Downloaded 40 times




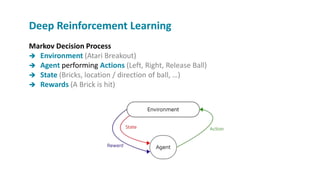

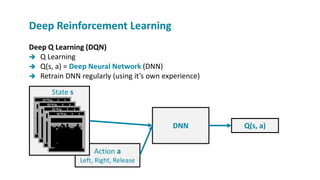






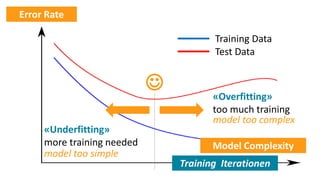

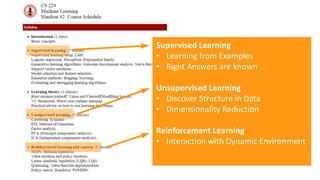



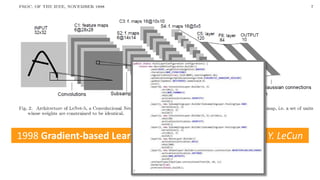
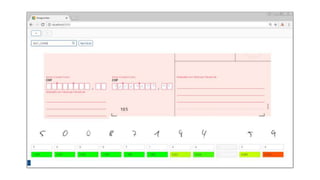



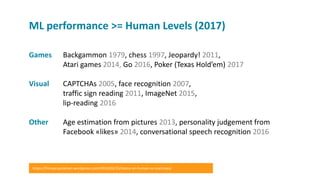




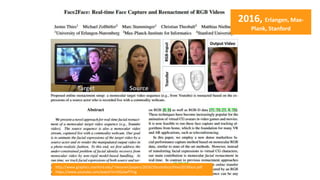





The document provides a comprehensive overview of machine learning, its concepts, and applications, including reinforcement learning techniques like Deep Q-Learning. It discusses the significance of data acquisition for successful machine learning projects and highlights various model architectures and learning types such as supervised and unsupervised learning. Additionally, it reviews the advancement of machine learning performance across multiple domains, illustrating the potential of ML to exceed human capabilities.



































































