Download as PDF, PPTX










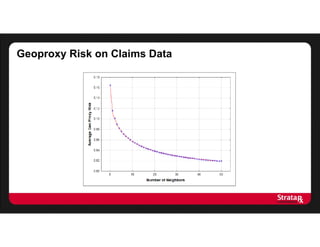
![Average Risk
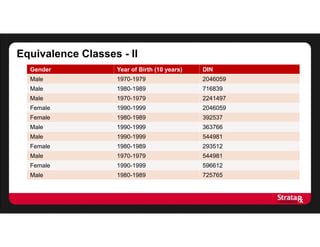
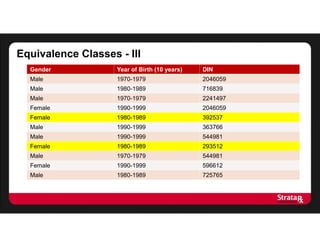
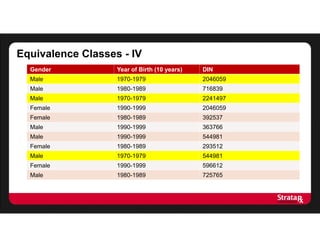
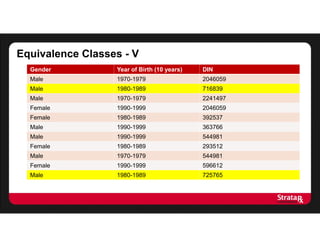
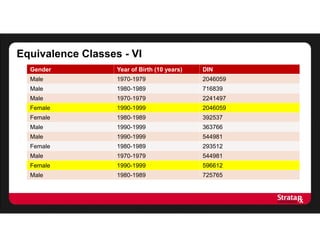
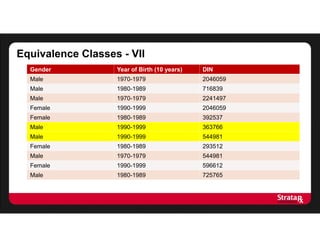
There were:
- Four equivalence classes of size 2
- One equivalence class of size 3
The average risk is:
[(8 x 0.5) + (3 x 0.33)]/11
= 5/11
This gives us an average risk of 5/11, or 45%
This turns out to be the number of equivalence classes divided by the
number of records](https://image.slidesharecdn.com/stratarx2013facilitatinganalyticselemamv2-130926162736-phpapp02/85/Facilitating-Analytics-while-Protecting-Privacy-17-320.jpg)





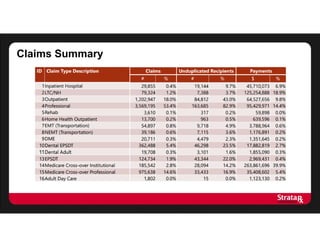
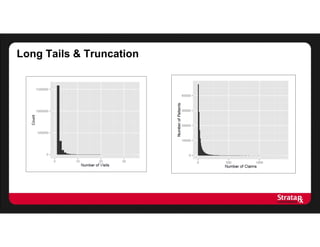


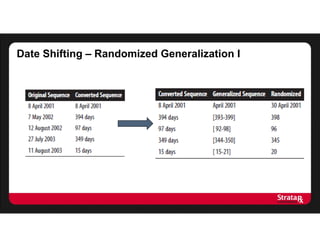





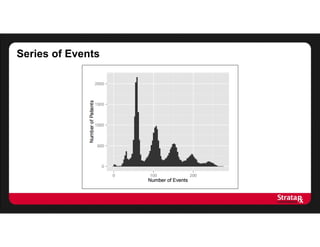







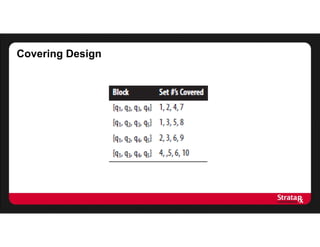
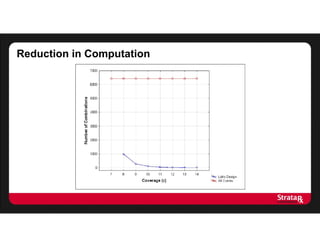


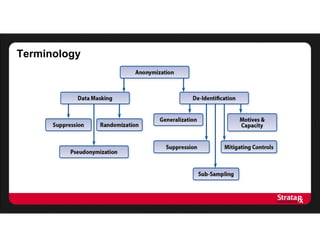
This document summarizes Khaled El Emam's presentation on facilitating analytics while protecting individual privacy using data de-identification. It discusses two case studies where health data was shared after analyzing privacy risks. The first was a project with the Louisiana Department of Health providing de-identified Medicaid claims data for a coding competition. The second was sharing data from Mount Sinai School of Medicine's World Trade Center Disaster Registry. The presentation outlines the methodology used to de-identify the data, including removing direct identifiers, generalizing quasi-identifiers, and techniques like date shifting to prevent re-identification.









































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)












