Download to read offline











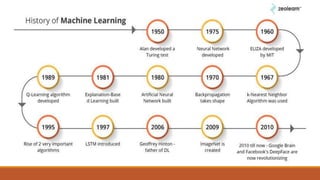
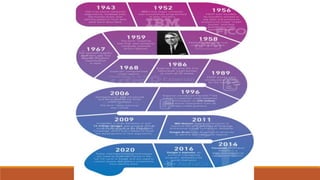






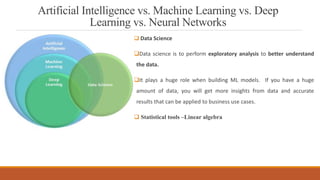
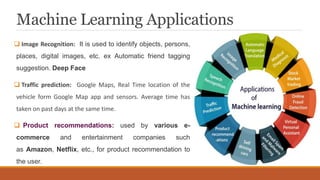

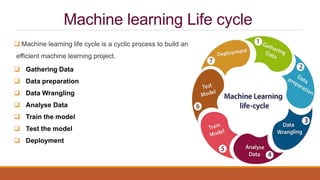





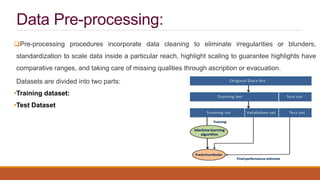


















































This document provides an introduction to machine learning, covering various topics. It defines machine learning as a branch of artificial intelligence that uses data and algorithms to enable computers to learn without being explicitly programmed. Various types of machine learning are discussed, including supervised, unsupervised, and reinforcement learning. Key concepts like hypothesis space, overfitting, evaluation metrics, and linear regression are introduced. Examples of well-posed learning problems are also provided.



















































![PPT_Template[1] AI in Healthcare seminar.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ppttemplate1seminar-250124154244-2cf31c88-thumbnail.jpg?width=640&height=640&fit=bounds)



































