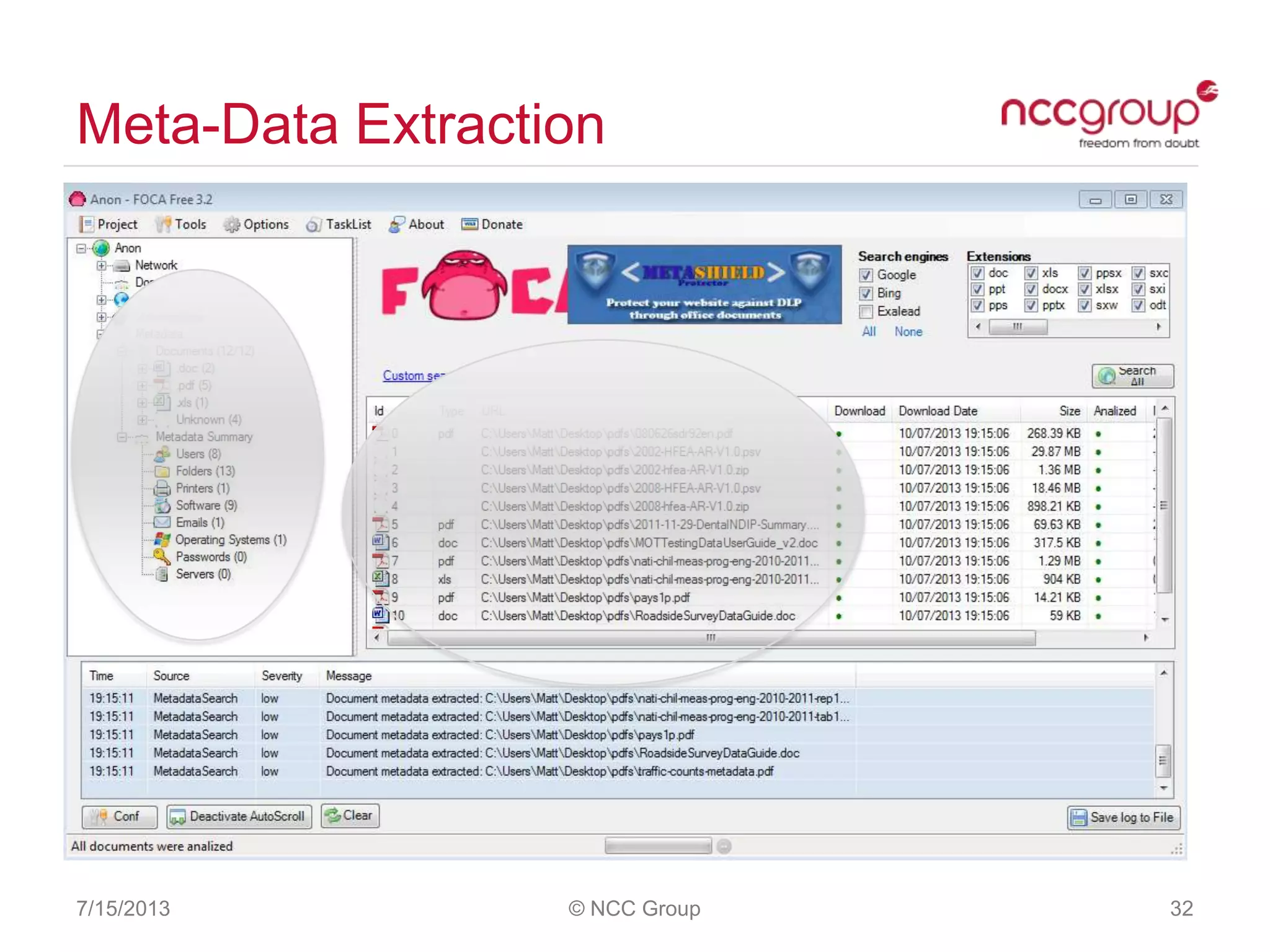







The document discusses anonymization and pseudonymization of data, including the risks of re-identification. It provides examples of when anonymization failed, such as a case where a governor's medical records were re-identified. The presentation recommends a risk-based approach to anonymization and provides tips to mitigate risks, such as consulting experts and protecting metadata. It emphasizes that anonymization is not an exact science and re-identification is still possible if the right data is available.



























































